
Article reprint source: AIGC
Original source: Silicon-based standpoint
Author: Luo Yihang

Image source: Generated by Unbounded AI
This is the first large language model independently developed by a smartphone manufacturer that I have experienced - the "Blue Heart Little V" based on the Blue Heart large model launched by vivo. As a "big model Shennong", I have recently reminded myself to "lower my expectations" before testing any model service, especially for those demos with videos that are too cool. But for the Blue Heart large model, my feeling is: it meets expectations. It is not cool, but it is still practical.
As a large language model launched by smartphone manufacturers, people generally think that it will not be too large, the parameters are low, the emergence effect may not be very good, and there will be bugs in understanding some complex texts and intentions. But my experience with the Blue Heart large model is the opposite: it shows strong reasoning ability in creation and summarization, which can reach more than 80 points, but it performs poorly in basic image search and regular writing.
You should know that the Blue Heart Big Model currently installed on the vivo X100 series of mobile phones is a dual-purpose model for end-side scenarios and cloud-based applications, which is far less "big" than a big model with hundreds of billions of parameters. But when I threw it an article about whether the emergence of big models really exists, it accurately found the most critical and core argument in it: the emergence of big models is the result of the metric selected by researchers rather than the expansion of model capabilities, so it is not a true "intelligence emergence".
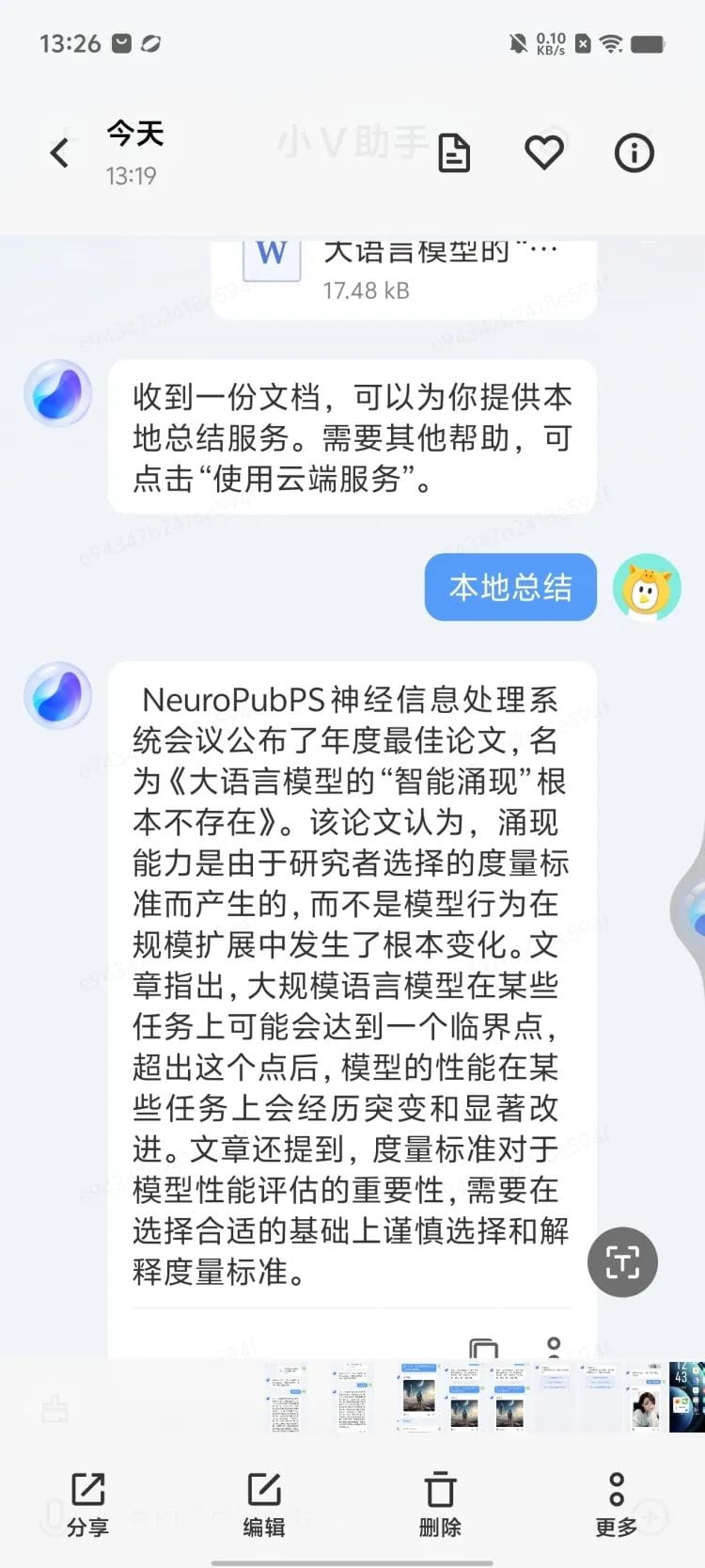
This really shocked me a bit. Because "reading documents" is a somewhat difficult task for large language models, not every model can read well. For example, ChatGPT's ability to read complex and lengthy PDF files has recently deteriorated dramatically, especially in terms of generalization. But Blue Heart Little V of the Blue Heart large model can find the most critical argument at once. It is worth mentioning that when testing, I specifically checked the "local summary" function, which is completely summarizing using the computing power (MediaTek Dimensity 9300) and reasoning ability of this vivo X100 machine. To some extent, it breaks the inherent perception that "large models must be large".
