

Título original: "De GPT-1 a GPT-4, observe el ascenso de ChatGPT"
Autor original: Notas de investigación del conejo alfa
¿Qué es ChatGPT?

¿Qué es ChatGPT?
Recientemente, OpenAI lanzó ChatGPT, un modelo que puede interactuar de forma conversacional. Debido a su inteligencia, ha sido bien recibido por muchos usuarios. ChatGPT también es un pariente de InstructGPT lanzado anteriormente por OpenAI. El modelo ChatGPT se entrena utilizando RLHF (aprendizaje reforzado con retroalimentación humana). Quizás la llegada de ChatGPT sea también el preludio antes del lanzamiento oficial de GPT-4 de OpenAI.
¿Qué es GPT? De GPT-1 a GPT-3
Transformador generativo preentrenado (GPT) es un modelo de aprendizaje profundo de generación de texto entrenado con datos disponibles en Internet. Se utiliza para responder preguntas, resumir textos, traducir automáticamente, clasificar, generar código e IA conversacional.
En 2018 nació GPT-1, que también fue el primer año de modelos de preentrenamiento para PNL (procesamiento del lenguaje natural). En términos de rendimiento, GPT-1 tiene cierta capacidad de generalización y puede usarse en tareas de PNL que no tienen nada que ver con tareas de supervisión. Las tareas comunes incluyen:
Razonamiento en lenguaje natural: determinar la relación entre dos oraciones (contención, contradicción, neutralidad)
Preguntas y respuestas y razonamiento de sentido común: ingrese un artículo y varias respuestas, y genere la precisión de la respuesta
Reconocimiento de similitud semántica: determine si dos oraciones están relacionadas semánticamente
Categoría: determine a qué categoría pertenece el texto de entrada
Aunque GPT-1 tiene algunos efectos en las tareas no ajustadas, su capacidad de generalización es mucho menor que la de las tareas supervisadas ajustadas. Por lo tanto, GPT-1 solo puede considerarse una herramienta de comprensión del lenguaje bastante buena en lugar de una IA conversacional.
GPT-2 también llegó según lo previsto en 2019. Sin embargo, GPT-2 no llevó a cabo demasiadas innovaciones estructurales y diseños en la red original. Solo utilizó más parámetros de red y un conjunto de datos más grande: el modelo máximo total tiene 48 capas. y 1.500 millones de parámetros. El objetivo de aprendizaje utiliza un modelo de preentrenamiento no supervisado para realizar tareas supervisadas. En términos de rendimiento, además de las capacidades de comprensión, GPT-2 ha demostrado por primera vez un gran talento en generación: leer resúmenes, chatear, seguir escribiendo, inventar historias e incluso generar noticias falsas, correos electrónicos de phishing o juegos de roles. en línea No es un problema. Después de "hacerse más grande", GPT-2 demostró sus capacidades universales y poderosas y logró el mejor rendimiento en ese momento en múltiples tareas específicas de modelado de lenguaje.
Después de eso, apareció GPT-3 como modelo no supervisado (ahora a menudo llamado modelo autosupervisado), que casi puede completar la mayoría de las tareas del procesamiento del lenguaje natural, como la búsqueda orientada a problemas, la comprensión lectora, la inferencia semántica y la traducción automática. , generación de artículos y preguntas y respuestas automáticas, etc. Además, el modelo funciona bien en muchas tareas, como alcanzar el nivel actual de última generación en tareas de traducción automática francés-inglés y alemán-inglés. Los artículos generados automáticamente son casi imposibles de distinguir entre humanos y máquinas (solo). 52% de precisión), comparable a las adivinanzas aleatorias), y lo que es aún más sorprendente es que logra casi el 100% de precisión en tareas de suma y resta de dos dígitos, e incluso puede generar código automáticamente según la descripción de la tarea. Un modelo no supervisado tiene muchas funciones y buenos efectos, y parece que la gente ve la esperanza de la inteligencia artificial general. Esta puede ser la razón principal por la que GPT-3 tiene un impacto tan grande.
¿Qué es exactamente el modelo GPT-3?
De hecho, GPT-3 es un modelo de lenguaje estadístico simple. Desde la perspectiva del aprendizaje automático, los modelos de lenguaje modelan la distribución de probabilidad de secuencias de palabras, es decir, utilizan los fragmentos que se han dicho como condiciones para predecir la distribución de probabilidad de diferentes palabras que aparecen en el momento siguiente. Por un lado, el modelo de lenguaje puede medir el grado en que una oración se ajusta a la gramática del lenguaje (por ejemplo, midiendo si la respuesta generada automáticamente por el sistema de diálogo persona-computadora es natural y fluida), y también puede usarse predecir y generar nuevas oraciones. Por ejemplo, para un clip "Son las 12 del mediodía, vayamos juntos a un restaurante", el modelo de lenguaje puede predecir las palabras que pueden aparecer después de "restaurante". Un modelo de lenguaje general predecirá que la siguiente palabra es "comer". Un modelo de lenguaje potente puede capturar la información del tiempo y predecir la palabra "almorzar" que se ajuste al contexto.
