

A principios de septiembre, Yandex organizó una miniconferencia privada sobre IA generativa, proporcionando una plataforma para profundizar en el mundo de la IA. Sin embargo, la conferencia arrojó revelaciones importantes, especialmente en relación con el tan esperado YandexGPT 2.
La presentación de YandexGPT 2 por parte de Yandex hizo que la comunidad de IA estuviera llena de anticipación. Los creadores de este modelo exploraron varias características distintivas, incluido un módulo especializado diseñado para buscar y proporcionar respuestas basadas en los datos de los resultados de la búsqueda. En particular, las revelaciones del equipo revelaron un aspecto sorprendente: incluso cuando se entrenó en un vasto depósito de datos internos de Yandex que abarca más de una década de trabajo en mecanismos de búsqueda neuronal, este modelo patentado aún no alcanzó al formidable GPT-4. Este importante avance subraya los notables avances logrados por GPT-4. Esta observación acentúa la supremacía de GPT-4 sobre los desarrollos propietarios y las iteraciones anteriores de código abierto.
Ampliando estos conocimientos fundamentales, Google realizó un estudio para evaluar la precisión de las respuestas de los modelos de lenguajes grandes (LLM, por sus siglas en inglés) dotados de acceso a motores de búsqueda. Aunque la noción de integrar una herramienta externa con los LLM no es nueva, Google descubrió que la complejidad radica en la evaluación y validación matizada de estos modelos. Los factores cruciales que dan forma a esta integración abarcan la selección de un tema cuidadosamente elaborado y las capacidades intrínsecas de los LLM.
Metodología de prueba LLM de Google
Un corpus seleccionado de 600 preguntas se dividió en cuatro grupos distintos. Cada grupo dio prioridad a la exactitud de los hechos, pero un grupo se destacó por incluir preguntas basadas en premisas falsas. Por ejemplo, preguntas como “¿qué escribió Trump después de que se le quitara la prohibición de Twitter?” contenía una premisa inexacta, ya que a Trump no se le había quitado la prohibición. Los tres grupos restantes introdujeron variables de obsolescencia de respuesta: nunca, rara vez y frecuentemente. En el grupo "nunca", se esperaba que los LLM respondieran únicamente de memoria, mientras que las preguntas sobre eventos recientes requerían una búsqueda en tiempo real. Cada grupo constaba de 125 preguntas.
Las preguntas se presentaron a una amplia gama de modelos. Curiosamente, las preguntas que contenían premisas falsas revelaron el dominio de GPT-4 y ChatGPT, que refutaron hábilmente dichas premisas, indicando su capacitación específica para manejar tales desafíos.
Siguió un análisis comparativo que enfrentó a ChatGPT, GPT-4, la búsqueda de Google (basada en fragmentos de texto o respuestas de la primera página) y PPLX.AI (una plataforma que aprovecha ChatGPT para agregar las respuestas de Google, dirigidas a desarrolladores) entre sí. En este contexto, los LLM proporcionaron respuestas exclusivamente de memoria.
En una observación digna de mención, la búsqueda en Google proporcionó respuestas correctas en un promedio del 40% de los casos en los cuatro grupos. La precisión de las preguntas "eternas" se situó en el 70%, mientras que las preguntas con premisas falsas se desplomaron a sólo el 11%. El rendimiento de ChatGPT alcanzó un promedio del 26%, mientras que GPT-4 alcanzó el 28%, respondiendo de manera impresionante a preguntas con premisas falsas en el 42% de los casos. PPLX.AI demostró una tasa de éxito del 52%.
El estudio profundizó integrando un enfoque novedoso. Cada pregunta provocó una búsqueda en Google y los resultados se incorporaron al mensaje. Luego, los LLM debían "leer" esta información antes de redactar sus respuestas. Esta técnica permitió el aprendizaje Few-Shot (donde se presentan ejemplos en el mensaje para guiar el modelo) y una consideración cuidadosa paso a paso antes de responder.
Los resultados fueron nada menos que fascinantes. GPT-4 exhibió una notable calificación de calidad del 77 %, respondiendo preguntas "eternas" con un 96 % de precisión y abordando preguntas con premisas falsas con una encomiable precisión del 75 %. Si bien ChatGPT ofreció métricas un poco menos impresionantes, superó tanto a PPLX.AI como a la búsqueda de Google.
