
Autor: Lisa A., Taiko Labs; Übersetzung: Golden Finance xiaozou
In diesem Artikel werden verschiedene L2-Cross-Chain-Messaging-Methoden aus der Perspektive des Rollups untersucht, wobei der Schwerpunkt auf der vertrauenswürdigen Cross-Chain-Kommunikation liegt. Wir werfen einen kurzen Blick auf den Direct-Read-State-Ansatz, den Light-Client-Ansatz und den Speichernachweis. Wir werden auch Proof-Aggregation-Mechanismen, vertrauenswürdige kettenübergreifende Nachrichtenübertragung von Drittanbietern und zentrale kettenübergreifende ZK-Lösungen behandeln. Schauen wir uns abschließend an, wie verschiedene L2s heute Cross-Chain-Messaging implementieren.
1. Einführung in kettenübergreifendes Messaging
Für die kettenübergreifende Kommunikation müssen alle Parteien (L2, L3 usw.) direkten Zugriff auf die neueste Ethereum-Statuswurzel haben.
Alle Einzahlungsschichten verfügen über einen „eingebauten“ kettenübergreifenden Mechanismus, der für den Zugriff auf die L1-Statuswurzel verwendet werden kann, die als Einzahlungsnachricht an L2 übergeben wird.
1.1 Zwei Zugriffsarten auf Statuswurzeln
Typ 1: Direktes Lesen der Statuswurzel – kann über Opcodes oder vorkompiliert erfolgen. Allerdings wurde es noch nicht umgesetzt, sodass kein Nachweis erforderlich ist.
· Brecht Devos beschrieb in einem Forschungsartikel eine mögliche Methode zum direkten Lesen des Status: „… wir könnten einen vorkompilierten Vertrag offenlegen, der intelligente Verträge direkt in der Zielkette aufrufen kann. Diese Vorkompilierung fügt den intelligenten Vertragscode direkt ein und führt ihn aus.“ die andere Kette stellt sicher, dass der Smart Contract immer auf effiziente und leicht nachweisbare Weise Zugriff auf den neuesten verfügbaren Stand hat.“
· Eine entsprechende Beschreibung finden Sie auch im RFP „Remote Static Call Proof of Concept“ von Optimism.
Typ 2: Beweisgenerierung – also der Nachweis einer Aussage über eine Blockchain auf einer anderen Blockchain.
Es gibt zwei Methoden für „Cross-Chain-Messaging mit Beweis“:
· Vertrauenslose kettenübergreifende Kommunikation – das heißt, kein vertrauenswürdiger Dritter (z. B. Verwendung von Light-Clients oder Speichernachweisen). Der vertrauenslose Ansatz kann sowohl für Dritte zur Generierung von Beweisen als auch für kettenübergreifende Kommunikationsteilnehmer zur Generierung von Beweisen selbst verwendet werden.
· Teilen Sie Beweise zwischen verschiedenen Rollups, um kettenübergreifende Vorgänge sicherzustellen. Diese Methode wird in diesem Artikel nicht besprochen. Sie befindet sich derzeit in der Forschungs- und Erkundungsphase und wird nicht als Lösung angesehen, die möglicherweise weit verbreitet ist.
1.2 Methode „Cross-Chain Message Passing with Proof“.
1.2.1 Cross-Chain-Messaging für leichte Clients
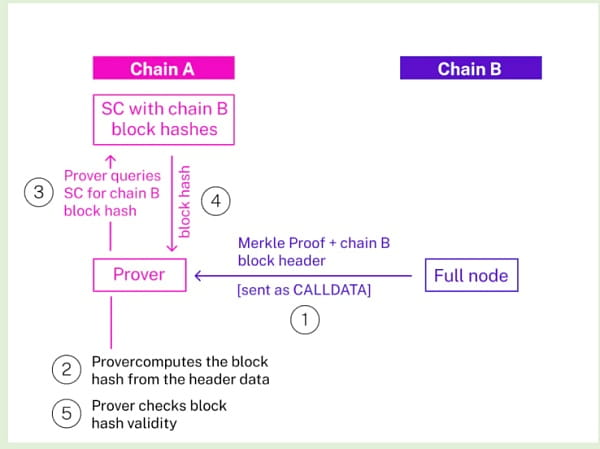
Beweisen Sie die Daten zu Kette B
· Erhalten Sie Merkel-Beweisdaten vom vollständigen Knoten der Kette B (Archivknoten, wenn ein Speichernachweis bestimmter historischer Zustände erforderlich ist);
· Senden Sie den Block-Header und die Beweisdaten, die dem Block der Kette B entsprechen und den Status enthalten, den wir überprüfen möchten, als Aufrufdaten an den Prüfervertrag in Kette A;
· Der Prüfervertrag berechnet den Block-Hash-Wert basierend auf den Block-Header-Daten, fragt den Light-Client-Smart-Vertrag auf Kette A ab (verfolgt den Block-Hash-Wert von Kette B) und prüft, ob der Hash-Wert gültig ist;
· Beweisdaten werden anhand der Bytes32-Statuswurzel im Blockheader überprüft.
