
Wichtigste Erkenntnisse
Binance nutzt das Kapazitätsmanagement für ungeplante Verkehrsspitzen, die durch hohe Volatilität verursacht werden, und stellt so angemessene, zeitnahe Infrastruktur- und Rechenressourcen für die Geschäftsanforderungen sicher.
Binance führt Lasttests in der Produktionsumgebung (anstatt in einer Staging-Umgebung) durch, um genaue Service-Benchmarks zu erhalten. Mit dieser Methode können wir überprüfen, ob unsere Ressourcenzuweisung ausreicht, um eine bestimmte Last zu bewältigen.
Die Infrastruktur von Binance bewältigt große Datenmengen. Um einen Dienst aufrechtzuerhalten, auf den sich die Benutzer verlassen können, sind ein angemessenes Kapazitätsmanagement und automatische Belastungstests erforderlich.

Warum benötigt Binance einen speziellen Kapazitätsmanagementprozess?
Kapazitätsmanagement ist ein Grundpfeiler der Systemstabilität. Es beinhaltet die richtige Dimensionierung von Anwendungs- und Infrastrukturressourcen mit aktuellen und zukünftigen Geschäftsanforderungen zu den richtigen Kosten. Um dieses Ziel zu erreichen, entwickeln wir Kapazitätsmanagement-Tools und -Pipelines, um Überlastungen zu vermeiden und Unternehmen dabei zu helfen, ein reibungsloses Benutzererlebnis zu bieten.
Kryptowährungsmärkte sind häufig mit regelmäßigeren Volatilitätsperioden konfrontiert als traditionelle Finanzmärkte. Das bedeutet, dass das System von Binance diesen Verkehrsanstieg von Zeit zu Zeit aushalten muss, da Benutzer auf Marktbewegungen reagieren. Mit einem angemessenen Kapazitätsmanagement halten wir die Kapazität für die allgemeine Geschäftsnachfrage und diese Szenarien mit Verkehrsanstieg ausreichend. Genau dieser wichtige Punkt macht die Kapazitätsmanagementprozesse von Binance einzigartig und herausfordernd.
Schauen wir uns die Faktoren an, die den Prozess häufig behindern und zu einem langsamen oder nicht verfügbaren Dienst führen. Zunächst haben wir eine Überlastung, die normalerweise durch einen plötzlichen Anstieg des Datenverkehrs verursacht wird. Dies kann beispielsweise durch ein Marketingereignis, eine Push-Benachrichtigung oder sogar einen DDoS-Angriff (Distributed Denial of Service) verursacht werden.
Übermäßiges Verkehrsaufkommen und unzureichende Kapazität beeinträchtigen die Systemfunktionalität wie folgt:
Der Service übernimmt immer mehr Arbeit.
Die Antwortzeit erhöht sich bis zu dem Punkt, an dem innerhalb des Timeouts des Clients auf keine Anfrage mehr geantwortet werden kann. Diese Verschlechterung tritt normalerweise aufgrund einer Ressourcensättigung (CPU, Speicher, IO, Netzwerk usw.) oder längerer GC-Pausen im Dienst selbst oder seinen Abhängigkeiten auf.
Dies hat zur Folge, dass der Dienst Anfragen nicht zeitnah verarbeiten kann.
Den Prozess aufschlüsseln
Nachdem wir nun das allgemeine Prinzip des Kapazitätsmanagements besprochen haben, schauen wir uns an, wie Binance dies auf sein Geschäft anwendet. Hier ist ein Blick auf die Architektur unseres Kapazitätsmanagementsystems mit einigen wichtigen Arbeitsabläufen.
