
Autor:PermaDAO
Bei der dezentralen Speicherung handelt es sich um eine Methode zur Datenspeicherung, die nicht auf einen einzigen zentralen Kontrollpunkt angewiesen ist. Dieser Ansatz steht im Gegensatz zu herkömmlicher zentralisierter Speicherung (z. B. herkömmlichen Cloud-Speicherdiensten wie Amazon S3 oder Google Cloud), die häufig von einem einzelnen Unternehmen oder einer einzelnen Organisation verwaltet werden.
Mainstream-dezentraler Speicher
Zu den gängigen dezentralen Speichern auf dem Markt gehören derzeit Arweave, Filecoin und Storj. Jeder von ihnen hat einzigartige Eigenschaften und Designkonzepte:
Arweave konzentriert sich auf die langfristige oder dauerhafte Datenspeicherung.
Filecoin bietet einen dezentralen Markt, der dem herkömmlichen Cloud-Speicher ähnelt und flexible Speicheranforderungen unterstützt.
Storj konzentriert sich auf dezentrale Cloud-Speicherdienste, die Sicherheit und Datenschutz bieten.
Diese drei Plattformen nutzen alle die Blockchain-Technologie, ihre Anwendungsszenarien, technischen Implementierungen und Zahlungsmodelle sind jedoch unterschiedlich und jede ist für unterschiedliche Arten von Speicheranforderungen geeignet:
Arweave
Ziel: Bereitstellung einer langfristigen, dauerhaften Datenspeicherlösung. Das Ziel von Arweave besteht darin, Daten „für immer“ zu speichern und dient vor allem der langfristigen Datenerhaltung.
Technologie: Verwendet eine einzigartige Blockchain-Technologie namens Blockweave. Im Gegensatz zu herkömmlichen Blockchains enthält Block Fabric in jedem neuen Block Verweise auf frühere Zufallsblöcke, um die langfristige Speicherung von Daten zu fördern.
Bezahlmodell: Nutzer zahlen eine einmalige Gebühr für die Datenspeicherung, nach der Speicherung sind die Daten theoretisch dauerhaft abrufbar.
Filecoin
Ziel: Ziel ist die Schaffung eines dezentralen Speichermarktes, ähnlich den herkömmlichen Cloud-Speicherdiensten.
Technologie: Filecoin ist die Anreizschicht für IPFS (Internet File System). Es verwendet „Speichernachweis“ und „Raum- und Zeitnachweis“, um sicherzustellen, dass die Daten korrekt gespeichert werden.
Zahlungsmodell: Benutzer bezahlen den Speicheranbieter basierend auf der Menge der gespeicherten Daten und der Dauer. Dabei handelt es sich um ein eher traditionelles Mietmodell, bei dem Benutzer den Speicherplatz je nach Bedarf vergrößern oder verkleinern und entsprechend bezahlen können.
Geschichte
Ziel: Benutzern eine dezentrale Cloud-Speicherlösung mit Schwerpunkt auf Sicherheit und Datenschutz bieten.
Technologie: Storj verwendet Verschlüsselungs- und Sharding-Technologie, um die Datensicherheit und Privatsphäre zu schützen. Die Daten werden verschlüsselt und vor dem Hochladen auf dem Client in mehrere kleine Blöcke aufgeteilt und dann auf Knoten auf der ganzen Welt verteilt und gespeichert.
Zahlungsmodell: Das Zahlungsmodell von Storj ähnelt dem herkömmlichen Cloud-Speicher, wobei die Abrechnung auf Speicherplatz und genutzter Bandbreite basiert.
Im Gegensatz dazu ist Arweave insofern einzigartig, als es den Schwerpunkt auf die dauerhafte Speicherung legt und mehr Wert auf die Widerstandsfähigkeit und Haltbarkeit der Datenzensur legt. Filecoin und Storj nutzen beide den Speichermarkt und konzentrieren sich auf den Einsatz der Blockchain-Technologie zur Rekonstruktion des Speichermarkts.
Analyse der Geschäftsarchitektur
Die theoretische Grundlage von Arweave für die dauerhafte Datenspeicherung ähnelt dem „Moores Gesetz“. Laut Statistiken zu Datenspeicherkosten von 1980 bis heute sinken die Speicherkosten jedes Jahr um 20 %. Nach diesem statistischen Gesetz werden sich die Kosten für die Datenspeicherung nach unendlichen Jahren einer Konstanten annähern. Darauf basiert Arweave Perpetual Storage und berechnet die Kosten der Datenspeicherung für 200 Jahre. Diese einmalige Gebühr zahlen Nutzer bei der Datenspeicherung.
