
Conclusiones principales
Binance aprovecha la gestión de la capacidad para los aumentos de tráfico no planificados causados por la alta volatilidad, garantizando una infraestructura y recursos informáticos adecuados y oportunos para las demandas comerciales.
Pruebas de carga de Binance en el entorno de producción (en lugar de un entorno de prueba) para obtener puntos de referencia de servicio precisos. Este método ayuda a validar que nuestra asignación de recursos es adecuada para atender una carga definida.
La infraestructura de Binance maneja grandes cantidades de tráfico y mantener un servicio en el que los usuarios puedan confiar requiere una gestión de capacidad adecuada y pruebas de carga automáticas.

¿Por qué Binance necesita un proceso de gestión de capacidad especializado?
La gestión de la capacidad es la base de la estabilidad del sistema. Implica dimensionar correctamente los recursos de infraestructura y aplicaciones con las demandas comerciales actuales y futuras al costo correcto. Para ayudar a lograr este objetivo, creamos herramientas y canales de administración de capacidad para evitar la sobrecarga y ayudar a las empresas a brindar una experiencia de usuario fluida.
Los mercados de criptomonedas suelen afrontar períodos de volatilidad más regulares que los mercados financieros tradicionales. Esto significa que el sistema de Binance debe soportar este aumento de tráfico de vez en cuando a medida que los usuarios reaccionan a los movimientos del mercado. Con una gestión adecuada de la capacidad, mantenemos la capacidad adecuada para la demanda comercial general y estos escenarios de aumento de tráfico. Este punto clave es exactamente lo que hace que los procesos de gestión de capacidad de Binance sean únicos y desafiantes.
Veamos los factores que a menudo obstaculizan el proceso y provocan que el servicio sea lento o no esté disponible. En primer lugar, tenemos la sobrecarga, normalmente provocada por un aumento repentino del tráfico. Por ejemplo, esto podría deberse a un evento de marketing, una notificación automática o incluso un ataque DDoS (denegación de servicio distribuido).
El aumento de tráfico y la capacidad insuficiente afectan la funcionalidad del sistema como:
El servicio asume cada vez más trabajo.
El tiempo de respuesta aumenta hasta el punto de que no se puede responder a ninguna solicitud dentro del tiempo de espera del cliente. Esta degradación suele ocurrir debido a la saturación de recursos (CPU, memoria, IO, red, etc.) o pausas prolongadas de GC en el propio servicio o sus dependencias.
El resultado es que el servicio no podrá procesar las solicitudes con prontitud.
Rompiendo el proceso
Ahora que hemos analizado el principio general de gestión de capacidad, veamos cómo Binance aplica esto a su negocio. A continuación presentamos un vistazo a la arquitectura de nuestro sistema de gestión de capacidad con algunos flujos de trabajo clave.
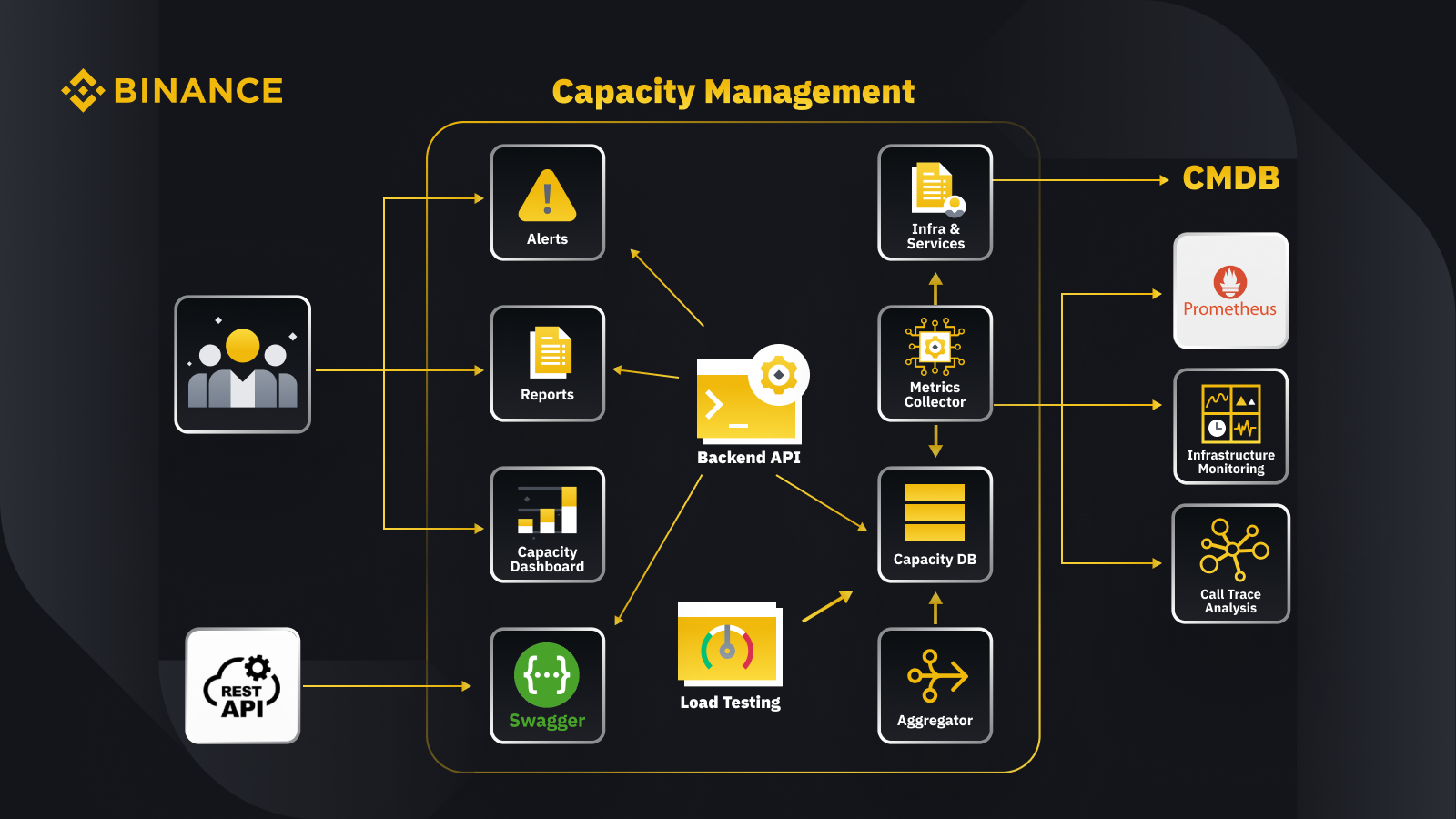
Al obtener datos de la base de datos de gestión de configuración (CMDB), generamos las configuraciones de infraestructura y servicios. Los elementos de estas configuraciones son los objetos de gestión de capacidad.
El recopilador de métricas obtiene métricas de capacidad de Prometheus para los datos de la capa de servicios y negocios, Monitoreo de infraestructura para las métricas de la capa de recursos y el sistema de análisis de seguimiento de llamadas para obtener información de seguimiento. El recopilador de métricas almacena los datos en la base de datos de capacidad (CDB).
El sistema de prueba de carga realiza pruebas de estrés en los servicios y almacena los datos de referencia en el CDB.
El agregador obtiene los datos de capacidad de CDB y los agrega para dimensiones diarias y máximas históricas (ATH). Después de la agregación, vuelve a escribir los datos agregados en el CDB.
Al procesar los datos del CDB, la API de backend proporciona interfaces para el panel de capacidad, alertas e informes, así como el resto de la API y los datos de capacidad relacionados para la integración.
Las partes interesadas obtienen información sobre la capacidad a través del panel de capacidad, alertas e informes. También pueden utilizar otros sistemas relacionados, incluido el seguimiento de los datos de capacidad de los servicios con la API de descanso proporcionada por el sistema de gestión de capacidad con Swagger.