Dominar el diseño de mensajes de IA: información clave de PPLX.AI y expertos de Google
La capacidad de guiar modelos de lenguajes grandes (LLM) de manera efectiva a través de un laberinto de información no es poca cosa. Sin embargo, una exploración reciente de las indicaciones de la IA ha arrojado luz sobre estrategias clave que prometen mejorar la calidad de las respuestas generadas por el LLM, ofreciendo una idea de la mecánica matizada de la asistencia de la IA.
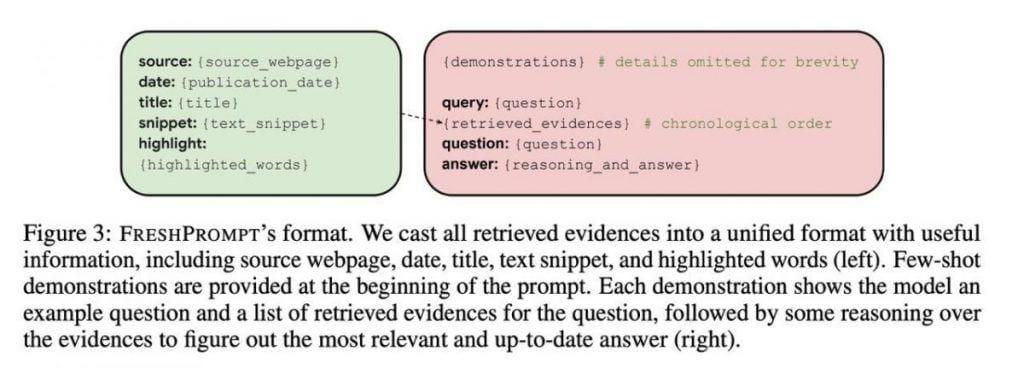
El fundamento de esta revelación se estableció mediante una cuidadosa y rápida estructuración. Este método consta de múltiples componentes y ofrece un camino claro para lograr respuestas precisas, firmemente basadas en la comprensión contextual. El aspecto inicial incluye ejemplos ilustrativos, que sirven como marcadores guía y dirigen a los LLM hacia la respuesta correcta basada en pistas contextuales.
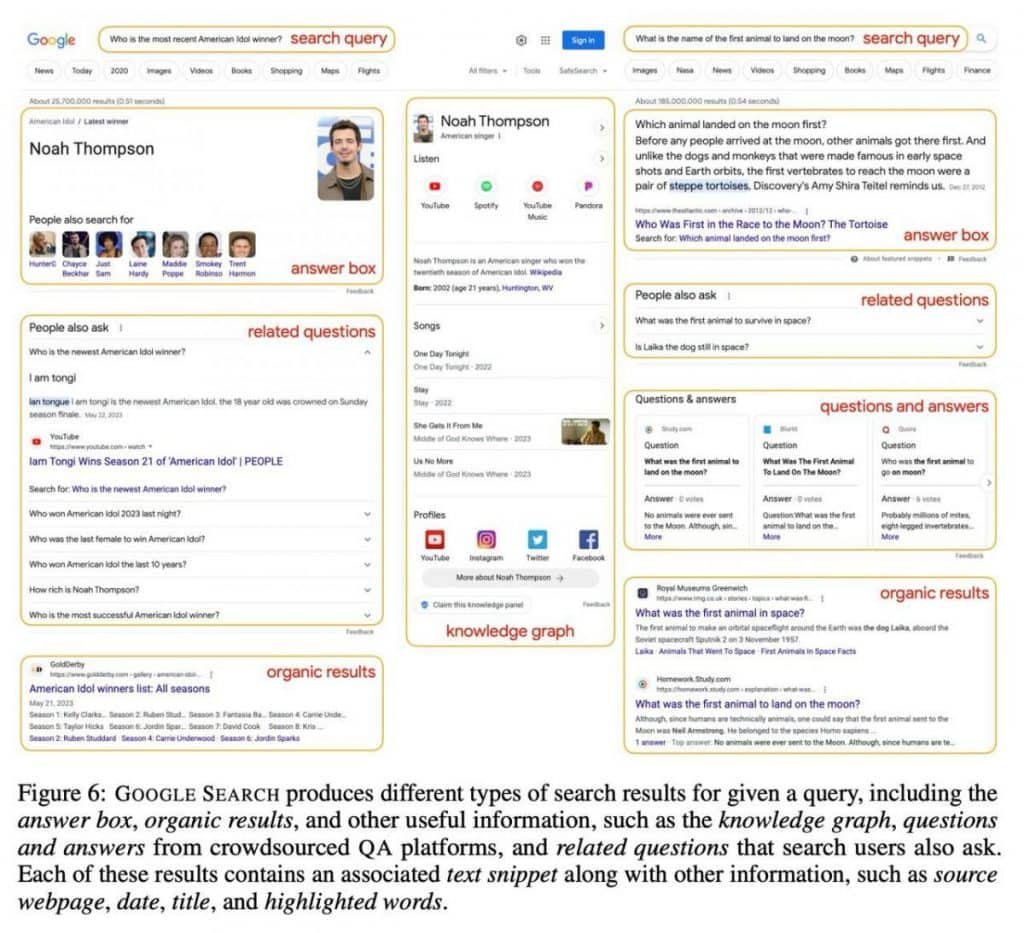
la segunda capa revela la consulta real junto con entre 10 y 15 resultados de búsqueda. Estos resultados van más allá de los simples enlaces a páginas web y abarcan una gran cantidad de información, incluido contenido textual, consultas relevantes, preguntas, respuestas y gráficos de conocimiento. Este enfoque equipa a la IA con una biblioteca de conocimientos completa.
La sofisticación de este sistema va más allá. Un descubrimiento crucial surgió al ordenar los enlaces cronológicamente dentro del mensaje, colocando las adiciones más recientes al final. Esta disposición cronológica refleja la naturaleza cambiante de la información, lo que permite al modelo discernir la línea de tiempo de los cambios. La inclusión de fechas en cada ejemplo jugó un papel fundamental para mejorar la comprensión contextual.
Si bien se espera con impaciencia el código para emplear esta estructuración matizada de mensajes, su ausencia ha llevado a los entusiastas a aventurarse a reescribir plantillas de mensajes basadas en las imágenes proporcionadas.