1.2.2 Aufbewahrungsnachweis
Es gibt zwei „Workflow“-Optionen für den Speichernachweis:
· Speichernachweis erstellen → in der Kette verwenden
· Speichernachweis generieren → ZK-Beweis generieren → in der Kette verwenden
Möglicherweise gibt es auch eine Entität, die mehrere Proof-Sammlungen in einem einzigen Proof zusammenfasst (einschließlich Speicher-Proofs und ZK-Proofs). Dies ist ein optionaler Optimierungsschritt und wird noch nicht besprochen.
Werfen wir einen Blick auf die drei Hauptphasen des Speicherbeweis-Workflows: Speicherbeweis erstellen, ZK-Beweis erstellen und in der Kette verwenden.
(1) Speicherzertifikat erstellen
· Der Speichernachweis ermöglicht es uns, mithilfe von Vertraulichkeitsverpflichtungen nachzuweisen, dass bestimmte Informationen in der Blockchain vorhanden und authentisch sind.
· Proof-of-Storage ist seit dem Aufkommen der Merkle-Bäume im Jahr 1979 Teil der kryptografischen Community. Allerdings sind Vanilla-Lagerzertifikate in der Regel recht groß. Moderne Innovationen bestehen darin, Speicherbeweise mit beweisbaren Berechnungen zu kombinieren, um prägnante Beweise zu erstellen, die in der Kette verifiziert werden können.
Um einen Speichernachweis zu generieren, müssen ein bestimmter Datenblock und der zugehörige Merkle- oder Verkle-Pfad im Merkle-Baum angegeben werden. Der Pfad besteht aus den Geschwister-Hashes, die zur Rekonstruktion des Root-Hashes mit demselben Hashing-Algorithmus erforderlich sind.
Um den Speichernachweis zu überprüfen, kann der Empfänger den Root-Hash anhand der bereitgestellten Daten und des Merkle- oder Verkle-Pfads neu berechnen. Wenn der neu berechnete Root-Hash mit einem bekannten Root-Hash übereinstimmt, kann der Empfänger sicher sein, dass die Daten authentisch und Teil des übermittelten Datensatzes sind.
(2) Generieren Sie ZKP (Zero-Knowledge Proof)
Der Speichernachweis vom Typ Ethereum ist jedoch etwa 4 KB groß – ziemlich groß, um den gesamten Speichernachweis an die Zielkette weiterzugeben, da die Überprüfung des Nachweises sehr teuer wäre. Daher ist es sinnvoll, ZKP (z. B. ZK-SNARK) zur Komprimierung zu verwenden, wodurch der Beweis kleiner und die Verifizierungskosten geringer werden können.
(3)Unroll ZKP
Nach Erhalt von ZKP können Benutzer in der Zielkette die erhaltenen Beweise entrollen (z. B. über Blockheader oder Block-Hashes auf den historischen Status zugreifen).
Das Abrollen kann auf folgende Weise erfolgen:
On-Chain-Akkumulation: Der gesamte Prozess der Rekonstruktion des Blockheaders aus dem Beweis wird direkt auf der Blockchain durchgeführt. Nachteile: hohe Gasgebühren und Verbrauch von Rechenressourcen; Vorteile: keine zusätzliche Beweiszeit, geringe Latenz, da keine Beweise außerhalb der Blockchain erstellt werden müssen.
Komprimierung in der Kette: Entfernen Sie redundante oder unnötige Informationen aus Daten oder verwenden Sie Datenstrukturen, die für Platzeffizienz optimiert sind. Die komprimierten Daten werden an die Blockchain gesendet und können bei Bedarf dekomprimiert werden. Nachteile: Das Komprimieren und Dekomprimieren von Daten kann zusätzliche Berechnungen erfordern, diese Verzögerung kann jedoch vernachlässigbar sein. Der verwendete Komprimierungsalgorithmus kann sich negativ auf die Datensicherheit auswirken. Vorteile: geringere Datenkosten.
