

Report Date: 2026-03-11
Sample Scope: ClawHub Top 100 Skills by downloads (as of March 10, 18:30 Beijing Time)
Detection Engine: AgentGuard Skills Security Scanning Engine
Purpose of the Scan: To evaluate the baseline security posture of the most popular AI Agent Skills and identify potential risks such as privilege abuse, sensitive operations, and malicious behavior patterns.
📊 1. Executive Summary
This security scan conducted a full analysis of the 100 most frequently downloaded Skills in the ClawHub ecosystem. The overall results are as follows:
Total Samples Scanned: 100
Successful Scan Rate: 100% (no parsing failures or missing files)
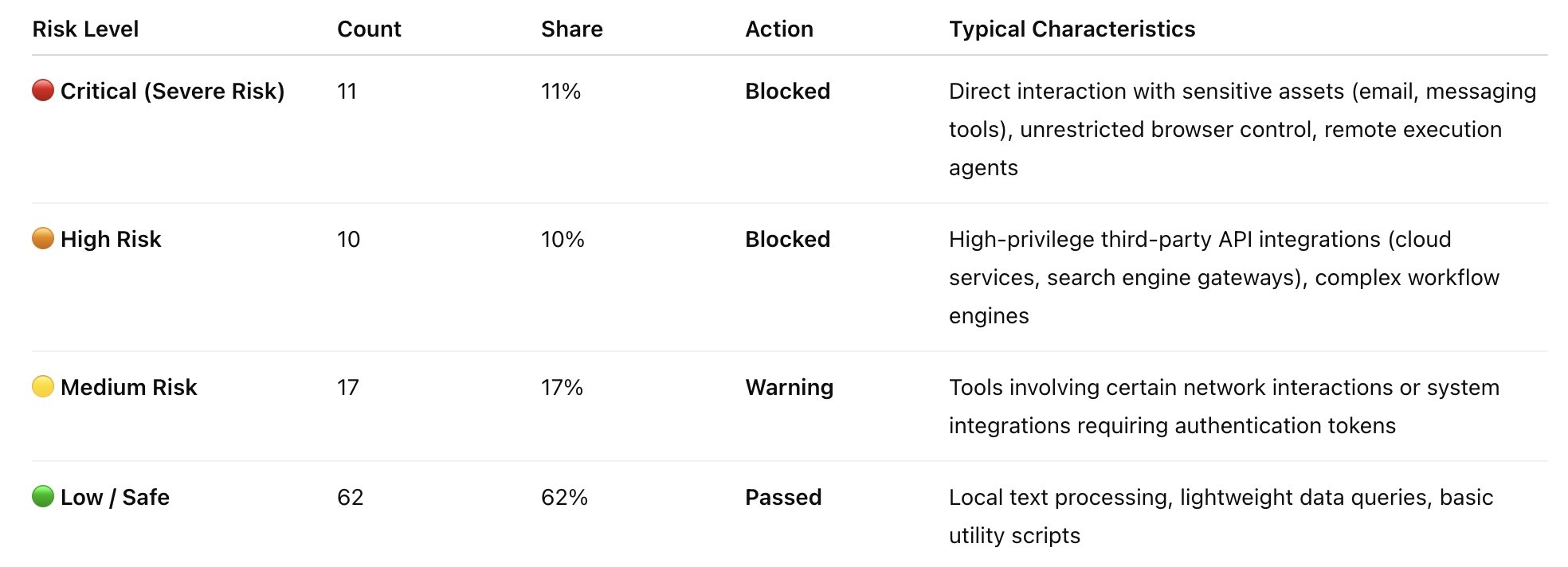
Blocked Skills: 21 (21%)
Warning Skills: 17 (17%)
Passed Skills: 62 (62%)

Key Finding: Among the Top 100 Skills, 21% contain explicit high-risk operations (such as direct network tunneling, sensitive API calls, or automated messaging). For these Skills, it is recommended to enforce a Human-in-the-Loop (HITL) confirmation mechanism before execution to ensure manual review of high-risk actions
Additionally, 17% of Skills present certain risk signals, and should be executed with caution. For users with stricter security requirements, enabling manual confirmation for these Skills is also recommended.
📈 2. Risk Level Distribution
Based on the AgentGuard rule set, the scan results are categorized into four risk levels, with the following distribution:
🚨 3. High-Risk (Critical & High) Skills Analysis
In this security scan, 21 Skills were directly classified as Blocked after triggering Critical or High-risk rules. These Skills mainly fall into the following high-risk operational scenarios:
3.1. Headless Browsers & Automation (Browser Automation)
These Skills typically call Puppeteer/Playwright or packaged CLI tools, allowing the Agent to freely access the internet.
Affected Skills: agent-browser (Critical), agent-browser-clawdbot (Critical)
Detection Reason: Detection of headless browser process control, execution of arbitrary JS scripts, or complex DOM interactions.