De esta incursión en la mecánica de las indicaciones de IA surgen varias conclusiones clave:
1) PPLX.AI, una plataforma que aprovecha ChatGPT para agregar las respuestas de Google, surgió como una opción prometedora. Incluso los empleados de Google han insinuado su superioridad.
2) La experimentación con varios elementos produjo mejoras en las métricas de respuesta. La precisión en la construcción rápida, al parecer, es un arte en sí mismo.
3) GPT-4 demuestra una competencia encomiable en el procesamiento de conjuntos extensos de noticias y textos. Si bien puede que no se caracterice como “excelente”, su calidad, incluso en escenarios noticiosos que cambian rápidamente, ronda el 60%. Se alienta a la comunidad de IA a evaluar dichas métricas de manera crítica.
4) A medida que el ecosistema de IA continúa expandiéndose, los LLM integrados en los motores de búsqueda están a punto de volverse ubicuos y atender a un amplio espectro de usuarios. La presencia de la IA en las experiencias de búsqueda cotidianas está en una trayectoria ascendente, lo que significa un cambio transformador en la forma en que se accede y procesa la información.
El enfoque multifacético ofrece una forma prometedora de obtener respuestas precisas a partir de estos sofisticados modelos de lenguaje porque incluye ejemplos ilustrativos, una consulta claramente definida y una gran cantidad de información contextual. La disposición cronológica de los vínculos dentro de las indicaciones condujo a una idea significativa, que subraya la importancia de adaptarse a la naturaleza dinámica de la información. Los LLM pueden navegar en la línea de tiempo de los cambios gracias a esta conciencia temporal, que mejora su comprensión contextual.
La publicación El análisis de Google revela información sorprendente sobre los LLM y la precisión de los motores de búsqueda apareció por primera vez en Metaverse Post.