Estrategia
Nuestra estrategia de planificación y gestión de capacidad se basa en el procesamiento impulsado por los picos. El procesamiento impulsado por picos es la carga de trabajo que experimentan los recursos de un servicio (servidores web, bases de datos, etc.) durante el uso pico.
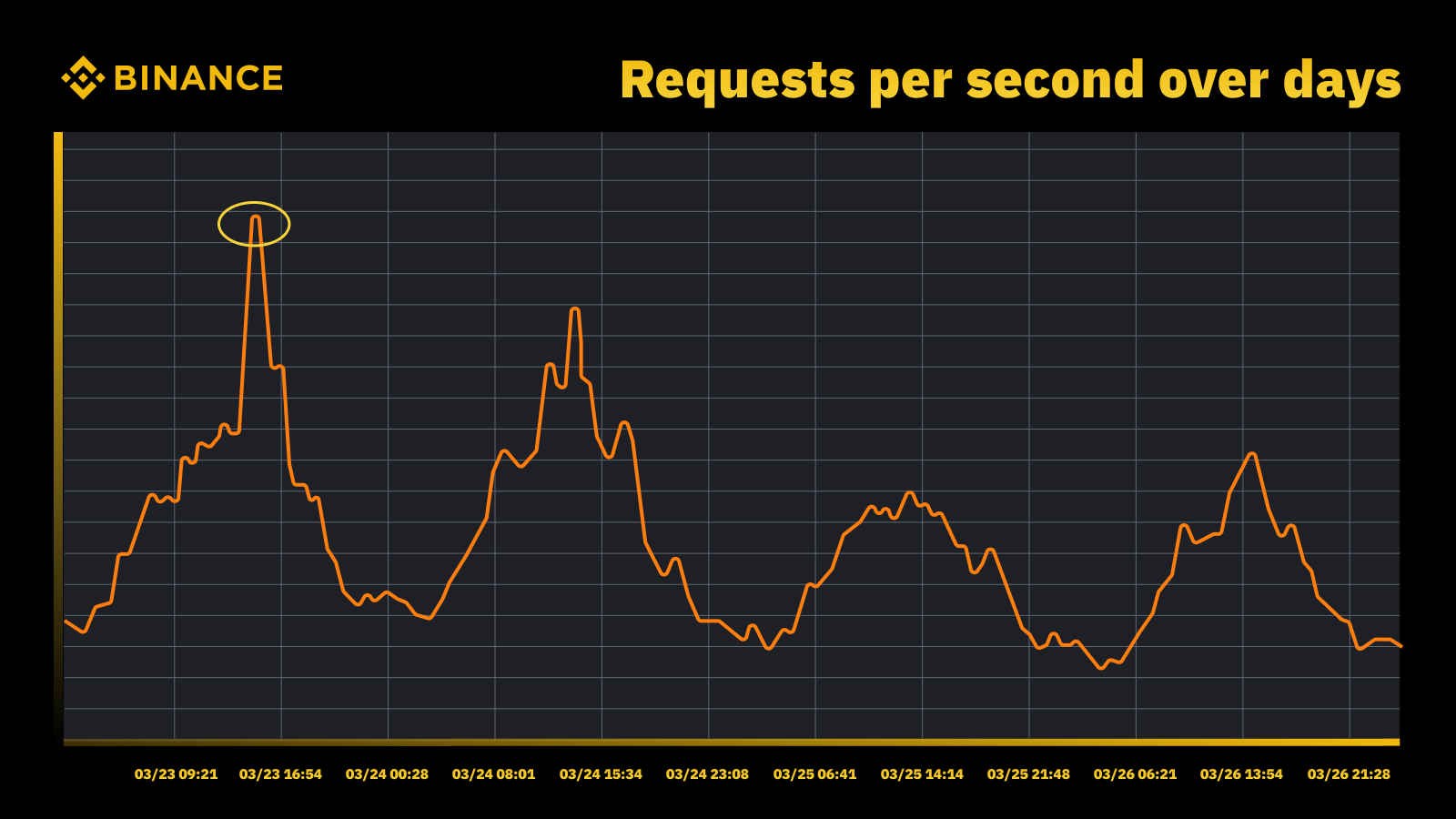
Aumento del tráfico cuando la Fed subió la tasa en marzo de 2023
Analizamos los picos periódicos y los utilizamos para impulsar la trayectoria de capacidad. Al igual que con cualquier recurso impulsado por picos, queremos saber cuándo ocurren los picos y luego explorar qué sucede realmente durante esos ciclos.
