
Wichtigste Erkenntnisse
Bei Binance verwenden wir maschinelles Lernen (ML), um verschiedene Geschäftsprobleme zu lösen, darunter unter anderem Betrug im Zusammenhang mit Kontoübernahmen (ATO), P2P-Betrug und gestohlene Zahlungsdaten.
Mithilfe von Machine-Learning-Operationen (MLOps) haben unsere Binance Risk AI-Datenwissenschaftler eine End-to-End-ML-Pipeline in Echtzeit aufgebaut, die kontinuierlich produktionsreife ML-Dienste bereitstellt.

Warum verwenden wir MLOps?
Zunächst einmal ist die Erstellung eines ML-Dienstes ein iterativer Prozess. Datenwissenschaftler experimentieren ständig, um eine bestimmte Kennzahl zu verbessern, entweder offline oder online, basierend auf dem Ziel, einen Mehrwert für das Unternehmen zu schaffen. Wie können wir also diesen Prozess effizienter gestalten – zum Beispiel die Markteinführungszeit des ML-Modells verkürzen?
Zweitens wird das Verhalten von ML-Diensten nicht nur durch den Code beeinflusst, den wir Entwickler definieren, sondern auch durch die Daten, die er sammelt. Diese Idee, auch als Konzeptdrift bekannt, wird in Googles Artikel „Hidden Technical Debt in Machine Learning Systems“ hervorgehoben.
Nehmen wir zum Beispiel Betrug: Der Betrüger ist nicht nur eine Maschine, sondern ein Mensch, der sich anpasst und seine Angriffsmethoden ständig ändert. Daher wird sich die zugrunde liegende Datenverteilung weiterentwickeln, um die Änderungen der Angriffsvektoren widerzuspiegeln. Wie können wir effektiv sicherstellen, dass das Produktionsmodell das neueste Datenmuster berücksichtigt?
Um die oben genannten Herausforderungen zu bewältigen, verwenden wir ein Konzept namens MLOps, ein Begriff, der ursprünglich 2018 von Google vorgeschlagen wurde. Bei MLOps konzentrieren wir uns auf die Leistung des Modells und die Infrastruktur, die das Produktionssystem unterstützt. Dadurch können wir ML-Dienste erstellen, die skalierbar, hochverfügbar, zuverlässig und wartungsfreundlich sind.
Aufschlüsselung unserer End-to-End-ML-Pipeline in Echtzeit
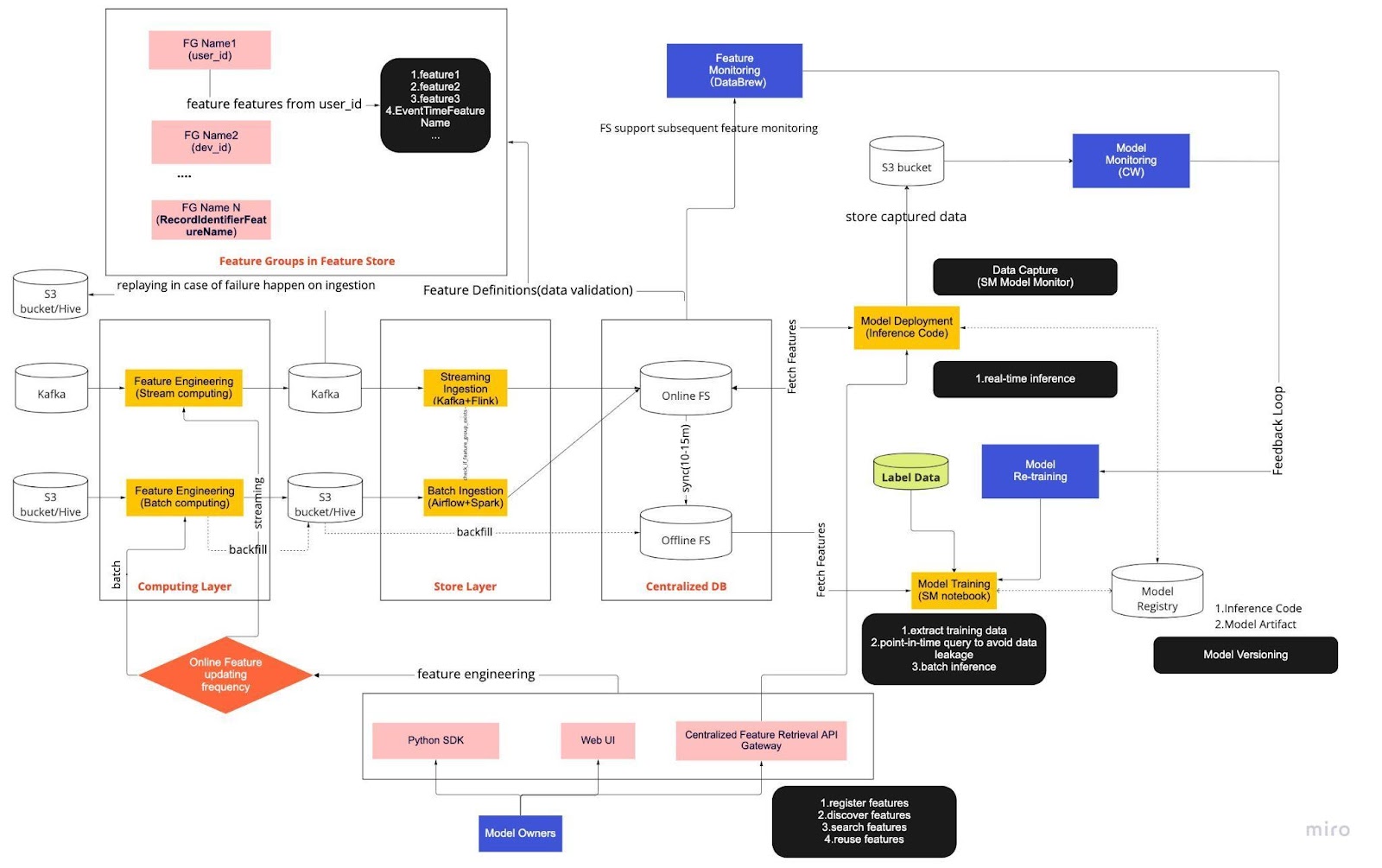