Off-Chain-Speicher: Speichern Sie Daten außerhalb der Kette und platzieren Sie bestimmte Datenblöcke bei Bedarf in der Kette. Dies ist für Lösungen relevant, die aus irgendeinem Grund große Datenmengen speichern müssen (z. B. Ethereum-Archivknoten ab dem Genesis-Block). Nachteile: Wie On-Chain-Komprimierung; Vorteile: Reduziert die Datenkosten weiter.
1.2.3 Vertrauenswürdiger Dritter
Eine vollständige kettenübergreifende Lösung sollte auch eine Cross-Messaging-Lösung mit einem vertrauenswürdigen Dritten (z. B. Orakeln, zentralisierten Brücken usw.) umfassen.
1.2.4 „Universelle“ Beweissysteme
Im Falle der Verwendung eines gemeinsamen Mechanismus der Proof-Aggregation-Plattform kann die Nachrichtenzustellung durch den Empfang von Block-Hashes beschleunigt werden, die innerhalb der Aggregationsplattform abgerechnet werden, und die Abrechnung hier übernimmt auch die Nachrichtenzustellung (aber wenn mit der Proof-Aggregation-Plattform etwas schief geht, was ist zu tun?) ).
1.2.5 Einige unbekannte Probleme beim kettenübergreifenden ZK-Messaging
Ist kettenübergreifendes Messaging ohne einen vertrauenswürdigen Dritten (bei dem es sich um eine einzelne Entität oder mehrere Entitäten handeln kann) möglich? Was ist ein wirksamer Mechanismus für kettenübergreifendes Messaging? Im Allgemeinen gilt, dass sowohl für Ethereum L2 (das direkten Zugriff auf die Block-Hashes von L1 hat) als auch für Ethereum selbst: Wenn eine Kette einen Light-Client usw. auf einer anderen Kette ausführen kann, kann sie die Herkunft aus diesem externen Kettenblock-Header überprüfen, was ausreichend ist Vertrauenslose kettenübergreifende Nachrichtenübermittlung.
Ist die ZK-Schaltung, die für die Cross-Chain-Proof-Generierung verwendet wird, in der Größe angemessen? In einigen Fällen, insbesondere wenn die Konsensschicht (die eine Überprüfung kettenübergreifender Vorgänge erfordert) sehr groß ist, kann die für die kettenübergreifende ZK-Nachrichtenübermittlung verwendete Schaltung um Größenordnungen größer sein als Rollup und On-Chain-Speicher sowie der Rechenaufwand wird auch groß sein. Vermutlich könnte dieses Problem durch einen stärker zentralisierten Ansatz gelöst werden.
2. Beispiel einer kettenübergreifenden Messaging-Lösung
· Succinct Labs verwendet Light Clients, um den Konsens von der Quellkette bis zur Konsensebene der Zielkette zu überprüfen. Die konkrete Idee besteht darin, dass es ein Light-Client-Protokoll gibt, um sicherzustellen, dass Knoten die Blockheader des endgültigen Blockchain-Status synchronisieren können. ZKP wird zur Generierung von Konsensnachweisen verwendet.
· Lagrange Labs erstellt nicht interaktive kettenübergreifende Zustandsnachweise. Das Lagrange-Proof-Netzwerk ist für die Erstellung der Zustandswurzel verantwortlich. Jeder Lagrange-Knoten enthält einen Teil eines privaten Shard-Schlüssels, der zum Nachweis des Status einer bestimmten Kette verwendet wird. Jede Zustandswurzel ist eine mit einem Schwellenwert signierte Verkle-Wurzel, die zum Nachweis des Zustands einer bestimmten Kette zu einem bestimmten Zeitpunkt verwendet werden kann. Die Statuswurzel ist völlig universell und kann in Statusnachweisen verwendet werden, um den aktuellen Status eines Vertrags oder einer Wallet in der Kette nachzuweisen.
· Herodotus nutzt den ZKP-Speichernachweis, um intelligente Verträge bereitzustellen und synchron auf On-Chain-Daten anderer Ethereum-Schichten zuzugreifen. Zur Verifizierung nutzt es natives L1<>L2-Messaging, um Block-Hashes zwischen Ethereum-Rollups zu synchronisieren.