Por lo general, si un modelo de lenguaje es poderoso depende principalmente de dos puntos: primero, si el modelo puede hacer uso de toda la información del contexto histórico, si no puede capturar la información semántica de largo alcance de las "12 del mediodía", el El modelo de lenguaje será casi incapaz de predecir la próxima palabra "almorzar". En segundo lugar, también depende de si existe un contexto histórico suficientemente rico para que el modelo aprenda, es decir, si el corpus de entrenamiento es lo suficientemente rico. Dado que el modelo de lenguaje es un aprendizaje autosupervisado, el objetivo de optimización es maximizar la probabilidad del texto visto en el modelo de lenguaje, por lo que cualquier texto puede usarse como datos de entrenamiento sin etiquetado.
Debido al mayor rendimiento del GPT-3 y a una cantidad significativamente mayor de parámetros, contiene más texto temático, lo que obviamente es mejor que el GPT-2 de la generación anterior. Como la red neuronal densa más grande disponible actualmente, GPT-3 puede convertir descripciones de páginas web en códigos correspondientes, imitar narrativas humanas, crear poemas personalizados, generar guiones de juegos e incluso imitar a filósofos fallecidos, prediciendo el verdadero significado de la vida. Y GPT-3 no requiere ajustes finos, solo requiere unas pocas muestras del tipo de salida (una pequeña cantidad de aprendizaje) para resolver problemas gramaticales difíciles. Se puede decir que GPT-3 parece haber satisfecho toda nuestra imaginación de expertos en idiomas.
Nota: Lo anterior se refiere principalmente a los siguientes artículos:
1. GPT 4 está a punto de ser lanzado y es comparable al cerebro humano. ¡Muchos grandes actores de la industria no pueden quedarse quietos! -Xu Jiecheng, Yun Zhao -Cuenta pública 51 CTO Technology Stack- 2022-11-24 18: 08
2. ¡Responda su curiosidad sobre GPT-3 en un artículo! ¿Qué es GPT-3? ¿Por qué es tan excelente? -Instituto de Automatización Zhang Jiajun, Academia de Ciencias de China Publicado en Beijing el 11/11/2020 17:25
3.The Batch: 329 | InstructGPT, un modelo de lenguaje más amigable y gentil: cuenta pública DeeplearningAI-2022-02-07 12: 30
¿Cuáles son los problemas con GPT-3?
Pero GTP-3 no es perfecto. Uno de los principales problemas que más preocupa a la gente en materia de inteligencia artificial es que los chatbots y las herramientas de generación de texto probablemente aprendan todos los textos de Internet de forma indiscriminada y con calidad, a su vez incorrectos y maliciosamente ofensivos. o incluso se produce un lenguaje ofensivo, lo que afectará completamente su próxima aplicación.
OpenAI también ha propuesto que en un futuro próximo se lanzará un GPT-4 más potente:
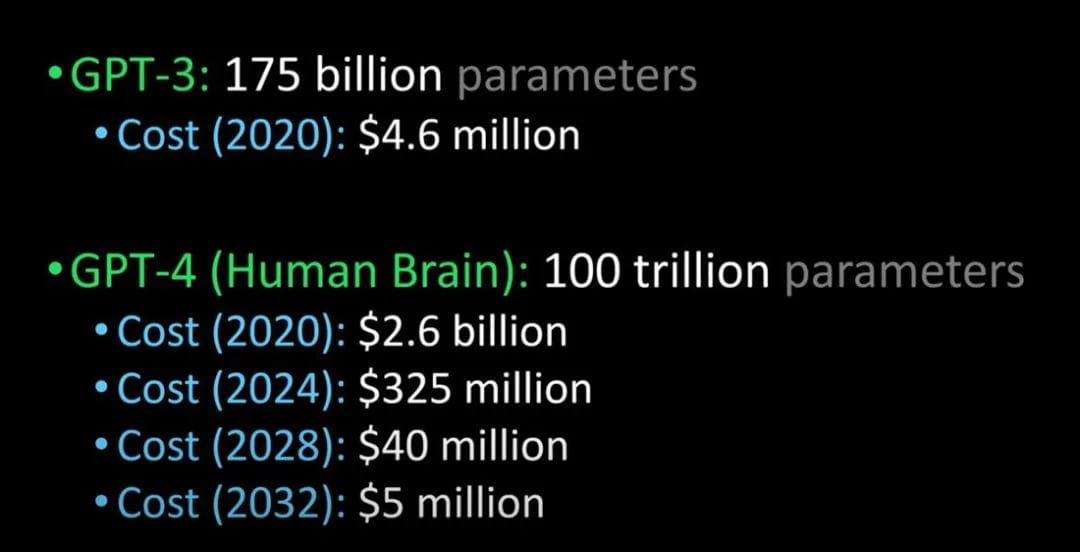
Comparando GPT-3 con GPT-4 y el cerebro humano (Crédito de la imagen: Lex Fridman @youtube)
Se dice que GPT-4 se lanzará el próximo año. Puede pasar la prueba de Turing y ser tan avanzado que no se puede distinguir de los humanos. Además, el costo para las empresas de introducir GPT-4 también se reducirá considerablemente.