Betrachten Sie das obige Diagramm als unsere Standardarbeitsanweisung (Standard Operating Procedure, SOP) für die Echtzeit-Modellentwicklung mit einem Feature Store. Die End-to-End-ML-Pipeline bestimmt, wie unser Team MLops anwendet, und basiert auf zwei Arten von Anforderungen: funktionalen und nicht-funktionalen.
Funktionalität
Datenverarbeitung
Modelltraining
Modellentwicklung
Modellbereitstellung
Überwachung
Nicht-funktionale Anforderungen
Skalierbar
Hochverfügbar
Zuverlässig
Wartungsfreundlich
Die Pipeline ist weiter in sechs Hauptkomponenten unterteilt:
Rechenschicht
Ebene speichern
Zentralisierte Datenbank
Modelltraining
Modellbereitstellung
Modellüberwachung
1. Rechenschicht

Die Computerebene ist hauptsächlich für das Feature Engineering verantwortlich, also den Prozess der Umwandlung von Rohdaten in nützliche Features.
Wir kategorisieren die Computerebene anhand der Aktualisierungshäufigkeit in zwei Typen: Stream-Computing für Intervalle von einer Minute/Sekunde und Batch-Computing für Intervalle von einem Tag/einer Stunde.
Die Eingabedaten der Rechenschicht stammen im Allgemeinen aus der ereignisbasierten Datenbank, zu der Apache Kafka und Kinesis gehören, oder der OLAP-Datenbank, zu der Apache Hive für Open Source und Snowflake für Cloud-Lösungen gehören.
2. Ebene speichern
In der Store-Ebene registrieren wir Feature-Definitionen und stellen sie in unserem Feature-Store bereit. Außerdem führen wir Backfill durch. Dabei handelt es sich um einen Prozess, der es uns ermöglicht, Features anhand historischer Daten neu zu erstellen, wenn ein neues Feature definiert wird. Backfill ist normalerweise eine einmalige Aufgabe, die unsere Datenwissenschaftler in einer Notebook-Umgebung erledigen können. Da Kafka nur Ereignisse der letzten sieben Tage speichern kann, verwendet es einen Backup-Mechanismus in der S3/Hive-Tabelle, um die Fehlertoleranz zu erhöhen.
Sie werden feststellen, dass die Zwischenschicht, Hive und Kafka, bewusst zwischen der Computing- und der Speicherschicht untergebracht ist. Stellen Sie sich diese Platzierung als Puffer zwischen Computing- und Schreibfunktionen vor. Eine Analogie wäre die Trennung von Produzent und Konsument. Stream Computing ist der Produzent, während Stream Ingestion der Konsument ist.