· =nil; Foundation (Mina, L1) ermöglicht Smart Contracts auf Ethereum, die Gültigkeit von Mina-Zuständen zu überprüfen. Generieren Sie spezielle Zustandsnachweise, die auf Ethereum kostengünstig zu verifizieren sind (native Mina-Beweise sind auf Ethereum teuer). Es wird davon ausgegangen, dass Anwendungen (irgendwann in der Zukunft) Minas Proof-Generierungstools direkt nutzen können, um die Gültigkeit kettenübergreifender Transaktionen zu überprüfen. =nil; Foundation verfügt außerdem über einen Proof-Markt, auf dem Benutzer/Projekte hauptsächlich SNARK-Zertifikate kaufen/verkaufen können, die einen vertrauenswürdigen Datenzugriff ermöglichen.
Axiom: Wenn Axiom bisher ein ZKP für das Ledger generiert hat – es muss kein ZKP für einen bestimmten Datenblock generiert werden – kann es dieses ZKP an die Kette weitergeben (als Relayer) und sogar Zugriff auf diesen ZKP-Besuch gewähren .
3. L2-Cross-Chain-Messaging
Haftungsausschluss: Die kettenübergreifende Nachrichtenübermittlung befindet sich für die meisten L2 noch in der Entwicklung. Alle folgenden Analysen basieren auf Open-Source-Informationen. Allerdings befinden sich die im Artikel erwähnten Lösungen möglicherweise in der Erkundungs- und Testphase, und beim Rollup werden möglicherweise andere Methoden übernommen.
(1)Taiko
· Taiko speichert den Block-Hash-Wert jeder Kette. Für jedes Kettenpaar werden zwei Smart Contracts eingesetzt, die die Hashes des jeweils anderen speichern. Im Fall von L2←→L1 wird jedes Mal, wenn ein L2-Block auf Taiko erstellt wird, der Hash des umgebenden Blocks auf L1 im TaikoL2-Vertrag gespeichert. Die gleiche Operationsmethode wird im Fall von L1←→L2 verwendet.
· Die neueste bekannte Merkle-Wurzel, die in der Zielkette gespeichert ist, kann durch Aufrufen von getCrossChainBlockHash(0) im TaikoL1/TaikoL2-Vertrag abgerufen und der zu überprüfende Wert/die Nachricht abgerufen werden. Der neueste bekannte Geschwister-Hash der Merkle-Wurzel kann durch Aufrufen der eth_getProof-Anfrage mithilfe von Standard-RPC in der „Origin-Kette“ abgerufen werden.
· Senden Sie sie dann einfach zur Überprüfung anhand des neuesten bekannten Block-Hashs, der in einer Liste in der „Zielkette“ gespeichert ist. Der Validator nimmt einen Wert (ein Blatt im Merkle-Baum) und den Geschwister-Hash, um die Merkle-Wurzel neu zu berechnen und zu prüfen, ob sie mit der Wurzel übereinstimmt, die in der Liste der Block-Hashes der Zielkette gespeichert ist.
(2) Starknet
Starknet verwendet einen Speichernachweis für vertrauenswürdige kettenübergreifende Nachrichtenübermittlung.
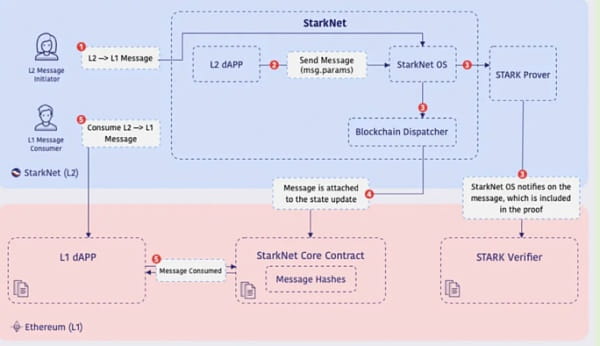
L2→L1-Nachrichtenprotokoll
· Während der Ausführung einer Starknet-Transaktion sendet der Vertrag auf Starknet eine L2→L1-Nachricht.
· Hängen Sie dann die Nachrichtenparameter (die den Empfängervertrag und zugehörige Daten auf L1 enthalten) an die entsprechende Statusaktualisierung (Hauptspeicherbaum) an.
· L2-Nachrichten werden auf L1 des Smart Contracts gespeichert.
· Ein Ereignis auf L1 ausgeben (Nachrichtenparameter speichern).
· Die Empfängeradresse auf L1 kann auf die Nachricht zugreifen und sie als Teil der L1-Transaktion verwenden, indem sie die Nachrichtenparameter erneut bereitstellt.
· Kettenübergreifende Nachrichten werden im Backbone-Baum gespeichert.