Then, I discovered a more interesting phenomenon: when you upload a longer paper to the Blue Heart Big Model, it can still extract the most critical and important ideas and findings, but the extended narrative is often hastily concluded with a few sentences, "reading well but not seeking to understand deeply". It forms a contrast with some other big model Chat Bots in reading comprehension ability: many models are strong in information disassembly ability, but not in distillation and generalization ability. The Blue Heart Big Model is very accurate in summarization and distillation, but is unwilling to disassemble and read carefully, and is unwilling to waste tokens on explaining problems. This should be closely related to the size of the model.
In terms of local photo search and image search on mobile phones, the response speed of the Blue Heart model is as smooth as silk, for example, it can find all the "photos about the Forbidden City" stored locally on the mobile phone within one second. In terms of writing travel guides, its performance is quite satisfactory. In terms of image creation, the Forbidden City, beef ramen, and spicy hot pot it draws are close to the level of ChatGPT's DALL-E, but its imagination is not as rich as ChatGPT, and it can't draw particularly crazy and brain-opening pictures. However, when I asked it to draw "an AI thinking deeply about the future of mankind", it actually gave me a picture with such an artistic conception.
In addition, the ability of the blue heart model to control the APP through natural dialogue is remarkable. I tell it that I want to order Mala Xiangguo takeout, and it will tell you that Meituan is not installed on this new phone. After you agree to its installation, it will automatically download the Meituan APP from the app store. Then, I will help you open the page full of "Spicy Hotpot". Of course, you can think that Apple's Siri can also do it, because as an assistant-level application at the bottom of the system, it is easy to access the permissions on this phone. But the difference is that Siri can only accept very clear instructions to open which app. It is powerless to face a general natural language demand. It is an embedded intelligent voice module, but the Lanxin Xiao V is in the Lanxin Big Model. With the blessing, it is already a Copilot with natural language understanding capabilities.
In short, after tuning a few key functions, you will have a more confident direction and judgment, that is, the big model on the end is valid and reliable. Moreover, the big model on the end and even the entire big language model may still depend on mobile phone manufacturers to be implemented in thousands of households and all living things, whether you like it or not.
To some extent, the large model adapted for mobile phones is actually closer to the "small language model" recently emphasized by Microsoft. Its parameters usually cannot exceed 10 billion, otherwise the mobile phone memory will not be able to run it. This also means that it can only be trained in specific aspects, or a model can be trained to a certain output level and then stop. For most people, this is enough. Mistral AI, a Paris startup that has been popular recently, is such a small model company.
Judging from the parameters published by the Blue Heart Big Model, the 170 billion parameter cloud model is used to distill and train a low-parameter model, resulting in a 7 billion parameter model, with computing and reasoning placed on both the cloud side and the end side of the phone, while the computing and reasoning of the 1 billion parameter model is only on the end side. This is also what Qualcomm, MediaTek, Intel, and AMD are constantly trying and tinkering with in order to get rid of the Nvidia curse. If the model is not stuffed into mobile phones and PCs, they have no chance. But the models that can be stuffed into mobile phones and PCs are often not big enough and are small models.
Small models have their own advantages: they only focus on doing a few things well, without lengthy information and code output. They have a few highlights, but are average in other aspects. For example, Mistral AI's code is better than ChatGPT. Another example is the Blue Heart model, which is more accurate than other models in extracting and processing local documents, and is more efficient in managing documents and schedules on personal mobile phones. It can also do other things such as drawing, writing, and searching, but they are not outstanding. But so what?
In the current discussion of the future of generative artificial intelligence in China, there is a strange phenomenon: those who are talking about it in a high-profile way don’t get down to earth, and those who are down to earth don’t feel anything about AI. Most people have never used ChatGPT, and they may have only heard of Wenxin Yiyan, Tongyi Qianwen, and ChatGLM and used them occasionally, but they don’t see any essential changes in these things for themselves. And those players who are obsessed with large model parameters, scale, and benchmark evaluation results, all put all their results on Hugging Face and GitHub, and almost never promote them to ordinary people, and they don’t feel anything about them. AI developers and users are both indifferent, and this situation may not change in the short term.
But if smartphone manufacturers make large language models, it may be different. The main reason is: users can feel it. When the large model is built into the bottom layer of the operating system, it can be awakened, assisted and called at any time, just like the Blue Heart large model grows on Origin OS4. Users will involuntarily need it, need its assistance, test its potential, and even need its company. It may not be an omnipotent large model, it may be just a small model, but it understands its users, is familiar with the data in the device, understands user habits, protects user privacy, can help schedule, open takeaway menus, summarize documents, pick photos, and complete some basic writing. It is an AI that is "enough" and "trustworthy" for most people.
Promoting the popularization of large language models is definitely not achieved through AI programming, nor is it that only technological breakthroughs that refresh SOTA evaluations can benefit most humans. Just like whether a pair of shoes fits you well can only be known after you wear them, whether a model fits you well can only be known after you use it. I have been consciously "de-ChatGPTizing" recently: I rely on Kimi Chat to read papers and documents, Wenxin Yiyan and ChatGLM for desk work, and vivo Blue Heart large model for personal assistants, not for anything else, but because it "fits". You don't expect it to surpass ChatGPT in all aspects, but I really need a "large model" or "small model" that can be used on a mobile phone, protects personal privacy and data security, and has a decent average score in all aspects.
Large language models are meant to be used by people, not to brag about.