
3D Avatar Diffusion es un algoritmo de aprendizaje automático que puede tomar una única imagen 2D de un rostro humano y crear un avatar tridimensional (3D). Luego, el avatar se puede utilizar para crear una experiencia de realidad virtual (VR) o realidad aumentada (AR) o simplemente para proporcionar una vista realista en 3D de la persona para juegos u otros fines.
El modelo de difusión fue desarrollado por un equipo de investigadores de Microsoft Research y se describe en un artículo publicado en la revista arXiv.

3D Avatar Diffusion se basa en un tipo de algoritmo de aprendizaje automático llamado modelo de difusión. Los modelos de difusión son modelos generativos, lo que significa que pueden generar nuevos datos similares a los datos de entrenamiento. Los modelos de difusión se han utilizado antes para generar imágenes 3D a partir de imágenes 2D, pero ADM es el primer modelo de difusión que puede generar un avatar 3D realista a partir de una única imagen 2D.
Para entrenar el modelo, los investigadores utilizaron un conjunto de datos de más de 200.000 modelos faciales en 3D. El conjunto de datos incluía una amplia variedad de rostros con diferentes tonos de piel, peinados y rasgos faciales. Luego, el ADM pudo aprender la relación entre la imagen 2D y el modelo facial 3D y generar un avatar 3D realista a partir de una única imagen 2D.
El modelo también se puede utilizar para generar un avatar a partir de una foto tomada desde un ángulo diferente.
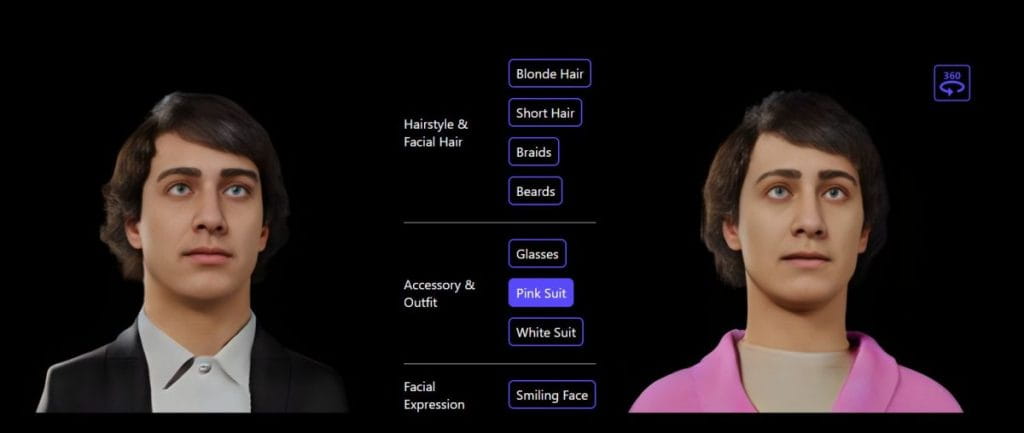 Para el avatar 3D personalizado, el modelo Rodin ofrece manipulación guiada por texto. La edición de lenguaje natural es una forma intuitiva de cambiar muchas funciones diferentes de avatar 3D.
Para el avatar 3D personalizado, el modelo Rodin ofrece manipulación guiada por texto. La edición de lenguaje natural es una forma intuitiva de cambiar muchas funciones diferentes de avatar 3D.
Este estudio propone un modelo generativo 3D que crea automáticamente avatares digitales 3D que se representan como campos de radiación neuronal utilizando modelos de difusión. Debido a los prohibitivos requisitos de memoria y procesamiento asociados con el 3D, crear las ricas funciones necesarias para avatares de alta calidad es un gran problema. Los desarrolladores sugieren que la red de difusión implementada (Rodin) solucione este problema.
 En términos de género, edad, raza, expresión, accesorios faciales, etc., la modelo exhibe una destacada diversidad generacional.
En términos de género, edad, raza, expresión, accesorios faciales, etc., la modelo exhibe una destacada diversidad generacional.
Esta red despliega numerosos mapas de características 2D de un campo de radiación neuronal en un único plano de características 2D, donde el modelo luego ejecuta una difusión con reconocimiento 3D. El modelo de Rodin utiliza convolución compatible con 3D, que atiende a las características proyectadas en el plano de características 2D de acuerdo con su relación original en 3D, para proporcionar la eficiencia computacional tan necesaria y al mismo tiempo mantener la integridad de la difusión en 3D.
Lea más sobre la IA:
VALL-E: el nuevo modelo de conversión de texto a voz de disparo cero de Microsoft puede duplicar la voz de todos en tres segundos
VALL-E de Microsoft parece ser el software fraudulento más peligroso jamás creado
Artista crea un script antirrobo para proteger el arte y utiliza la misma marca de agua que los generadores de IA
Microsoft y Google en 2023: el principal enfrentamiento del año entre titanes de la IA
La publicación Microsoft lanzó un modelo de difusión que puede construir un avatar 3D a partir de una sola foto de una persona apareció por primera vez en Metaverse Post.