Otra cosa importante que consideramos además de prevenir la sobrecarga es el escalado automático. El escalado automático maneja la sobrecarga aumentando dinámicamente la capacidad con más instancias del servicio. Luego, el exceso de tráfico se distribuye y el tráfico que maneja una única instancia del servicio (o dependencia) sigue siendo manejable.
El escalado automático tiene su lugar, pero no logra manejar situaciones de sobrecarga por sí solo. Por lo general, no puede reaccionar lo suficientemente rápido ante un aumento repentino del tráfico y solo funciona mejor cuando hay un aumento gradual.
Medición
La medición juega un papel crucial en el trabajo de gestión de capacidad de Binance, y la recopilación de datos es nuestro primer paso de medición. Con base en los estándares de la Biblioteca de Infraestructura de Tecnología de la Información (ITIL), recopilamos datos para su medición en los subprocesos de gestión de capacidad, a saber:
Recurso: consumo de recursos de la infraestructura de TI impulsado por el uso de aplicaciones/servicios. Se centra en métricas de rendimiento interno de los recursos informáticos físicos y virtuales, incluida la CPU del servidor, la memoria, el almacenamiento en disco, el ancho de banda de la red, etc.
Servicio. Las medidas de rendimiento a nivel de aplicación, SLA, latencia y rendimiento que surgen de las actividades comerciales. Se centra en métricas de rendimiento externas basadas en cómo los usuarios perciben el servicio, incluida la latencia del servicio, el rendimiento, los picos, etc.
Negocio. Recopila datos que miden las actividades comerciales procesadas por la aplicación de destino, incluidos pedidos, registro de usuarios, pagos, etc.
La gestión de la capacidad basada únicamente en la utilización de los recursos de la infraestructura dará lugar a una planificación inexacta. Esto se debe a que es posible que no represente los volúmenes de negocios y el rendimiento reales que impulsan nuestra capacidad de infraestructura.
Los eventos programados brindan un excelente lugar para discutir esto más a fondo. Asista al Watch Web Summit 2022 en Binance Live para compartir hasta 15,000 BUSD en la campaña Crypto Box Rewards. Además de las métricas subyacentes de la capa de servicios y recursos, también necesitábamos considerar los volúmenes de negocio. Aquí basamos la planificación de la capacidad en métricas comerciales como la cantidad estimada de espectadores de transmisiones en vivo, las solicitudes máximas en vuelo para una Crypto Box, la latencia de un extremo a otro y otros factores.
Después de recopilar datos, nuestros procesos de gestión de capacidad agregan y resumen los numerosos puntos de datos recopilados en comparación con un controlador de capacidad específico. El valor agregado de una métrica es un valor único que se puede utilizar en alertas de capacidad, informes y otras funciones relacionadas con la capacidad.
Podemos aplicar varios métodos de agregación de datos a puntos de datos periódicos, como suma, promedio, mediana, mínimo, máximo, percentil y máximo histórico (ATH).

Nuestro método elegido determina nuestros resultados del proceso de gestión de capacidad y las decisiones resultantes. Seleccionamos diferentes métodos basados en diferentes escenarios. Por ejemplo, utilizamos el método máximo para servicios críticos y puntos de datos relacionados. Para registrar el mayor tráfico, utilizamos el método ATH.
Para diferentes casos de uso, utilizamos diferentes tipos de granularidad para la agregación de datos. En la mayoría de los casos, utilizamos minutos, horas, días o ATH.
Con granularidad minuciosa, medimos la carga de trabajo de un servicio para alertar oportunamente de sobrecarga.
Usamos datos agregados por hora para acumular datos diarios y agregamos los datos por hora para registrar el pico diario.