ChatGP e InstructGPT
ChatGPT e InstructGPT
Cuando hablamos de Chatgpt, tenemos que hablar de su "predecesor" InstructGPT.
A principios de 2022, OpenAI lanzó InstructGPT; en esta investigación, en comparación con GPT-3, OpenAI utilizó la investigación de alineación para entrenar un modelo de lenguaje que es más realista, más inofensivo y sigue mejor las intenciones del usuario. InstructGPT es un nuevo y perfeccionado. Versión de GPT-3 que minimiza la producción dañina, poco realista y sesgada.
¿Cómo funciona InstructGPT?
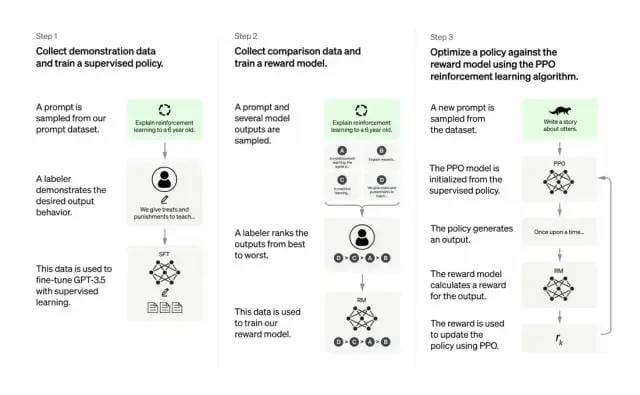
Los desarrolladores hacen esto combinando aprendizaje supervisado + aprendizaje reforzado a partir de comentarios humanos. Mejorar la calidad de salida de GPT-3. En este tipo de aprendizaje, los humanos clasifican los resultados potenciales de un modelo; los algoritmos de aprendizaje por refuerzo recompensan los modelos que producen material similar al resultado de alto nivel.
El conjunto de datos de entrenamiento comienza con la creación de indicaciones, algunas de las cuales se basan en aportes de los usuarios de GPT-3, como “Cuéntame una historia sobre una rana” o “Explica el alunizaje a un niño de 6 años en unas pocas oraciones”. "
Los desarrolladores dividieron el mensaje en tres partes y crearon respuestas para cada parte de manera diferente:
Los escritores humanos responden al primer conjunto de indicaciones. Los desarrolladores ajustaron un GPT-3 entrenado y lo convirtieron en InstructGPT para generar respuestas existentes para cada mensaje.
El siguiente paso es entrenar un modelo para recompensar las mejores respuestas con recompensas más altas. Para el segundo conjunto de indicaciones, el modelo optimizado genera múltiples respuestas. Los evaluadores humanos clasifican cada respuesta. Dada una indicación y dos respuestas, un modelo de recompensa (otro GPT-3 previamente entrenado) aprendió a calcular una recompensa más alta para la respuesta con calificación alta y una recompensa más baja para la respuesta con calificación baja.
Los desarrolladores perfeccionaron aún más el modelo de lenguaje utilizando un tercer conjunto de sugerencias y el método de aprendizaje por refuerzo de optimización de políticas próximas (PPO). Cuando se da una indicación, el modelo de lenguaje genera una respuesta y el modelo de recompensa la recompensa en consecuencia. PPO utiliza recompensas para actualizar el modelo de lenguaje.
Referencia para este párrafo: The Batch: 329 | InstructGPT, un modelo de lenguaje más amigable y gentil: cuenta pública DeeplearningAI- 2022-02-07 12: 30
¿Qué es importante? La esencia es que la inteligencia artificial debe ser una inteligencia artificial responsable.