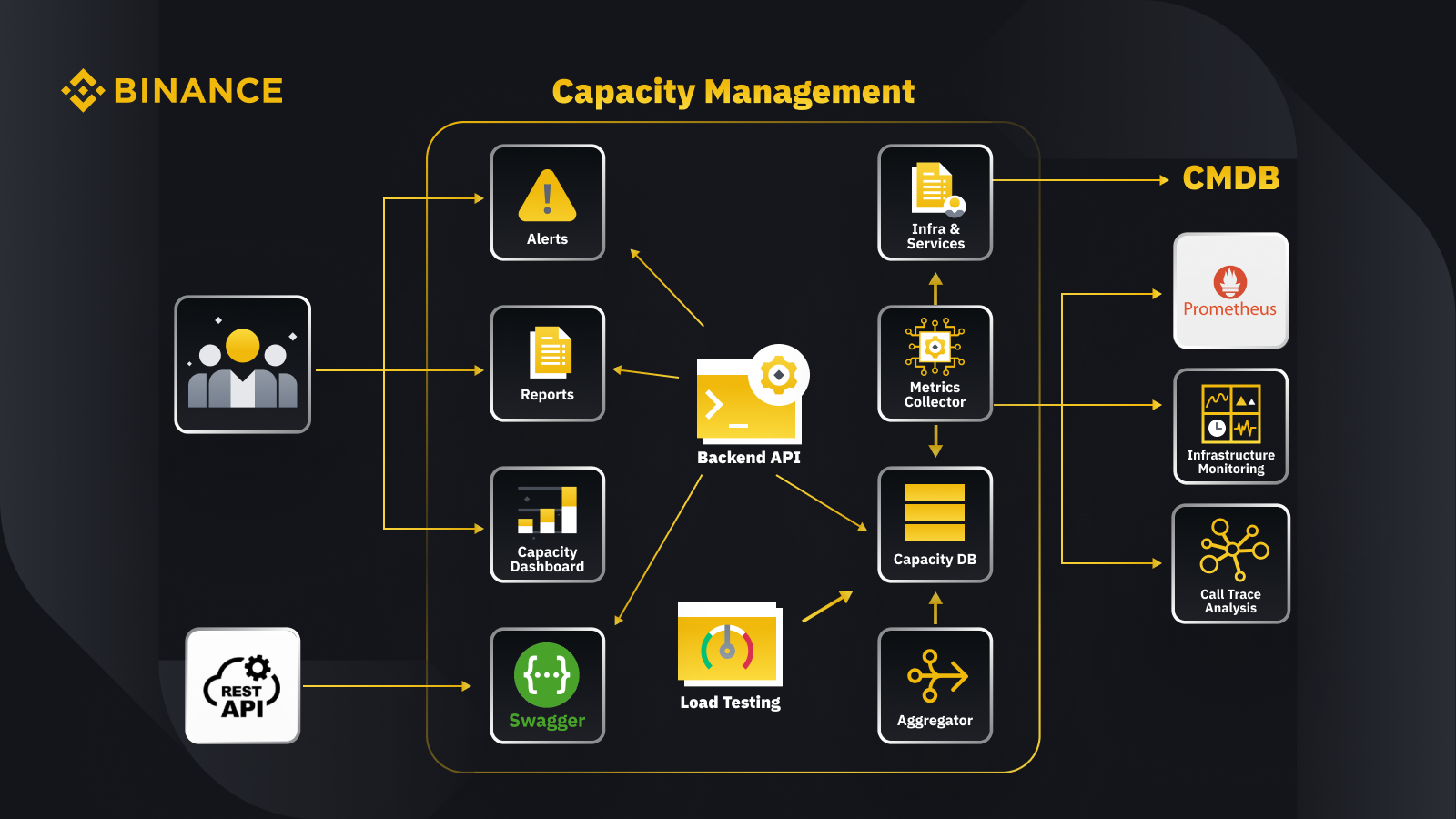
Indem wir Daten aus der Konfigurationsmanagementdatenbank (CMDB) abrufen, generieren wir die Infrastruktur- und Servicekonfigurationen. Die Elemente in diesen Konfigurationen sind die Kapazitätsmanagementobjekte.
Der Metrik-Sammler ruft Kapazitätsmetriken von Prometheus für die Daten der Geschäfts- und Serviceschicht, von Infrastructure Monitoring für Metriken der Ressourcenschicht und vom Call-Trace-Analysesystem für Trace-Informationen ab. Der Metrik-Sammler speichert die Daten in der Kapazitätsdatenbank (CDB).
Das Lasttestsystem führt Stresstests für die Dienste durch und speichert die Benchmarkdaten in der CDB.
Der Aggregator ruft die Kapazitätsdaten von CDB ab und aggregiert sie für die Dimensionen „Tages“ und „Allzeithoch“ (ATH). Nach der Aggregation schreibt er die aggregierten Daten zurück in die CDB.
Durch die Verarbeitung der Daten aus der CDB stellt die Backend-API Schnittstellen für das Kapazitäts-Dashboard, Warnungen und Berichte sowie die Rest-API und zugehörige Kapazitätsdaten zur Integration bereit.