Normalmente utilizamos datos diarios para informes de capacidad y aprovechamos los datos ATH para el modelado y la planificación de capacidad.
Una de las métricas centrales de la gestión de la capacidad es la evaluación comparativa de servicios. Esto nos ayuda a medir con precisión el rendimiento y la capacidad del servicio. Obtenemos el punto de referencia del servicio con pruebas de carga y profundizaremos en esto con más detalle más adelante.
Gestión de capacidad basada en prioridad
Hasta ahora, hemos visto cómo recopilamos métricas de capacidad y agregamos datos en diferentes tipos de granularidad. Otra área crítica para discutir es la prioridad, que es útil en el contexto de alertas y informes de capacidad. Después de clasificar los activos de TI, se priorizan el uso limitado de la infraestructura y los recursos informáticos y se asignan primero a los servicios y actividades críticos.
Puede haber varias formas de definir la criticidad del servicio y de la solicitud. Una referencia útil es Google. En el libro SRE. Definen los niveles de criticidad como CRITICAL_PLUS, CRITICAL, SHEDDABLE_PLUS, etc. De manera similar, definimos múltiples niveles de prioridad como P0, P1, P2, etc.
Definimos los niveles de prioridad de la siguiente manera:
P0: Para los servicios y solicitudes más críticos, aquellos que tendrán un impacto grave y visible para el usuario si fallan.
P1: Para aquellos servicios y solicitudes que resultarán en un impacto visible para el usuario, pero el impacto es menor que los de P0. Se espera que los servicios P0 y P1 cuenten con capacidad suficiente.
P2: esta es la prioridad predeterminada para trabajos por lotes y trabajos sin conexión. Es posible que estos servicios y solicitudes no tengan un impacto visible para el usuario si no están parcialmente disponibles.
¿Qué son las pruebas de carga y por qué las utilizamos en un entorno de producción?
La prueba de carga es un proceso de prueba de software no funcional en el que se prueba el rendimiento de una aplicación bajo una carga de trabajo específica. Esto ayuda a determinar cómo se comporta la aplicación cuando varios usuarios finales acceden a ella simultáneamente.
En Binance, creamos una solución que nos permite ejecutar pruebas de carga en producción. Normalmente, las pruebas de carga se ejecutan en un entorno de prueba, pero no pudimos usar esta opción según nuestros objetivos generales de administración de capacidad. Las pruebas de carga en un entorno de producción nos permitieron:
Recopile un punto de referencia preciso de nuestros servicios en condiciones de carga de la vida real.
Incrementar la confianza en el sistema y su confiabilidad y desempeño.
Identifique cuellos de botella en el sistema antes de que ocurran en el entorno de producción.
Habilite el monitoreo continuo de los entornos de producción.
Habilite la gestión proactiva de la capacidad con ciclos de prueba normalizados que se realizan periódicamente.
A continuación puede ver nuestro marco de pruebas de carga con algunas conclusiones clave:

El marco de microservicios de Binance tiene una capa base para admitir el enrutamiento del tráfico basado en configuraciones y banderas, lo cual es esencial para nuestro enfoque TIP.
Se adopta el análisis canary automatizado (ACA) para evaluar la instancia que estamos probando. Compara métricas clave recopiladas en el sistema de monitoreo, por lo que podemos pausar/terminar la prueba si ocurre algún problema inesperado para minimizar el impacto en el usuario.
Los puntos de referencia y las métricas se recopilan durante las pruebas de carga para generar información sobre los comportamientos y el rendimiento de las aplicaciones.
Las API están expuestas para compartir datos valiosos de rendimiento en varios escenarios, por ejemplo, gestión de capacidad y control de calidad. Esto ayuda a construir un ecosistema abierto.
Creamos flujos de trabajo de automatización para orquestar todos los pasos y puntos de control desde una perspectiva de prueba de un extremo a otro. También brindamos la flexibilidad de integrarnos con otros sistemas, como el portal de operación y canalización de CI/CD.