Risk Impact: May be used for SSRF (Server-Side Request Forgery), internal network probing, bypassing CAPTCHA protections for malicious scraping, or triggering payloads from phishing websites.
3.2. Communications & Messaging (Communications & Messaging)
Skills that directly control users’ email or messaging tools to send messages.
Affected Skills: agentmail (Critical), whatsapp-business (Critical), imap-smtp-email (Critical), mailchimp (High)
Detection Reason: Detection of SMTP/IMAP protocol keywords, bulk messaging API endpoints, and high-privilege communication tokens.
Risk Impact: If an Agent is compromised through a Prompt Injection attack, attackers could use these Skills to send spam or conduct social engineering scams, damaging user reputation and potentially violating privacy compliance requirements.
3.3. High-Privilege CRM & Cloud Resource APIs (Enterprise API Gateways)
Skills that perform read/write operations on enterprise SaaS platforms through proxy gateways.
Affected Skills: google-workspace-admin (Critical), google-slides (Critical), feishu-evolver-wrapper (Critical), pipedrive-api (High), youtube-api-skill (High), trello-api (High), google-meet (High)
Detection Reason: The rule engine detected REST API request structures capable of modifying sensitive data, as well as the ability to alter the state of external systems.
Risk Impact: Agents may directly modify or even delete core enterprise data such as sales, financial, document, or media assets (including granting or revoking administrator privileges). Without strict Human-in-the-Loop verification, operational mistakes could lead to severe losses.
3.4. Deep Search Engines & Scraping Aggregation (Search & Scraping)
Tools capable of deep content crawling and multi-engine aggregation.
Affected Skills: brave-search (High), duckduckgo-search (High), multi-search-engine (High), tavily (High)
Detection Reason: Detection of high-frequency external network request wrappers, HTML parsing, and scraping libraries.
Risk Impact: In addition to potential IP bans from target websites, unsafe web content extraction (such as directly reading unfiltered HTML or executing webpage content) may introduce Indirect Prompt Injection risks.
3.5. Core Logic Modification & Privilege Escalation (Self-Modification & Privilege Escalation)
Skills involving Agent behavior mutation, modification of hidden configurations, or access to system-level credentials.
Affected Skills: free-ride (Critical), moltbook-interact (Critical), trello (Critical), evolver (High)
Detection Reason: Detection of write access requests to system files (such as hidden .json configuration files), the ability to read local credentials, or direct concatenation of sensitive tokens in Bash commands.
Risk Impact: These Skills may modify the Agent’s core behavioral rules without authorization, bypass existing system restrictions, or leak critical API keys due to command injection vulnerabilities.
⚠️ 4. Medium-Risk (Medium / Warning) Skills Worth Attention
A total of 17 Skills were classified as Medium risk. Most of these are integration interfaces for third-party applications. While the scanning engine did not directly block them, the following considerations apply:
Calendar & scheduling tools (caldav-calendar, calendly-api)
Productivity & collaboration tools (notion, x-twitter, xero, typeform)
Microsoft ecosystem integrations (microsoft-excel, outlook-graph, outlook-api)
Utility toolkits (mcporter, asana-api, clickup-api)
Analysis: The key characteristic of these Skills is that their functionality is neutral, but they carry high-value credentials. The security scan identified that they require access tokens from users, but no explicit malicious logic was detected at the code level, so they were labeled with a Warning. However, if an Agent is tricked into using these Skills (for example, being instructed to “delete all my meetings tomorrow” or “publicly share this Notion document”), significant damage could still occur.
🛡️ 5. Summary & Security Recommendations
This security scan shows that around 20% of the Top 100 most-downloaded Skills on ClawHub contain explicit high-risk operations, demonstrating the necessity of performing security scanning and review for Skills.
Recommendations for users and ecosystem developers:
5.1. Improve the usability of high-risk Skills (Blocked): Avoid blanket bans. For high-value Skills such as agent-browser and agentmail, it is recommended to enforce a Human-in-the-Loop (HITL) confirmation mechanism before execution. The specific content to be sent or actions to be performed should be displayed, and execution should proceed only after explicit user authorization.
5.2. Strengthen protection against “Indirect Prompt Injection”: For all search-related Skills marked as High, the content returned to the Agent must undergo strict sanitization (such as stripping HTML tags and scripts) to prevent malicious content injection from external webpages.
5.3. Conduct regular security health checks: Based on the security blind spots identified in this analysis, actions such as modifying specific configuration file paths (e.g., AGENTS.md) and invoking system desktop control libraries should be added to the high-risk behavior list. Alternatively, developers can use AgentGuard security inspection and Skills scanning capabilities to regularly audit the security posture of Agents and their Skills.
👉Appendix: Detailed Results of the ClawHub Top 100 Skills Security Scan
Click the link to view:
https://inky-punch-9d2.notion.site/Appendix-Detailed-Results-of-the-ClawHub-Top-100-Skills-Security-Sca-3215da0dd7ad80719937c66b7c1225b3?source=copy_link