Stakeholder erhalten Einblicke in die Kapazität über das Kapazitäts-Dashboard, Warnungen und Berichte. Sie können auch andere verwandte Systeme verwenden, einschließlich der Überwachung von Kapazitätsdaten von Diensten mit der Rest-API, die vom Kapazitätsmanagementsystem mit Swagger bereitgestellt wird.
Strategie
Unsere Strategie für Kapazitätsmanagement und -planung basiert auf spitzengesteuerter Verarbeitung. Spitzengesteuerte Verarbeitung ist die Arbeitslast, die die Ressourcen eines Dienstes (Webserver, Datenbanken usw.) während der Spitzenauslastung erfahren.
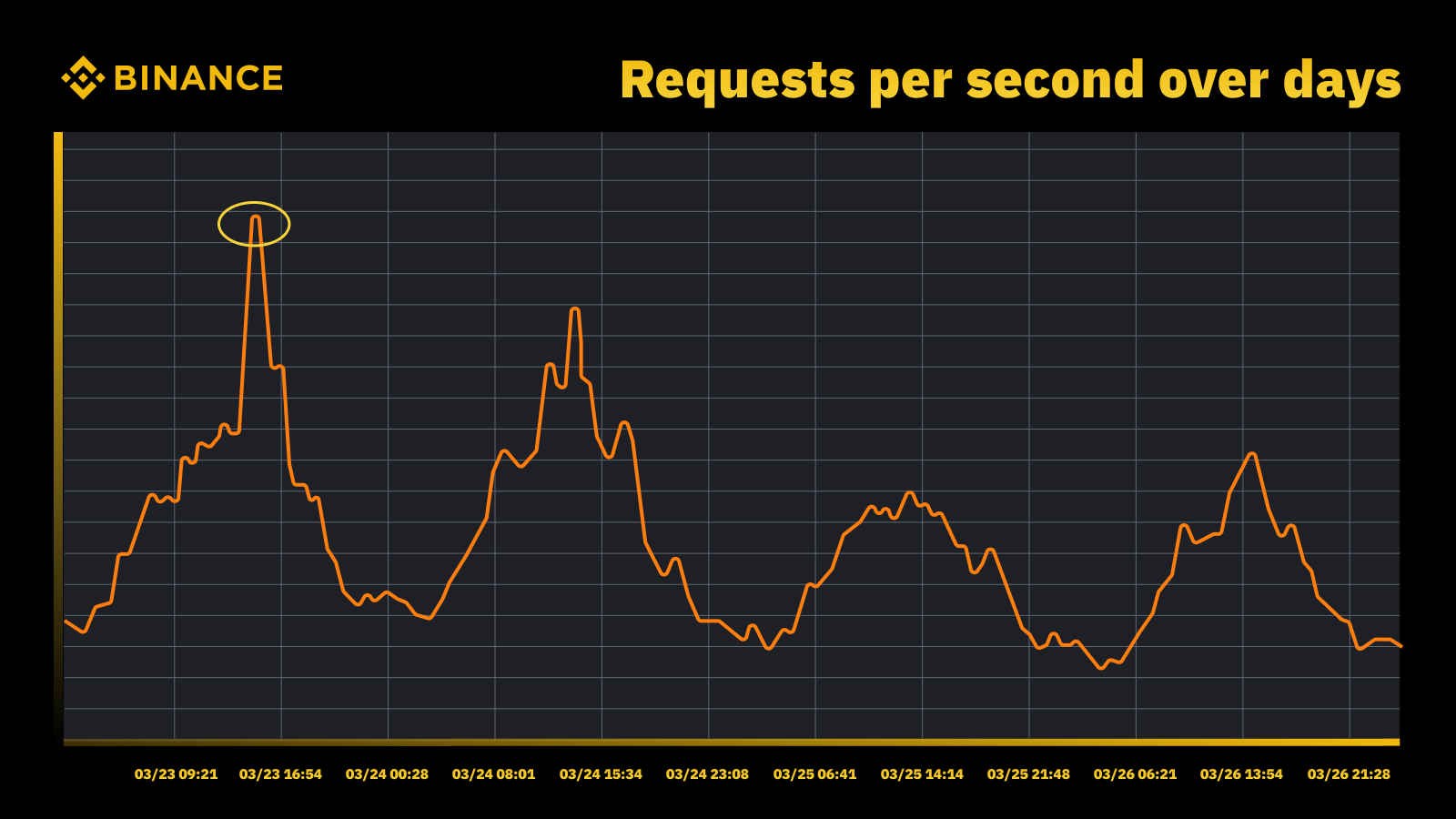
Verkehrsanstieg nach Zinserhöhung der Fed im März 2023
Wir analysieren die periodischen Spitzen und nutzen sie, um die Kapazitätsentwicklung zu steuern. Wie bei jeder spitzengetriebenen Ressource wollen wir herausfinden, wann die Spitzen auftreten, und dann untersuchen, was während dieser Zyklen tatsächlich passiert.