Nuestro enfoque de pruebas en producción (TIP)
Un enfoque tradicional de prueba de rendimiento (ejecutar pruebas en un entorno de prueba con tráfico simulado o reflejado) proporciona algunos beneficios. Sin embargo, implementar un entorno de ensayo similar a una producción tiene más inconvenientes en nuestro contexto:
Casi duplica el costo de la infraestructura y los esfuerzos de mantenimiento.
Es increíblemente complejo lograr que todo el proceso funcione de un extremo a otro en producción, especialmente en un entorno de microservicios a gran escala en múltiples unidades de negocios.
Agrega más riesgos de seguridad y privacidad de los datos ya que, inevitablemente, es posible que necesitemos duplicar datos en la puesta en escena.
El tráfico simulado nunca replicará lo que realmente sucede en producción. El punto de referencia obtenido en el entorno de puesta en escena sería inexacto y tiene menos valor.
Las pruebas en producción, también conocidas como TIP, son una metodología de prueba de desplazamiento a la derecha en la que se prueban nuevos códigos, funciones y versiones en el entorno de producción. Las pruebas de carga en producción que adoptamos son muy beneficiosas ya que nos ayudan a:
Analizar la estabilidad y robustez del sistema.
Descubra puntos de referencia y cuellos de botella de aplicaciones con distintos niveles de tráfico, especificaciones de servidor y parámetros de aplicación.
Enrutamiento basado en FlowFlag
Nuestro enrutamiento basado en FlowFlag integrado en el marco base de microservicios es la base para hacer posible TIP. Esto es cierto para casos específicos, incluidas las aplicaciones que utilizan el descubrimiento de servicios Eureka para la distribución del tráfico.
Como se ilustra en el diagrama, el servidor web de Binance como puntos de entrada etiqueta un porcentaje del tráfico como se especifica en las configuraciones con encabezados FlowFlag; durante la prueba de carga, podemos seleccionar un host de un servicio específico y marcarlo como la instancia de rendimiento objetivo en el configs, esas solicitudes de rendimiento etiquetadas se enrutarán eventualmente a la instancia de rendimiento cuando lleguen al servicio para su procesamiento.
Está totalmente basado en configuración y con carga en caliente, podemos ajustar fácilmente el porcentaje de carga de trabajo mediante la automatización sin tener que implementar una nueva versión.
Se puede aplicar ampliamente a la mayoría de nuestros servicios, ya que el mecanismo es parte del paquete base y de puerta de enlace.
Un único punto de cambio también significa una fácil reversión para reducir los riesgos en la producción.

Mientras transformamos nuestra solución para que sea más nativa de la nube, también estamos explorando cómo podemos desarrollar un enfoque similar para admitir otro enrutamiento de tráfico ofrecido por proveedores de nube pública o Kubernetes.
Análisis canary automatizado para minimizar los riesgos de impacto en el usuario
La implementación Canary es una estrategia de implementación para reducir el riesgo de implementar una nueva versión de software en producción. Por lo general, implica implementar una nueva versión del software, llamada versión canary, para un pequeño subconjunto de usuarios junto con la versión estable. Luego dividimos el tráfico entre las dos versiones para que una parte de las solicitudes entrantes se desvíe al canario.
Luego, la calidad de la versión canaria se evalúa mediante el llamado análisis canario. Esto compara métricas clave que describen el comportamiento de las versiones antiguas y nuevas. Si hay una degradación significativa de las métricas, el canary se cancela y todo el tráfico se enruta a la versión estable para minimizar el impacto de un comportamiento inesperado.
Usamos el mismo concepto para construir nuestra solución de prueba de carga automática. La solución utiliza la plataforma Kayenta para el análisis canary automatizado (ACA) a través de Spinnaker para permitir implementaciones canary automatizadas. Nuestro flujo de prueba de carga típico cuando se sigue este método es el siguiente:
A través del flujo de trabajo, agregamos carga de tráfico de forma incremental (por ejemplo, 5 %, 10 %, 25 %, 50 %) al host de destino según lo especificado o hasta que alcance su punto de ruptura.
Bajo cada carga, el análisis canario se ejecuta repetidamente con Kayenta durante un período de tiempo (por ejemplo, 5 minutos) para comparar métricas clave del host probado con el período de precarga como línea de base y el período actual de poscarga como experimento.