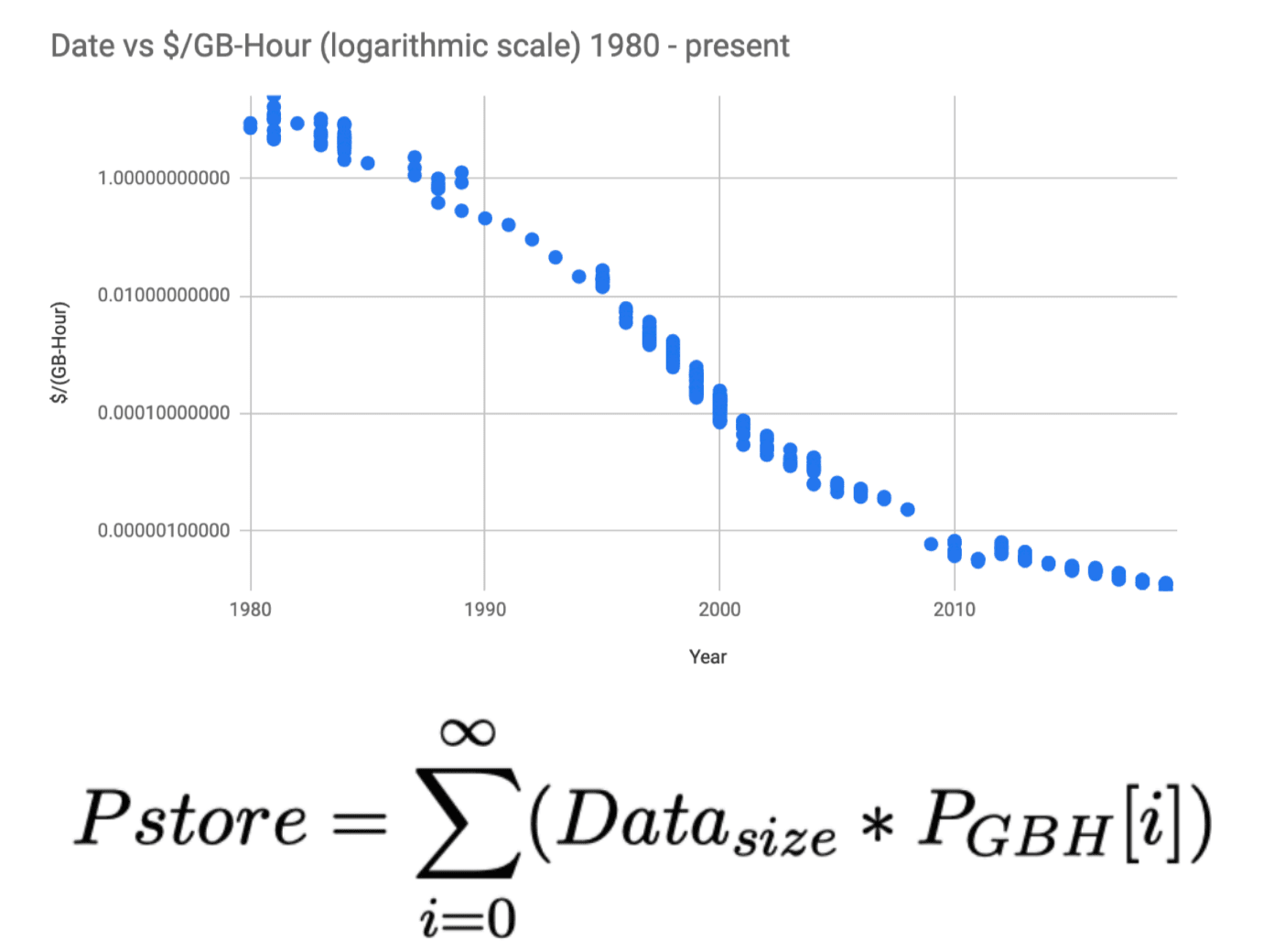
Gleichzeitig hat Arweave einen sehr eleganten und übersichtlichen Data-Mining-Mechanismus entwickelt. Wir können es „effektives Data Mining“ nennen.
