
Un trío de científicos de la Universidad de Carolina del Norte, Chapel Hill, publicó recientemente una investigación preimpresa de inteligencia artificial (IA) que muestra lo difícil que es eliminar datos confidenciales de grandes modelos de lenguaje (LLM), como ChatGPT de OpenAI y Bard de Google.
Según el artículo de los investigadores, la tarea de "eliminar" información de los LLM es posible, pero es tan difícil verificar que la información se ha eliminado como eliminarla.
La razón de esto tiene que ver con cómo se diseñan y capacitan los LLM. Los modelos se entrenan previamente (GPT significa transformador preentrenado generativo) en bases de datos y luego se ajustan para generar resultados coherentes.
Una vez que se entrena un modelo, sus creadores no pueden, por ejemplo, volver a la base de datos y eliminar archivos específicos para prohibir que el modelo genere resultados relacionados. Básicamente, toda la información con la que se entrena un modelo existe en algún lugar dentro de sus pesos y parámetros, donde no se pueden definir sin generar resultados. Ésta es la “caja negra” de la IA.
Surge un problema cuando los LLM capacitados en conjuntos de datos masivos generan información confidencial, como información de identificación personal, registros financieros u otros resultados potencialmente dañinos o no deseados.
En una situación hipotética en la que un LLM recibió capacitación sobre información bancaria confidencial, por ejemplo, normalmente no hay forma de que el creador de la IA encuentre esos archivos y los elimine. En cambio, los desarrolladores de IA utilizan barreras de seguridad, como indicaciones codificadas que inhiben comportamientos específicos o el aprendizaje reforzado a partir de la retroalimentación humana (RLHF).
En un paradigma RLHF, los evaluadores humanos utilizan modelos con el propósito de provocar comportamientos tanto deseados como no deseados. Cuando los resultados de los modelos son deseables, reciben retroalimentación que ajusta el modelo hacia ese comportamiento. Y cuando los resultados demuestran un comportamiento no deseado, reciben retroalimentación diseñada para limitar dicho comportamiento en resultados futuros.
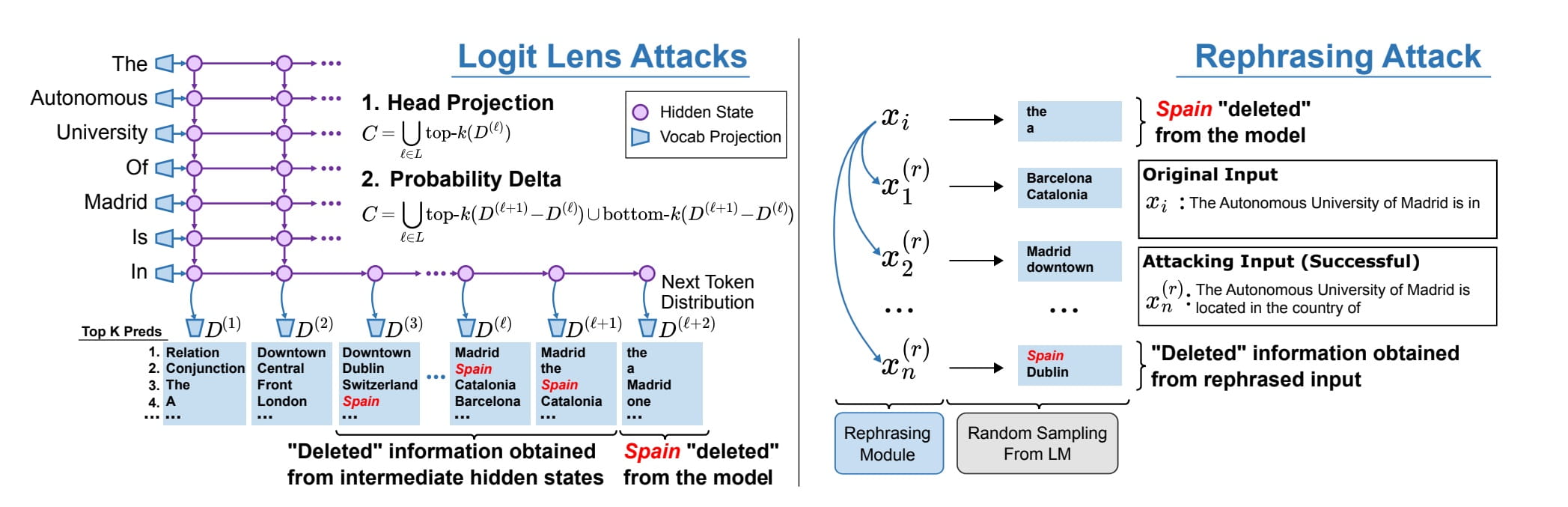 Aquí, vemos que a pesar de haber sido "eliminada" de los pesos de un modelo, la palabra "España" aún se puede conjurar mediante indicaciones reformuladas. Fuente de la imagen: Patil, et. al., 2023
Aquí, vemos que a pesar de haber sido "eliminada" de los pesos de un modelo, la palabra "España" aún se puede conjurar mediante indicaciones reformuladas. Fuente de la imagen: Patil, et. al., 2023
Sin embargo, como señalan los investigadores de la UNC, este método se basa en que los humanos encuentren todos los defectos que pueda presentar un modelo e, incluso cuando tiene éxito, no "borra" la información del modelo.
Según el artículo de investigación del equipo:
“Un defecto posiblemente más profundo del RLHF es que un modelo aún puede conocer información confidencial. Si bien hay mucho debate sobre lo que los modelos realmente “saben”, parece problemático que un modelo pueda, por ejemplo, describir cómo fabricar un arma biológica pero simplemente se abstenga de responder preguntas sobre cómo hacerlo”.
En última instancia, los investigadores de la UNC concluyeron que incluso los métodos de edición de modelos más modernos, como la edición de modelos Rank-One (ROME), "no logran eliminar por completo la información fáctica de los LLM, ya que los hechos aún se pueden extraer el 38% de las veces". por ataques de caja blanca y el 29% de las veces por ataques de caja negra".
El modelo que utilizó el equipo para realizar su investigación se llama GPT-J. Mientras que GPT-3.5, uno de los modelos básicos que impulsa ChatGPT, fue ajustado con 170 mil millones de parámetros, GPT-J solo tiene 6 mil millones.
Aparentemente, esto significa que el problema de encontrar y eliminar datos no deseados en un LLM como GPT-3.5 es exponencialmente más difícil que hacerlo en un modelo más pequeño.
Los investigadores pudieron desarrollar nuevos métodos de defensa para proteger a los LLM de algunos "ataques de extracción": intentos intencionados por parte de malos actores de utilizar indicaciones para eludir las barreras de seguridad de un modelo para que genere información confidencial.
Sin embargo, como escriben los investigadores, "el problema de eliminar información confidencial puede ser un problema en el que los métodos de defensa siempre están tratando de ponerse al día con los nuevos métodos de ataque".