La comparación (modelo de configuración canary) se centra en comprobar si el host de destino:
Alcanza limitaciones de recursos, por ejemplo, el uso de CPU supera el 90%.
Tiene un aumento significativo en las métricas de error, por ejemplo, registros de errores, excepciones HTTP o rechazos de límite de tasa.
¿Las métricas principales de la aplicación siguen siendo razonables, por ejemplo, una latencia HTTP de menos de 2 segundos (personalizable para cada servicio)?
Para cada análisis, Kayenta nos entrega un informe para indicar el resultado y la prueba finaliza inmediatamente en caso de falla.
Esta detección de fallos suele tardar menos de 30 segundos, lo que reduce significativamente la posibilidad de afectar la experiencia de nuestros usuarios finales.

Habilitación de conocimientos de datos
Es fundamental recopilar suficiente información sobre todos los procesos y ejecuciones de pruebas descritos anteriormente. El objetivo final es mejorar la confiabilidad y solidez de nuestro sistema, lo cual es imposible sin información valiosa sobre los datos.
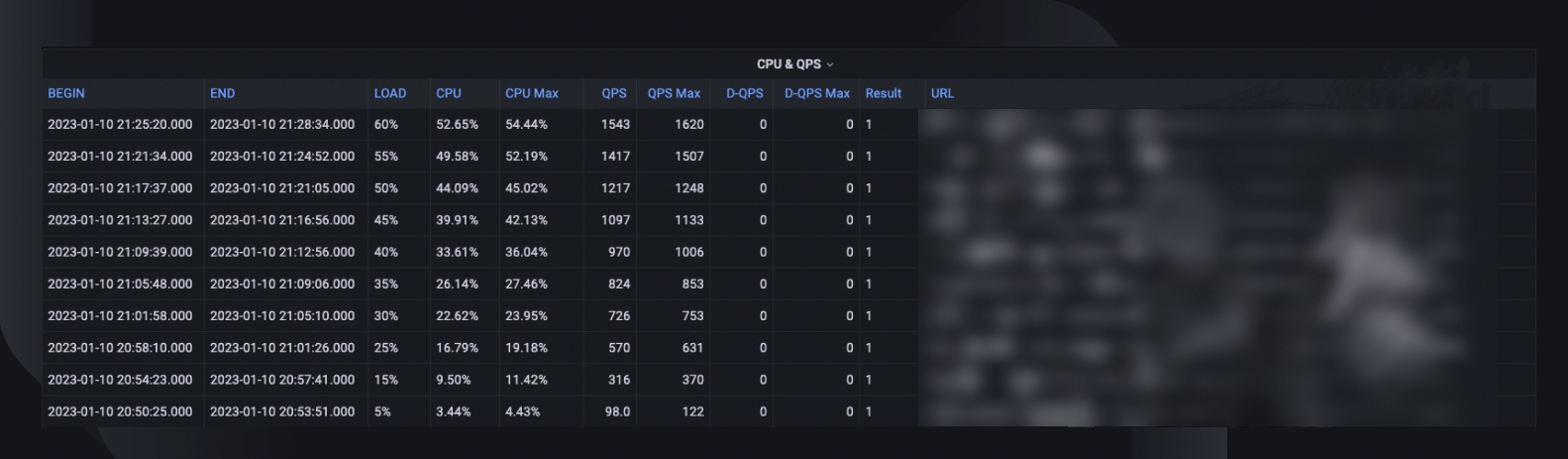
Un resumen general de la prueba captura el porcentaje de carga máxima que el host pudo manejar, el uso máximo de CPU y el QPS del host. En base a eso, también estima el número de instancias que podemos necesitar implementar para cumplir con nuestra reserva de capacidad, considerando el QPS más alto de todos los tiempos de los servicios.
Otra información valiosa para el análisis incluye la versión del software, las especificaciones del servidor, el recuento implementado y un enlace al panel del monitor donde podemos consultar lo que sucedió durante la prueba.