Ein weiterer wichtiger Punkt, den wir neben der Vermeidung von Überlastungen berücksichtigen, ist die automatische Skalierung. Die automatische Skalierung bewältigt Überlastungen, indem die Kapazität mit mehr Instanzen des Dienstes dynamisch erhöht wird. Überschüssiger Datenverkehr wird dann verteilt, und der Datenverkehr, den eine einzelne Instanz des Dienstes (oder eine Abhängigkeit) bewältigt, bleibt beherrschbar.
Autoscaling hat seine Berechtigung, kann Überlastungssituationen jedoch nicht allein bewältigen. Normalerweise kann es nicht schnell genug auf einen plötzlichen Anstieg des Datenverkehrs reagieren und funktioniert nur dann optimal, wenn der Datenverkehr allmählich zunimmt.
Messung
Messungen spielen bei Binances Kapazitätsmanagement eine entscheidende Rolle, und das Sammeln von Daten ist unser erster Messschritt. Basierend auf den Standards der Information Technology Infrastructure Library (ITIL) sammeln wir Daten zur Messung in den Teilprozessen des Kapazitätsmanagements, nämlich:
Ressourcen – Ressourcenverbrauch der IT-Infrastruktur, getrieben durch die Nutzung von Anwendungen/Diensten. Konzentriert sich auf interne Leistungsmetriken physischer und virtueller Computerressourcen, einschließlich Server-CPU, Arbeitsspeicher, Festplattenspeicher, Netzwerkbandbreite usw.
Service. Die Leistungs-, SLA-, Latenz- und Durchsatzmaße auf Anwendungsebene, die sich aus Geschäftsaktivitäten ergeben. Konzentriert sich auf externe Leistungsmetriken, die auf der Wahrnehmung des Service durch Benutzer basieren, einschließlich Servicelatenz, Durchsatz, Spitzen usw.
Geschäftlich. Sammelt Daten, die die von der Zielanwendung verarbeiteten Geschäftsaktivitäten messen, einschließlich Bestellungen, Benutzerregistrierung, Zahlungen usw.
Kapazitätsmanagement, das ausschließlich auf der Auslastung der Infrastrukturressourcen basiert, führt zu ungenauen Planungen. Dies liegt daran, dass es möglicherweise nicht das tatsächliche Geschäftsvolumen und den Durchsatz widerspiegelt, die unsere Infrastrukturkapazität bestimmen.
Geplante Veranstaltungen bieten eine hervorragende Möglichkeit, dies weiter zu diskutieren. Nehmen Sie am Watch Web Summit 2022 auf Binance Live teil, um bis zu 15.000 BUSD in der Crypto Box Rewards-Kampagne zu teilen. Abgesehen von den zugrunde liegenden Ressourcen- und Service-Layer-Metriken mussten wir auch das Geschäftsvolumen berücksichtigen. Wir haben die Kapazitätsplanung hier auf Geschäftsmetriken wie der geschätzten Anzahl der Live-Stream-Zuschauer, der maximalen Anzahl laufender Anfragen für eine Crypto Box, der End-to-End-Latenz und anderen Faktoren basiert.
Nach der Datenerfassung aggregieren und fassen unsere Kapazitätsmanagementprozesse die zahlreichen Datenpunkte zusammen, die für einen bestimmten Kapazitätstreiber erfasst wurden. Der aggregierte Wert einer Metrik ist ein einzelner Wert, der für Kapazitätswarnungen, Berichte und andere kapazitätsbezogene Funktionen verwendet werden kann.
Wir können verschiedene Datenaggregationsmethoden auf periodische Datenpunkte anwenden, etwa Summe, Durchschnitt, Median, Minimum, Maximum, Perzentil und Allzeithoch (ATH).

Unsere gewählte Methode bestimmt unsere Ergebnisse aus dem Kapazitätsmanagementprozess und die daraus resultierenden Entscheidungen. Wir wählen unterschiedliche Methoden basierend auf unterschiedlichen Szenarien aus. Beispielsweise verwenden wir die Maximummethode für kritische Dienste und zugehörige Datenpunkte. Um den höchsten Datenverkehr aufzuzeichnen, verwenden wir die ATH-Methode.