Die sogenannten „gültigen Daten“ beziehen sich auf Daten, die in der Vergangenheit im Arweave-Netzwerk gespeichert wurden, und Benutzer haben für diese gültigen Daten 200 Jahre lang Speichergebühren gezahlt. Eine weitere Rollengruppe im Netzwerk sind Miner. Sie nutzen gültige Daten zum Mining und bieten gültige Datenlesedienste an. Der Unterschied zu anderen Speicher-Blockchains besteht darin, dass Arweave Miner nicht dazu zwingt, Daten zu speichern, sondern Anreizregeln festlegt, um jeden Miner zu ermutigen, die Speicherung „gültiger Daten“ zu maximieren. Im Arweave-Netzwerk gilt: Je mehr „gültige Daten“ ein Miner speichert, desto größer ist die „Rechenleistung“ des Minings.
Unter der Annahme, dass im Arweave-Netzwerk 100 TB gültige Daten vorhanden sind, ist es für Miner nicht zwingend erforderlich, alle 100 TB Daten zu speichern. Mit anderen Worten: Der Miner kann schürfen, indem er nur 100 MB Daten speichert, aber die Rechenleistung des Miners ist sehr gering. Wenn sich ein Miner dafür entscheidet, alle 100 TB an Daten zu speichern, ist die ihm zur Verfügung stehende Rechenleistung maximal.
Beim „effektiven Data Mining“-Mechanismus bietet das Arweave-Netzwerk Minern einen Anreiz, so viele Daten wie möglich zu speichern, zwingt sie jedoch nicht, alle Daten zu speichern. Besteht bei diesem Anreizmodell also die Möglichkeit eines Datenverlusts? Im Folgenden finden Sie eine Simulationsrechnung zum Datenverlust:

Die 0,5 in der ersten und zweiten Zeile bezieht sich auf einen einzelnen Knoten, der 50 % der Daten speichert. Angenommen, das Blocknetzwerk hat 200.000 Blöcke und 200 Knoten im Netzwerk. Jeder Knoten speichert zufällig 100.000 Blöcke (50 % der Blockdaten). Die Zugriffswahrscheinlichkeit beträgt 6,223 ^ 10 -61. Die vom Cloud-Dienst bereitgestellte Datenzuverlässigkeit beträgt 99,9999999 %, was 10 hoch 7 entspricht. Der obige Arweave-Kalkül erreicht eine erstaunliche 61. Potenz.
Filecoin und Storj nutzen beide Blockchain-Technologie, um einen Datenspeichermarkt aufzubauen. Die wichtigste Verbesserung von Storj ist der Datenschutz. In diesem Artikel werden hauptsächlich die Prinzipien von Filecoin erläutert.
Ähnlich wie bei einem herkömmlichen Auftragsbuch müssen Benutzer, die Filecoin verwenden, zunächst auf den Handelsmarkt gehen, um Gebote abzugeben und Aufträge zu erteilen, und die Datenspeicherzeit und die Sicherungsmenge angeben. Die Miner erhalten profitable Aufträge. Um die Fairness des gesamten Handelsmarktes zu gewährleisten, hat Filecoin ein komplexes Wirtschaftsmodell etabliert und verschiedene Regeln wie Verfall und kleine Ratenzahlungen aufgestellt. Seine Kerntechnologien sind Replikationsbeweis und Raum-Zeit-Beweis.
Replikationsnachweis: Miner beweisen den Benutzern, dass die Daten auf einem dedizierten physischen Gerät gespeichert wurden. Jedes Mal, wenn ein Miner einen Nachweis erbringt, um die Daten eines Benutzers zu speichern, zahlt das Netzwerk dem Miner eine Gebühr.
Zeit- und Raumnachweis: Wenn Sie nur über einen Kopienachweis verfügen, ist nicht garantiert, dass Ihre Daten immer gespeichert werden. Miner können bei der Übermittlung des Nachweises nur diesen Teil der Daten speichern. Zu diesem Zweck hat Filecoin den Raum-Zeit-Beweis hinzugefügt, um es den Minern zu ermöglichen, diese Daten kontinuierlich zu speichern.
Um das oben Gesagte zusammenzufassen: Die Grundlage und der Umsetzungsplan für die Langlebigkeit von Arweave sind:
Die dauerhaften Kosten sinken von Jahr zu Jahr
Anreize für Miner durch „effektives Data Mining“, um Datenpermanenz zu erreichen
Filecoin und Storj sind dezentrale Speichermärkte, die mithilfe der Blocktechnologie erstellt wurden. Ihre Modelle ähneln den Auftragsbüchern traditioneller Handelsmärkte. Das Auftragsbuch stellt die Nachfrage bereit und die Miner nehmen den Auftrag an, um die Datenspeicherung sicherzustellen. Die technischen Kernpunkte von Filecoin sind: Nachweis der Replikation sowie Nachweis von Zeit und Raum.