Una curva de referencia indica cómo ha cambiado el rendimiento en los últimos tres meses para que podamos descubrir posibles problemas relacionados con una versión de aplicación específica.

Las tendencias de CPU y QPS muestran cómo el uso de la CPU se correlacionaba con el volumen de solicitudes que el servidor tenía que manejar. Esta métrica puede ayudar a estimar la capacidad de los servidores para el crecimiento del tráfico entrante.
El comportamiento de latencia de la API captura cómo varía el tiempo de respuesta bajo diferentes condiciones de carga para las cinco API principales. Luego podemos optimizar el sistema si es necesario a nivel de API individual.

Las métricas de distribución de carga de API nos ayudan a comprender cómo la composición de API afecta el rendimiento del servicio y brindan más información sobre las áreas de mejora.
Normalización y productización.
A medida que nuestro sistema siga creciendo y evolucionando, seguiremos rastreando y mejorando la estabilidad y confiabilidad del servicio. Continuaremos esto a través de:
Un cronograma de pruebas de carga regular y establecido para servicios críticos.
Pruebas de carga automáticas como parte de nuestros canales de CI/CD.
Mayor productización de toda la solución para prepararse para la adopción a gran escala en toda la organización.
Limitaciones
Existen algunas limitaciones para el enfoque de prueba de carga actual:
El enrutamiento basado en FlowFlag solo es aplicable a nuestro marco de microservicios. Buscamos expandir la solución a más escenarios de enrutamiento aprovechando la función de enrutamiento ponderado común de los balanceadores de carga en la nube o Kubernetes Ingress.
Dado que basamos la prueba en el tráfico de usuarios reales en producción, no podemos realizar pruebas de funciones con API o casos de uso específicos. Además, para servicios con un volumen muy bajo, el valor sería limitado ya que es posible que no podamos identificar su cuello de botella.
Realizamos estas pruebas contra servicios individuales en lugar de cubrir cadenas de llamadas de extremo a extremo.
Las pruebas en producción a veces pueden afectar a los usuarios reales si se producen fallas. Por lo tanto, debemos tener análisis de fallas y reversión automática con capacidades de automatización total.
Pensamientos finales
Es fundamental para nosotros pensar en escenarios de aumento de tráfico para evitar la sobrecarga del sistema y garantizar su tiempo de actividad. Es por eso que hemos creado los procesos de prueba de carga y administración de capacidad que se describen a lo largo de este artículo. Para resumir:
Nuestra gestión de capacidad está impulsada por los picos y está integrada en cada etapa del ciclo de vida del servicio, evitando la sobrecarga con actividades como medición, configuración de prioridades, alertas e informes de capacidad, etc. Esto es, en última instancia, lo que hace que los procesos y necesidades de Binance sean únicos en comparación con una situación típica de gestión de capacidad. .
El punto de referencia del servicio obtenido de las pruebas de carga es el punto focal de la gestión y planificación de la capacidad. Determina con precisión el recurso de infraestructura necesario para soportar las demandas comerciales actuales y futuras. En última instancia, esto tuvo que realizarse en producción con una solución única creada por Binance que nos permitiera satisfacer nuestras necesidades específicas.
Con todo esto en conjunto, esperamos que pueda ver que una buena planificación y marcos exhaustivos ayudan a crear el servicio que los habitantes de Binancia conocen y disfrutan.
Referencias
Dominic Ogbonna, A-Z de Gestión de capacidad: Guía práctica para implementar el monitoreo de TI empresarial y la planificación de capacidad, Capítulo 4, Capítulo 6
Luis Quesada Torres, Doug Colish, SRE Mejores Prácticas para la Gestión de Capacidad
Alejandro Forero Cuervo, Sarah Chavis, libro Google SRE, Capítulo 21 - Manejo de sobrecarga
Otras lecturas
(Blog) Cómo Binance Ledger impulsa tu experiencia en Binance
(Blog) Presentamos Binance Oracle VRF: la próxima generación de aleatoriedad verificable
(Blog) Binance se une a la Alianza FIDO en preparación para la implementación de la clave de acceso