Für verschiedene Anwendungsfälle verwenden wir unterschiedliche Granularitätstypen zur Datenaggregation. In den meisten Fällen verwenden wir entweder Minute, Stunde, Tag oder ATH.
Wir messen die Arbeitslast eines Dienstes bis ins kleinste Detail, um rechtzeitig vor Überlastungen zu warnen.
Wir verwenden stündlich aggregierte Daten, um Tagesdaten aufzubauen, und aggregieren die stündlichen Daten, um den Tagesspitzenwert aufzuzeichnen.
Normalerweise verwenden wir tägliche Daten für Kapazitätsberichte und nutzen ATH-Daten für die Kapazitätsmodellierung und -planung.
Eine der Kernmetriken des Kapazitätsmanagements ist das Service-Benchmarking. Damit können wir die Serviceleistung und -kapazität genau messen. Den Service-Benchmark erhalten wir durch Belastungstests. Später werden wir uns näher damit befassen.
Kapazitätsmanagement basierend auf Priorität
Bisher haben wir gesehen, wie wir Kapazitätsmetriken erfassen und Daten in verschiedenen Granularitätstypen aggregieren. Ein weiterer wichtiger zu besprechender Bereich ist die Priorität, die im Zusammenhang mit Warnmeldungen und Kapazitätsberichten hilfreich ist. Nach der Rangfolge der IT-Assets werden begrenzte Infrastrukturnutzung und Computerressourcen priorisiert und zuerst kritischen Diensten und Aktivitäten zugewiesen.
Es gibt verschiedene Möglichkeiten, die Kritikalität von Diensten und Anfragen zu definieren. Eine nützliche Referenz ist Google. Im SRE-Buch werden die Kritikalitätsstufen als CRITICAL_PLUS, CRITICAL, SHEDDABLE_PLUS usw. definiert. In ähnlicher Weise definieren wir mehrere Prioritätsstufen wie P0, P1, P2 usw.
Wir definieren die Prioritätsstufen wie folgt:
P0: Für die kritischsten Dienste und Anforderungen, also diejenigen, deren Ausfall schwerwiegende, für den Benutzer sichtbare Auswirkungen zur Folge hat.
P1: Für jene Dienste und Anfragen, die für den Benutzer sichtbare Auswirkungen haben, die jedoch geringer sind als bei P0. Für P0- und P1-Dienste wird erwartet, dass sie mit ausreichend Kapazität bereitgestellt werden.
P2: Dies ist die Standardpriorität für Batch- und Offline-Jobs. Wenn diese Dienste und Anfragen teilweise nicht verfügbar sind, haben sie möglicherweise keine für den Benutzer sichtbaren Auswirkungen.
Was ist ein Belastungstest und warum verwenden wir ihn in einer Produktionsumgebung?
Lasttests sind nicht-funktionale Softwaretestverfahren, bei denen die Leistung einer Anwendung unter einer bestimmten Arbeitslast getestet wird. So lässt sich ermitteln, wie sich die Anwendung verhält, wenn mehrere Endbenutzer gleichzeitig darauf zugreifen.
Bei Binance haben wir eine Lösung entwickelt, die es uns ermöglicht, Belastungstests in der Produktion durchzuführen. Normalerweise werden Belastungstests in einer Staging-Umgebung durchgeführt, aber aufgrund unserer allgemeinen Kapazitätsmanagementziele konnten wir diese Option nicht nutzen. Belastungstests in einer Produktionsumgebung ermöglichten uns Folgendes:
Sammeln Sie einen genauen Benchmark unserer Dienste unter realen Belastungsbedingungen.
Steigern Sie das Vertrauen in das System und seine Zuverlässigkeit und Leistung.
Identifizieren Sie Engpässe im System, bevor sie in der Produktionsumgebung auftreten.
Ermöglichen Sie eine kontinuierliche Überwachung von Produktionsumgebungen.
Ermöglichen Sie proaktives Kapazitätsmanagement mit regelmäßig stattfindenden normalisierten Testzyklen.
Nachfolgend sehen Sie unser Framework für Belastungstests mit einigen wichtigen Erkenntnissen:

Das Microservice-Framework von Binance verfügt über eine Basisschicht zur Unterstützung der konfigurationsgesteuerten und flaggenbasierten Verkehrsführung, die für unseren TIP-Ansatz von wesentlicher Bedeutung ist.