Die Entkopplung von Datenverarbeitung und Datenaufnahme bietet unseren ML-Pipelines zahlreiche Vorteile. Zunächst einmal können wir die Robustheit der Pipeline im Fehlerfall erhöhen. Unsere Datenwissenschaftler können weiterhin Funktionswerte aus der zentralen Datenbank abrufen, selbst wenn die Datenaufnahme- oder Datenverarbeitungsebene aufgrund von Betriebs-, Hardware- oder Netzwerkproblemen nicht verfügbar ist.
Darüber hinaus können wir verschiedene Teile der Infrastruktur individuell skalieren und den Energiebedarf für Aufbau und Betrieb der Pipeline reduzieren. Wenn sie beispielsweise aus irgendeinem Grund ausfällt, blockiert die Aufnahmeschicht nicht die Rechenschicht. Was Innovationen angeht, können wir mit neuen Technologien experimentieren und sie übernehmen, beispielsweise mit einer neuen Version der Flink-Anwendung, ohne unsere bestehende Infrastruktur zu beeinträchtigen.

Sowohl die Computing-Ebene als auch die Store-Ebene sind sogenannte automatisierte Feature-Pipelines. Diese Pipelines sind unabhängig, werden nach unterschiedlichen Zeitplänen ausgeführt und als Streaming- oder Batch-Pipelines kategorisiert. Die beiden Pipelines unterscheiden sich in folgender Weise: Eine Feature-Gruppe in einer Batch-Pipeline wird möglicherweise jede Nacht aktualisiert, während eine andere Gruppe stündlich aktualisiert wird. In einer Streaming-Pipeline wird die Feature-Gruppe in Echtzeit aktualisiert, wenn Quelldaten in einem Eingabestream eintreffen, z. B. einem Apache Kafka-Thema.
3. Zentralisierte Datenbank
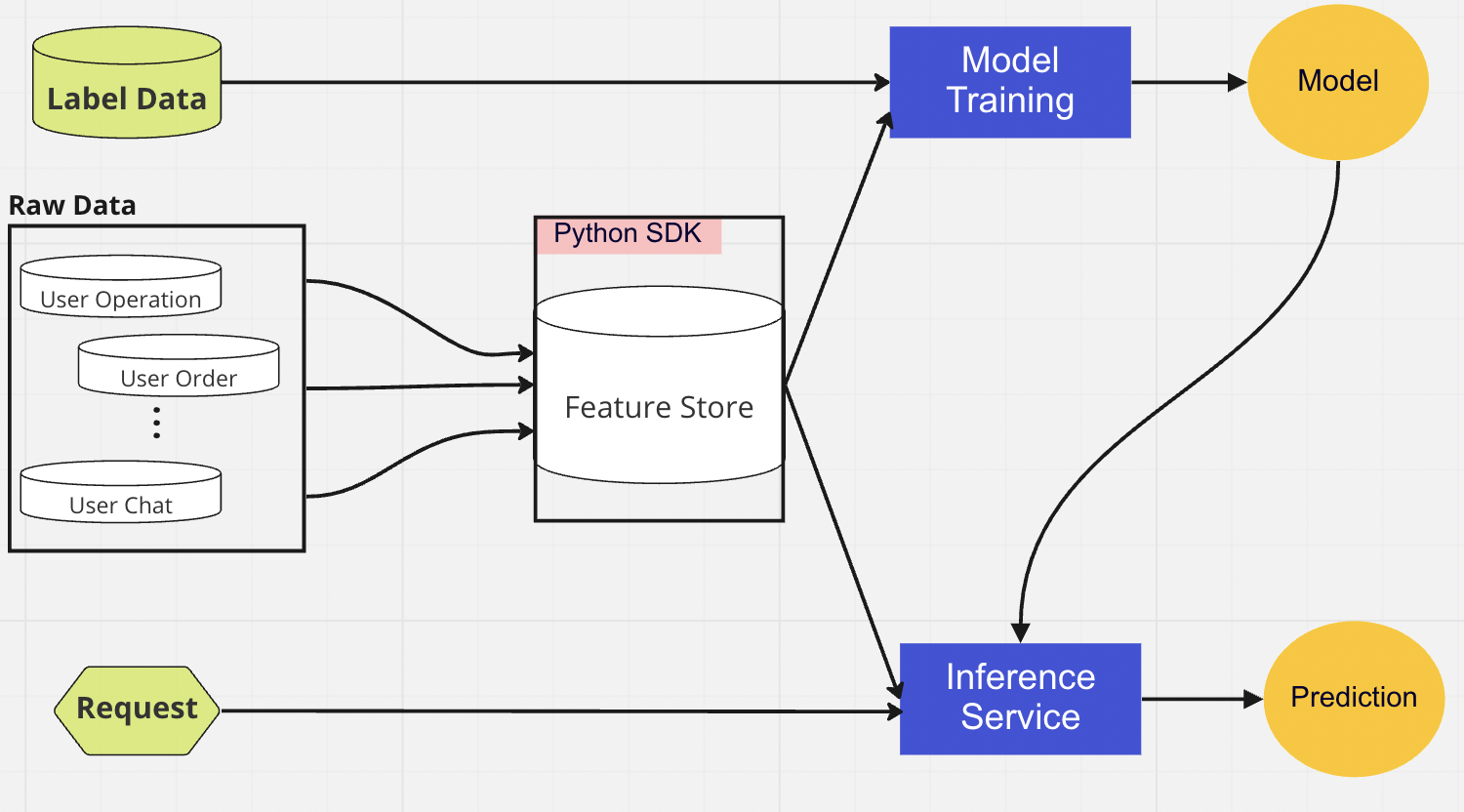
In der zentralisierten DB-Ebene präsentieren unsere Datenwissenschaftler ihre funktionsbereiten Daten in einem Online- oder Offline-Feature-Store.
Der Online-Feature-Store ist ein Store mit geringer Latenz und hoher Verfügbarkeit, der die Echtzeitsuche nach Datensätzen ermöglicht. Der Offline-Feature-Store hingegen bietet ein sicheres und skalierbares Repository aller Feature-Daten. So können Wissenschaftler Trainings-, Validierungs- oder Batch-Scoring-Datensätze aus einer Reihe zentral verwalteter Feature-Gruppen mit einem vollständigen historischen Datensatz der Feature-Werte im Objektspeichersystem erstellen.