El modelo de lenguaje de OpenAI puede ayudar en los campos de la educación, los terapeutas virtuales, las ayudas para la escritura, los juegos de rol, etc. En estos campos, la existencia de prejuicios sociales, desinformación e información tóxica es más problemática, y los sistemas que pueden evitar estos defectos pueden ser más capaz.
¿Cuáles son las diferencias entre los procesos de formación de Chatgpt e InstructGPT?
En general, Chatgpt, al igual que InstructGPT anterior, se entrena utilizando RLHF (aprendizaje por refuerzo a partir de retroalimentación humana). La diferencia es cómo se configuran (y se recopilan) los datos para el entrenamiento. (Explicación aquí: el modelo InstructGPT anterior daba un resultado para una entrada y luego lo comparaba con los datos de entrenamiento. Sí, hubo recompensas y no penalizaciones; el Chatgpt actual es una entrada y el modelo proporciona múltiples resultados, y luego las personas dar Esta clasificación de los resultados de salida permite al modelo clasificar estos resultados desde "más parecidos a los humanos" hasta "sin sentido", lo que permite que el modelo aprenda la forma en que los humanos clasifican. Esta estrategia se llama aprendizaje supervisado. Gracias al Dr. Zhang Zijie por. este párrafo)
¿Cuáles son las limitaciones de ChatGPT?
como sigue:
a) Durante la fase de capacitación de aprendizaje por refuerzo (RL), no existe una fuente específica de verdad ni respuestas estándar para sus preguntas.
b) El modelo está entrenado para ser más cauteloso y puede rechazar respuestas (para evitar falsos positivos de las indicaciones).
c) La capacitación supervisada puede inducir a error o sesgar el modelo hacia el conocimiento de la respuesta ideal, en lugar de que el modelo genere un conjunto aleatorio de respuestas y solo los revisores humanos elijan las respuestas buenas o mejor clasificadas.
Nota: ChatGPT es sensible a la redacción. , a veces el modelo termina no respondiendo a una frase, pero con un ligero retoque en la pregunta/frase, termina respondiendo correctamente. Los capacitadores tienden a preferir respuestas más largas porque pueden parecer más completas, lo que lleva a una tendencia a respuestas más largas y al uso excesivo de ciertas frases en el modelo. Si la sugerencia o pregunta inicial es ambigua, el modelo no solicitará una aclaración adecuada.
Las limitaciones autoidentificadas de ChatGPT son las siguientes.
Respuestas que suenan plausibles pero incorrectas:
a) No existe una fuente real de verdad para solucionar este problema durante la fase de capacitación de Aprendizaje por refuerzo (RL).
b) El modelo de entrenamiento para que sea más cauteloso puede negarse a responder por error (falso positivo de indicaciones problemáticas).
c) La capacitación supervisada puede inducir a error o sesgar: el modelo tiende a conocer la respuesta ideal en lugar de que el modelo genere un conjunto aleatorio de respuestas y solo los revisores humanos seleccionan una respuesta buena o altamente calificada. ChatGPT es sensible a la redacción. A veces el modelo termina sin respuesta para una frase, pero con un ligero ajuste en la pregunta/frase, termina respondiéndola correctamente.
Los capacitadores prefieren respuestas más largas que puedan parecer más completas, lo que genera un sesgo hacia respuestas detalladas y el uso excesivo de ciertas frases. El modelo no pide aclaraciones de manera apropiada si la pregunta o mensaje inicial es ambiguo. Una capa de seguridad para rechazar solicitudes inapropiadas a través de la API de moderación ha sido implementado. Sin embargo, todavía podemos esperar respuestas falsas negativas y positivas.
referencias:
1.https://medium.com/inkwater-atlas/chatgpt-the-new-frontier-of-artificial-intelligence-9 aee 81287677
2.https://pub.towardsai.net/openai-debuts-chatgpt-50 dd 611278 a 4
3.https://openai.com/blog/chatgpt/
4. GPT 4 está a punto de ser lanzado y es comparable al cerebro humano. ¡Muchos grandes actores de la industria no pueden quedarse quietos! -Xu Jiecheng, Yun Zhao -Cuenta pública 51 CTO Technology Stack- 2022-11-24 18: 08
5. ¡Responda su curiosidad sobre GPT-3 en un artículo! ¿Qué es GPT-3? ¿Por qué es tan excelente? -Instituto de Automatización Zhang Jiajun, Academia de Ciencias de China Publicado en Beijing el 11/11/2020 17:25
6.The Batch: 329 | InstructGPT, un modelo de lenguaje más amigable y gentil: cuenta pública DeeplearningAI-2022-02-07 12: 30