L2 → L1
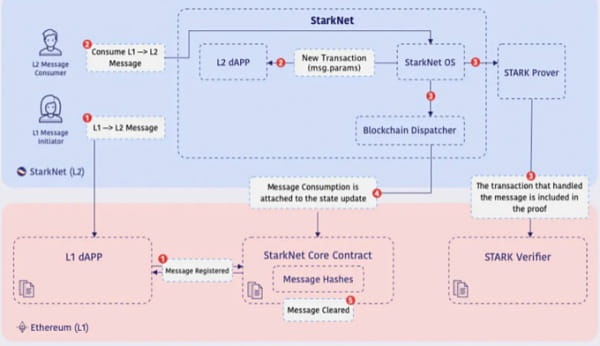
L1 → L2
(3) Optimismus
· Die Kommunikation zwischen L1 und L2 wird durch zwei spezielle Smart Contracts namens „Messenger“ erreicht.
· Für Transaktionen von Optimism (L2) zu Ethereum (L1) ist es notwendig, einen Merkle-Beweis für die Nachricht auf L1 bereitzustellen, nachdem die Statuswurzel geschrieben wurde. Nachdem die Proof-Transaktion Teil der L1-Kette geworden ist, beginnt der Fehler-Challenge-Zeitraum. Nach dieser Wartezeit kann jeder Benutzer die Transaktion „abschließen“, indem er eine zweite Transaktion auf Ethereum auslöst und die Nachricht an den Ziel-L1-Vertrag sendet.
· Kettenübergreifende Nachrichten werden im Backbone-Baum gespeichert.
(4) Schiedsverfahren
· Wiederholbare Tickets sind Arbitrums kanonische Methode zum Erstellen von L1-zu-L2-Nachrichten, d. h. L1-Transaktionen, die Nachrichten initialisieren, die auf L2 ausgeführt werden sollen. Ein Retryable kann auf L1 gegen eine feste Gebühr übermittelt werden (abhängig nur von der Anrufdatengröße). Der Hauptzustandsbaum wird für die kettenübergreifende Kommunikation benutzerdefinierter Datenformate in Smart Contracts verwendet. Das Senden eines wiederholbaren Tickets auf L1 kann von der Ausführung auf L2 entkoppelt/asynchron sein. Retryables sorgen für Atomizität zwischen kettenübergreifenden Vorgängen. Wenn die L1-Transaktionsanforderung erfolgreich übermittelt wird (d. h. es erfolgt kein Rollback), besteht eine starke Garantie dafür, dass die wiederholbare Ausführung auf L2 letztendlich erfolgreich sein wird.
· Arbitrum hat zwei Stämme: Die Nitro-Kette wird im Zustandsbaumformat von Ethereum verwaltet, bei dem es sich um einen Merkle-Baum handelt. Der Assertion Tree speichert den Zustand der Arbitrum-Kette, der auf Ethereum durch „Assertion“ bestätigt wurde. Die Regeln für die Weiterentwicklung der Arbitrum-Kette sind deterministisch. Das bedeutet, dass es angesichts des Status einer Kette und einiger neuer Eingabewerte nur eine gültige Ausgabe gibt. Wenn der Beweisbaum mehrere Blätter enthält, kann daher höchstens ein Blatt einen gültigen Kettenzustand darstellen.
· Das Postausgangssystem von Arbitrum ermöglicht jeden Vertragsaufruf von L2 zu L1, d. h. eine Nachricht wird von L2 initiiert und schließlich auf L1 ausgeführt. L2-zu-L1-Nachrichten (auch „ausgehende Nachrichten“ genannt) haben viele Gemeinsamkeiten mit den L1-zu-L2-Nachrichten (wiederholbar) von Arbitrum, obwohl es einige bemerkenswerte Unterschiede gibt. Ein Teil des L2-Status der Arbitrum-Kette – der Teil, der in jedem RBlock attestiert wird – ist die Merkle-Wurzel aller L2- bis L1-Nachrichten im Verlauf der Kette. Nachdem der bewährte RBlock bestätigt wurde (normalerweise etwa eine Woche nach dem Nachweis), wird der im Outbox-Vertrag enthaltene Merkle-Stamm auf L1 veröffentlicht. Der Outbox-Vertrag ermöglicht es Benutzern dann, ihre Nachrichten auszuführen.
(5) Polygon zkEVM
· Der Bridge SC des zkEVM verwendet einen speziellen Merkle-Baum namens Exit Tree für jedes Netzwerk, das an Kommunikations- oder Asset-Transaktionen teilnimmt.