Zur Bewertung der von uns getesteten Instanz wird eine automatisierte Canary-Analyse (ACA) durchgeführt. Dabei werden die im Überwachungssystem erfassten Schlüsselmetriken verglichen, sodass wir den Test bei unerwarteten Problemen unterbrechen/beenden können, um die Auswirkungen auf die Benutzer zu minimieren.
Während des Belastungstests werden Benchmarks und Metriken erfasst, um Dateneinblicke in Bezug auf Verhalten und Anwendungsleistung zu generieren.
APIs werden bereitgestellt, um wertvolle Leistungsdaten in verschiedenen Szenarien auszutauschen, beispielsweise bei Kapazitätsmanagement und Qualitätssicherung. Dies trägt zum Aufbau eines offenen Ökosystems bei.
Wir erstellen Automatisierungs-Workflows, um alle Schritte und Kontrollpunkte aus einer End-to-End-Testperspektive zu orchestrieren. Wir bieten auch die Flexibilität der Integration mit anderen Systemen, wie z.
Unser Test-in-Production-Ansatz (TIP)
Ein herkömmlicher Ansatz für Leistungstests (Ausführen von Tests in einer Staging-Umgebung mit simuliertem oder gespiegeltem Datenverkehr) bietet einige Vorteile. Die Bereitstellung einer produktionsähnlichen Staging-Umgebung hat in unserem Kontext jedoch mehr Nachteile:
Dadurch verdoppeln sich fast die Infrastrukturkosten und der Wartungsaufwand.
Es ist unglaublich komplex, das End-to-End in der Produktion zum Laufen zu bringen, insbesondere in einer großen Microservices-Umgebung über mehrere Geschäftseinheiten hinweg.
Dadurch werden die Datenschutz- und Sicherheitsrisiken erhöht, da wir bei der Bereitstellung unter Umständen zwangsläufig Daten duplizieren müssen.
Simulierter Datenverkehr kann nie das tatsächliche Produktionsgeschehen reproduzieren. Der in der Staging-Umgebung ermittelte Benchmark wäre ungenau und weniger aussagekräftig.
Testing in Production, auch bekannt als TIP, ist eine Shift-Right-Testmethode, bei der neuer Code, neue Funktionen und Releases in der Produktionsumgebung getestet werden. Die von uns eingeführten Lasttests in der Produktion sind äußerst nützlich, da sie uns helfen:
Analysieren Sie die Stabilität und Robustheit des Systems.
Entdecken Sie Benchmarks und Engpässe von Anwendungen bei unterschiedlichem Datenverkehr, unterschiedlichen Serverspezifikationen und unterschiedlichen Anwendungsparametern.
FlowFlag-basiertes Routing
Unser FlowFlag-basiertes Routing, das in das Microservice-Basisframework eingebettet ist, ist die Grundlage, die TIP ermöglicht. Dies gilt für bestimmte Fälle, einschließlich Anwendungen, die Eureka Service Discovery zur Verkehrsverteilung verwenden.
Wie im Diagramm dargestellt, kennzeichnet der Binance-Webserver als Einstiegspunkt einen bestimmten Prozentsatz des Datenverkehrs, wie in den Konfigurationen mit FlowFlag-Headern angegeben. Während des Belastungstests können wir einen Host eines bestimmten Dienstes auswählen und ihn in den Konfigurationen als Zielleistungsinstanz markieren. Anschließend werden diese gekennzeichneten Leistungsanforderungen schließlich an die Leistungsinstanz weitergeleitet, wenn sie den Dienst zur Verarbeitung erreichen.
Es ist vollständig konfigurationsgesteuert und mit Hot-Loading können wir den Prozentsatz der Arbeitslast mithilfe der Automatisierung problemlos anpassen, ohne eine neue Version bereitstellen zu müssen
Es kann auf die meisten unserer Dienste angewendet werden, da der Mechanismus Teil des Gateways und des Basispakets ist
Ein einziger Änderungspunkt ermöglicht außerdem ein einfaches Rollback, um Risiken in der Produktion zu verringern.

Während wir unsere Lösung stärker Cloud-nativ gestalten, erkunden wir auch, wie wir einen ähnlichen Ansatz aufbauen können, um andere Verkehrsweiterleitungen zu unterstützen, die von öffentlichen Cloud-Anbietern oder Kubernetes angeboten werden.