Beide Feature Stores werden alle 10–15 Minuten automatisch miteinander synchronisiert, um eine Abweichung zwischen Training und Bereitstellung zu vermeiden. In einem zukünftigen Artikel werden wir uns eingehend damit befassen, wie wir Feature Stores in den Pipelines verwenden.
4. Modelltraining
In der Modelltrainingsebene extrahieren unsere Wissenschaftler Trainingsdaten aus dem Offline-Feature-Store, um unsere ML-Dienste zu optimieren. Wir verwenden zeitpunktbezogene Abfragen, um Datenverluste während des Extraktionsprozesses zu verhindern.
Darüber hinaus enthält diese Schicht eine wichtige Komponente, die als Feedbackschleife für das Neutraining von Modellen bezeichnet wird. Das Neutraining von Modellen minimiert das Risiko von Konzeptabweichungen, indem sichergestellt wird, dass die eingesetzten Modelle die neuesten Datenmuster genau darstellen – beispielsweise wenn ein Hacker sein Angriffsverhalten ändert.
5. Modellbereitstellung
Für die Modellbereitstellung verwenden wir hauptsächlich einen Cloud-basierten Scoring-Dienst als Rückgrat unserer Echtzeitdatenbereitstellung. Hier ist ein Diagramm, das zeigt, wie der aktuelle Inferenzcode in den Feature Store integriert wird.

6. Modellüberwachung
In dieser Ebene überwacht unser Team die Nutzungsmetriken für Bewertungsdienste wie QPS, Latenz, Speicher und CPU-/GPU-Auslastungsrate. Neben diesen grundlegenden Metriken verwenden wir erfasste Daten, um die Merkmalsverteilung im Zeitverlauf, die Trainings-Serving-Schiefe und die Vorhersagedrift zu überprüfen, um eine minimale Konzeptdrift sicherzustellen.
Abschließende Gedanken
Zusammenfassend lässt sich sagen, dass uns die grobe Aufteilung unserer Pipeline-Infrastruktur in eine Computing-Schicht, eine Speicherschicht und eine zentrale Datenbank drei wesentliche Vorteile gegenüber einer stärker gekoppelten Architektur bietet.
Robustere Pipelines im Störungsfall
Größere Flexibilität bei der Auswahl der zu implementierenden Tools
Unabhängig skalierbare Komponenten
Sie möchten ML nutzen, um das weltweit größte Krypto-Ökosystem und seine Benutzer zu schützen? Dann sehen Sie sich auf unserer Karriereseite Binance Engineering/AI an, um offene Stellenangebote zu finden.