· Es verwendet Merkle-Wurzeln (in einem separaten Zustandsbaum) und ein Brückenarchitekturdiagramm finden Sie auf Github.
· Der Einsatz von zkEVM Bridge SC hat auf der Grundlage des Ethereum 2.0-Einzahlungsvertrags mehrere Änderungen vorgenommen. Es verwendet beispielsweise einen speziell entwickelten Merkle-Baum, der nur zum Anhängen dient, übernimmt aber die gleiche Logik wie der Ethereum 2.0-Einzahlungsvertrag. Weitere Unterschiede beziehen sich auf Basis-Hashes und Blattknoten.
· Das Hauptmerkmal des Polygon zkEVM Bridge-Smart-Vertrags ist die Verwendung von Exit Tree und globalem Exit Tree, wobei die Wurzel des globalen Exit Tree die Hauptquelle des Wahrheitsstatus ist. Es gibt also zwei verschiedene globale Exit-Root-Manager für L1 und L2 und eine separate Logik für Bridge SC.
(6)Scrollen
· Der auf Ethereum und Scroll bereitgestellte Bridge-Vertrag ermöglicht es Benutzern, beliebige Nachrichten zwischen L1 und L2 zu übertragen. Zusätzlich zu diesem Messaging-Protokoll haben wir auch ein vertrauenswürdiges Bridging-Protokoll entwickelt, um Benutzern die Überbrückung von ERC-20-Assets zwischen L1 und L2 zu ermöglichen. Um eine Nachricht oder Geld von Ethereum an Scroll zu senden, ruft der Benutzer die sendMessage-Transaktion im Bridge-Vertrag auf. Das Relay indiziert diese Transaktion auf L1 und sendet sie zur Aufnahme in den L2-Block an den Sequenzer. Beim L2-Bridge-Vertrag ist der Vorgang des Sendens von Nachrichten von Scroll zurück zu Ethereum ähnlich.
· Kettenübergreifende Nachrichten werden in regulären Nachrichtenwarteschlangen gespeichert. Der Sequenzer nimmt kettenübergreifende Nachrichten aus dieser Warteschlange auf und fügt sie als reguläre Transaktionen zur Kette hinzu.
(7)zksync-Ära
Haftungsausschluss: In diesem Abschnitt geht es nur um die zksync-Ära und kann sich vom kettenübergreifenden Messaging auf ZK Stack unterscheiden, einem modularen Framework zum Aufbau souveräner ZK-Superchains.
· Jedes Transaktionspaket verfügt über eine separate L2->L1-Nachricht.
· Es ist nicht möglich, Transaktionen direkt von L2 nach L1 zu senden. Sie können jedoch von zkSync Era Nachrichten beliebiger Länge an Ethereum senden und dann L1-Smart Contracts verwenden, um die empfangenen Nachrichten auf Ethereum zu verarbeiten. zkSync Era verfügt über eine Anforderungsnachweisfunktion, die einen booleschen Parameter zurückgibt, der angibt, ob die Nachricht erfolgreich an L1 gesendet wurde. Rufen Sie den in der Nachricht enthaltenen Merkle-Beweis ab, indem Sie ihn auf Ethereum beobachten oder die zks_getL2ToL1LogProof-Methode der zksync-web3-API verwenden.
· Für L1→L2 ermöglicht der zkSync Era-Smart-Vertrag dem Absender, eine Transaktion auf Ethereum L1 anzufordern und die Daten an zkSync Era L2 weiterzuleiten.
· Brückenvertrag: https://github.com/matter-labs/era-contracts/blob/main/ethereum/contracts/bridge/L1ERC20Bridge.sol
4. Fazit
Die kettenübergreifende Kommunikation ist für „unverzichtbare“ Anwendungen für die Masseneinführung von Blockchain unverzichtbar (z. B. die in Buterins Artikel beschriebene kettenübergreifende Social-Recovery-Wallet). Die meisten derzeit verwendeten kettenübergreifenden Lösungen sind für L1←→L2 konzipiert, um die Auszahlungsfunktionalität abzudecken. Diese Lösungen können auf weitere Blockchains erweitert werden. Gleichzeitig können jedoch fortschrittlichere kettenübergreifende Kommunikationslösungen implementiert werden, z. B. „Direct Read State“, für den überhaupt kein Beweis erforderlich ist, oder „Storage Proof“, für den kein Vertrauen erforderlich ist. Für die meisten L2s gibt es noch Raum für Entwicklung und Fortschritt in der kettenübergreifenden Kommunikation.