Automatisierte Canary-Analyse zur Minimierung von Benutzerauswirkungsrisiken
Canary-Bereitstellung ist eine Bereitstellungsstrategie, um das Risiko bei der Bereitstellung einer neuen Softwareversion in der Produktion zu verringern. Dabei wird normalerweise eine neue Version der Software (ein sogenannter Canary Release) neben der stabil laufenden Version für eine kleine Untergruppe von Benutzern bereitgestellt. Anschließend teilen wir den Datenverkehr zwischen den beiden Versionen auf, sodass ein Teil der eingehenden Anfragen an den Canary umgeleitet wird.
Die Qualität der Canary-Version wird dann durch eine sogenannte Canary-Analyse beurteilt. Dabei werden wichtige Kennzahlen verglichen, die das Verhalten der alten und neuen Version beschreiben. Wenn es zu einer deutlichen Verschlechterung der Kennzahlen kommt, wird der Canary abgebrochen und der gesamte Datenverkehr auf die stabile Version umgeleitet, um die Auswirkungen unerwarteten Verhaltens zu minimieren.
Wir verwenden dasselbe Konzept zum Erstellen unserer Lösung für automatische Lasttests. Die Lösung verwendet die Kayenta-Plattform für die automatisierte Canary-Analyse (ACA) über Spinnaker, um automatisierte Canary-Bereitstellungen zu ermöglichen. Unser typischer Lasttestablauf bei Befolgung dieser Methode sieht folgendermaßen aus:
Durch den Workflow erhöhen wir die Verkehrslast (z. B. 5 %, 10 %, 25 %, 50 %) schrittweise zum Zielhost, wie angegeben oder bis die Belastungsgrenze erreicht ist.
Bei jeder Belastung wird die Canary-Analyse mit Kayenta für eine bestimmte Zeit (z. B. 5 Minuten) wiederholt ausgeführt, um die wichtigsten Kennzahlen des getesteten Hosts mit der Zeit vor der Belastung als Basislinie und der aktuellen Zeit nach der Belastung als Experiment zu vergleichen.
Der Vergleich (Canary-Konfigurationsmodell) konzentriert sich darauf, zu überprüfen, ob der Zielhost:
Erreicht Ressourcenbeschränkungen, d. h. die CPU-Auslastung übersteigt 90 %.
Weist einen erheblichen Anstieg der Fehlermetriken auf, z. B. Fehlerprotokolle, HTTP-Ausnahmen oder Ablehnungen aufgrund von Ratenbegrenzungen.
Die Kernanwendungsmetriken sind immer noch angemessen, z. B. eine HTTP-Latenz von weniger als 2 Sekunden (für jeden Dienst anpassbar)
Für jede Analyse gibt uns Kayenta einen Bericht mit dem Ergebnis und der Test wird bei einem Fehler sofort beendet.
Diese Fehlererkennung dauert normalerweise weniger als 30 Sekunden, wodurch die Wahrscheinlichkeit einer Beeinträchtigung der Erfahrung unserer Endbenutzer erheblich reduziert wird.

Dateneinblicke aktivieren
Es ist wichtig, ausreichend Informationen über alle zuvor beschriebenen Prozesse und Testausführungen zu sammeln. Das ultimative Ziel besteht darin, die Zuverlässigkeit und Robustheit unseres Systems zu verbessern, was ohne Dateneinblicke unmöglich ist.
Eine Gesamttestzusammenfassung erfasst den maximalen Lastprozentsatz, den der Host verarbeiten konnte, die maximale CPU-Auslastung und die QPS des Hosts. Auf dieser Grundlage wird auch die Anzahl der Instanzen geschätzt, die wir möglicherweise bereitstellen müssen, um unsere Kapazitätsreservierung zu erfüllen, unter Berücksichtigung der höchsten QPS der Dienste aller Zeiten.
Weitere wertvolle Informationen für die Analyse sind die Softwareversion, die Serverspezifikation, die Anzahl der Bereitstellungen und ein Link zum Monitor-Dashboard, wo wir zurückverfolgen können, was während des Tests passiert ist.

Eine Benchmark-Kurve zeigt, wie sich die Leistung in den letzten drei Monaten verändert hat, sodass wir mögliche Probleme im Zusammenhang mit einer bestimmten Anwendungsversion erkennen können.

CPU- und QPS-Trends zeigen, wie die CPU-Auslastung mit dem Anforderungsvolumen korreliert, das der Server verarbeiten musste. Diese Metrik kann dabei helfen, die Serverreserven für das Wachstum des eingehenden Datenverkehrs abzuschätzen.