Lagerungspraxis
Es gibt zwei Möglichkeiten, Daten in Arweave zu speichern. Die erste Methode sendet Daten direkt an den Arweave-Knoten und zahlt AR. Die zweite Möglichkeit besteht darin, das Datenbindungsprotokoll ANS-104 (Bundled) zu verwenden, um Daten stapelweise in Arweave zu verpacken.
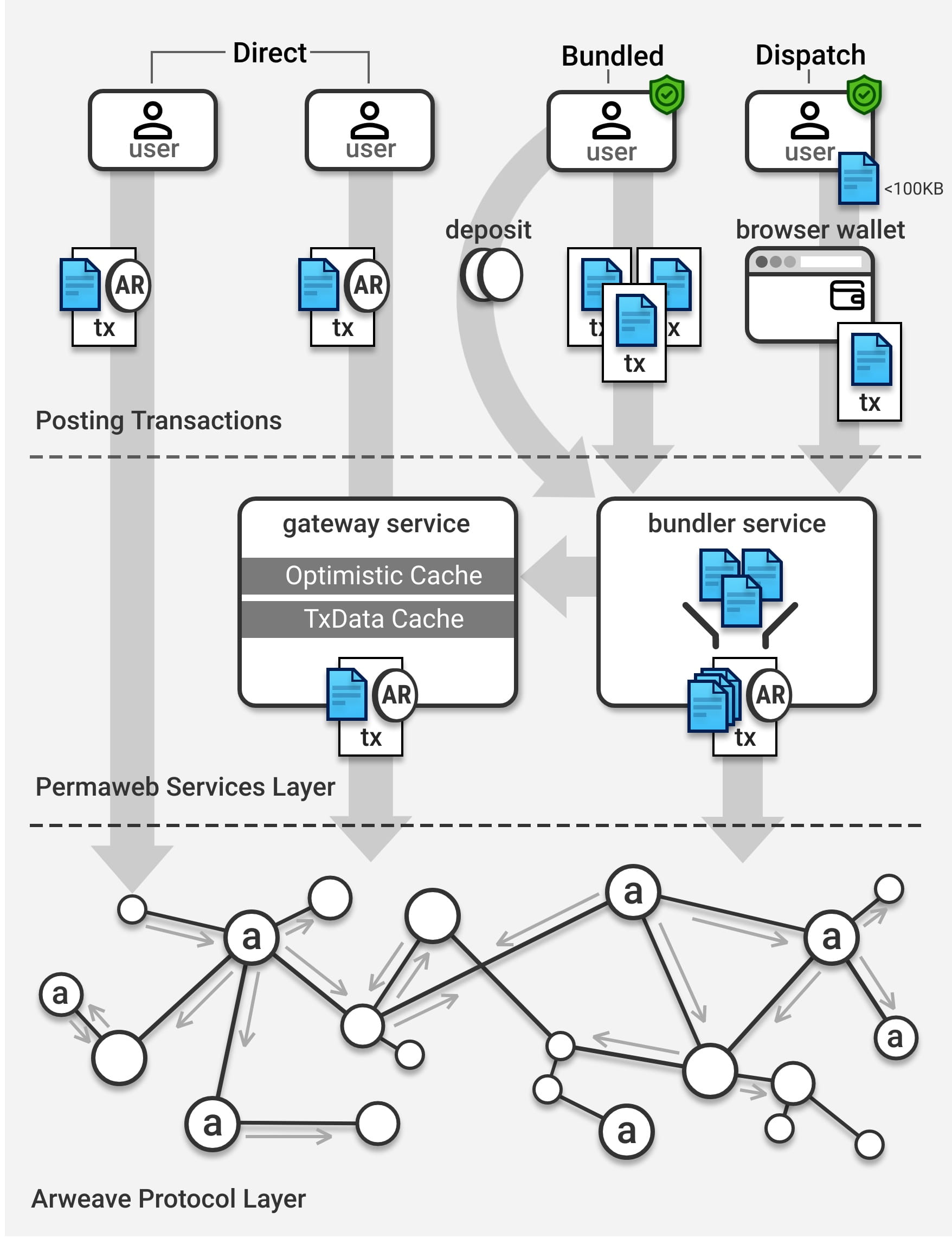
Speichern Sie Daten direkt in Arweave
Der Benutzer muss lediglich einen AR vorbereiten, den er in der Brieftasche aufbewahren kann, um diese Aktion abzuschließen. Verwenden Sie den folgenden Code, um eine Datei mit dem Namen file.pdf in Arweave zu speichern:

Weitere Dokumentationsreferenzen: https://github.com/ArweaveTeam/arweave-js.