Das API-Latenzverhalten erfasst, wie die Antwortzeit unter verschiedenen Lastbedingungen für die fünf wichtigsten APIs variiert. Wir können das System dann bei Bedarf auf individueller API-Ebene optimieren.

Metriken zur API-Lastverteilung helfen uns zu verstehen, wie sich die API-Zusammensetzung auf die Serviceleistung auswirkt, und geben mehr Einblick in Verbesserungsbereiche.
Normalisierung und Produktisierung
Während unser System weiter wächst und sich weiterentwickelt, werden wir die Stabilität und Zuverlässigkeit unserer Dienste weiterhin überwachen und verbessern. Dies werden wir folgendermaßen tun:
Ein regelmäßiger und etablierter Belastungstestplan für kritische Dienste.
Automatische Belastungstests als Teil unserer CI/CD-Pipelines.
Verstärkte Produktisierung der gesamten Lösung zur Vorbereitung auf eine großflächige Einführung in der gesamten Organisation.
Einschränkungen
Der aktuelle Ansatz für Belastungstests weist einige Einschränkungen auf:
Das FlowFlag-basierte Routing ist nur auf unser Microservice-Framework anwendbar. Wir möchten die Lösung auf weitere Routing-Szenarien ausweiten, indem wir die gemeinsame gewichtete Routing-Funktion von Cloud Load Balancern oder einem Kubernetes Ingress nutzen.
Da wir den Test auf realen Benutzerverkehr in der Produktion basieren, können wir keine Funktionstests für bestimmte APIs oder Anwendungsfälle durchführen. Außerdem wäre der Wert für Dienste mit sehr geringem Volumen begrenzt, da wir möglicherweise den Engpass nicht identifizieren können.
Wir führen diese Tests für einzelne Dienste durch, anstatt End-to-End-Anrufketten abzudecken.
Tests in der Produktion können bei auftretenden Fehlern manchmal Auswirkungen auf echte Benutzer haben. Daher müssen wir über Fehleranalyse und automatisches Rollback mit vollständigen Automatisierungsfunktionen verfügen.
Abschließende Gedanken
Für uns ist es wichtig, Szenarien mit hohem Datenverkehr zu berücksichtigen, um eine Systemüberlastung zu verhindern und die Verfügbarkeit sicherzustellen. Aus diesem Grund haben wir die in diesem Artikel beschriebenen Kapazitätsmanagement- und Lasttestprozesse entwickelt. Zusammengefasst:
Unser Kapazitätsmanagement ist spitzengesteuert und in jede Phase des Service-Lebenszyklus eingebettet. Es verhindert Überlastungen durch Aktivitäten wie Messung, Einrichten von Prioritäten, Warnmeldungen und Kapazitätsberichte usw. Dies ist es letztendlich, was die Prozesse und Anforderungen von Binance im Vergleich zu einer typischen Kapazitätsmanagementsituation einzigartig macht.
Der durch Belastungstests ermittelte Service-Benchmark ist der Schwerpunkt des Kapazitätsmanagements und der Kapazitätsplanung. Er bestimmt genau die Infrastrukturressourcen, die zur Unterstützung aktueller und zukünftiger Geschäftsanforderungen erforderlich sind. Dies musste letztendlich in der Produktion mit einer einzigartigen, von Binance entwickelten Lösung durchgeführt werden, die es uns ermöglichte, unsere spezifischen Anforderungen zu erfüllen.
Zusammenfassend hoffen wir, dass Sie erkennen können, dass eine gute Planung und ein durchdachter Rahmen dabei helfen, den Service zu schaffen, den die Binancianer kennen und schätzen.
Verweise
Dominic Ogbonna, A-Z des Kapazitätsmanagements: Praktischer Leitfaden zur Implementierung von IT-Überwachung und Kapazitätsplanung in Unternehmen, Kapitel 4, Kapitel 6
Luis Quesada Torres, Doug Colish, SRE Best Practices für Kapazitätsmanagement
Alejandro Forero Cuervo, Sarah Chavis, Google SRE-Buch, Kapitel 21 – Umgang mit Überlastung
Weitere Informationen
(Blog) Wie Binance Ledger Ihr Binance-Erlebnis verbessert
(Blog) Einführung in Binance Oracle VRF: Die nächste Generation nachweisbarer Zufälligkeit
(Blog) Binance tritt der FIDO Alliance bei, um die Passkey-Implementierung vorzubereiten