Verwenden Sie ANS-104, um Daten in Arweave zu speichern (empfohlen)
Die Blockproduktionsrate von Arweave ist niedrig, normalerweise etwa 2 Minuten, und ein Block kann nur 1.000 Transaktionen verarbeiten, was die Anzahl der Transaktionen, die Arweave speichern kann, stark einschränkt. Obwohl die Speicherkapazität einer Arweave-Transaktion unbegrenzt ist, können Benutzer 100 MB oder sogar speichern 10 GB Daten direkt an Arweave in einer Transaktion. Um das Problem der Erhöhung der Anzahl der Transaktionen zu lösen, wurde ANS-104 ins Leben gerufen.
ANS-104 ist eine Multi-Transaktions-Bindungstechnologie, die Zehntausende verschiedener Datenentitäten gleichzeitig in einer gemeinsamen Arweave-Transaktion binden kann. Es kann mit der Ethereum-zu-Layer2-Rollup-Lösung verglichen werden. Der Unterschied besteht darin, dass ANS-104 die Sicherheit der Daten nicht verliert und die gebundenen Daten auch zu 100 % vollständig auf Arweave gespeichert sind.
Das Codebeispiel für die Verwendung von ANS-104 zum Speichern von Daten lautet wie folgt:

Dieser Code verwendet den Arweave-Light-Knoten als Datenbindungsdienst. Der Arweave-Light-Knoten ist ein vollständig Open-Source-Arweave-Datenknoten, der alle nativen Arweave-Knotenschnittstellen unterstützt und die ANS-104-Schnittstelle erweitert. Gleichzeitig integriert Arseeding das kettenübergreifende Zahlungsprotokoll everPay, sodass Benutzer und Entwickler neben der Verwendung von AR zur Zahlung von Speichergebühren auch verschiedene Assets wie ETH, BNB, USDT und USDC für die Datenpersistenz verwenden können.
Weitere Dokumentationsreferenz: https://web3infra.dev/docs/Arseeding/guide/quickStart.
Lagergebühren
Derzeit kostet die Speicherung von 1 GB Daten auf Arweave 7,5 US-Dollar. Die neueste Speichergebührenreferenz: https://ar-fees.arweave.dev/.
Arweave-Daten abrufen und herunterladen
Arweave verfügt über eine standardisierte GraphQL-Serviceschnittstelle und jede Einzelperson oder Organisation kann Arweave-Indizes gemäß dem Standard implementieren. Im Folgenden sind zwei typische und nützliche Index-Gateways aufgeführt:
ArweaveNet-Gateway, der umfassendste Index. https://arweave.net/graphql
KNN3-Gateway, schnelles Abrufen von Arseeding-Knotendaten in Echtzeit. https://knn3-gateway.knn3.xyz/arseeding/graphql
Um Arweave-Daten herunterzuladen, müssen Sie nur die ARID oder ItemID der Daten kennen. Codebeispiel:

Filecoin-Speichermethode
Leider stellt Filecoin keine Speichertools für normale Benutzer und Entwickler bereit. Für normale Entwickler ist Filecoin nicht verfügbar. In vereinzelten technischen Dokumenten können Sie einige Lösungen für die Filecoin-Speicherung durch Drittanbieter finden. Wenn Sie sich jedoch die Dokumente des Dienstanbieters genau ansehen, stellen die meisten Dienstanbieter nur IPFS-Speicher bereit und diese Dienstanbieter speichern nicht unbedingt Daten Filecoin. Vielleicht kann ich aufgrund der begrenzten Kenntnisse des Autors wirklich keine bessere Möglichkeit finden, Daten in Filecoin zu speichern, und es gibt keine entsprechende Schnittstelle, um Daten direkt von Filecoin abzurufen.
Storj-Speichermethode
Die Speichermethode von Storj ist die gleiche wie die von Web2. Entwickler müssen sich auf der offiziellen Website registrieren und den API-KEY erhalten. Der Speicher von Storj ist mit der AWS S3-Schnittstelle kompatibel, daher werde ich hier nicht auf Details eingehen. Die Speichergebühren von Storj sind niedrig: 1 GB Speicher kostet nur 0,004 US-Dollar für einen Monat. Die auf 200 Jahre umgerechneten Speicherkosten werden jedoch mit 9,6 US-Dollar etwas höher sein als bei Arweave.
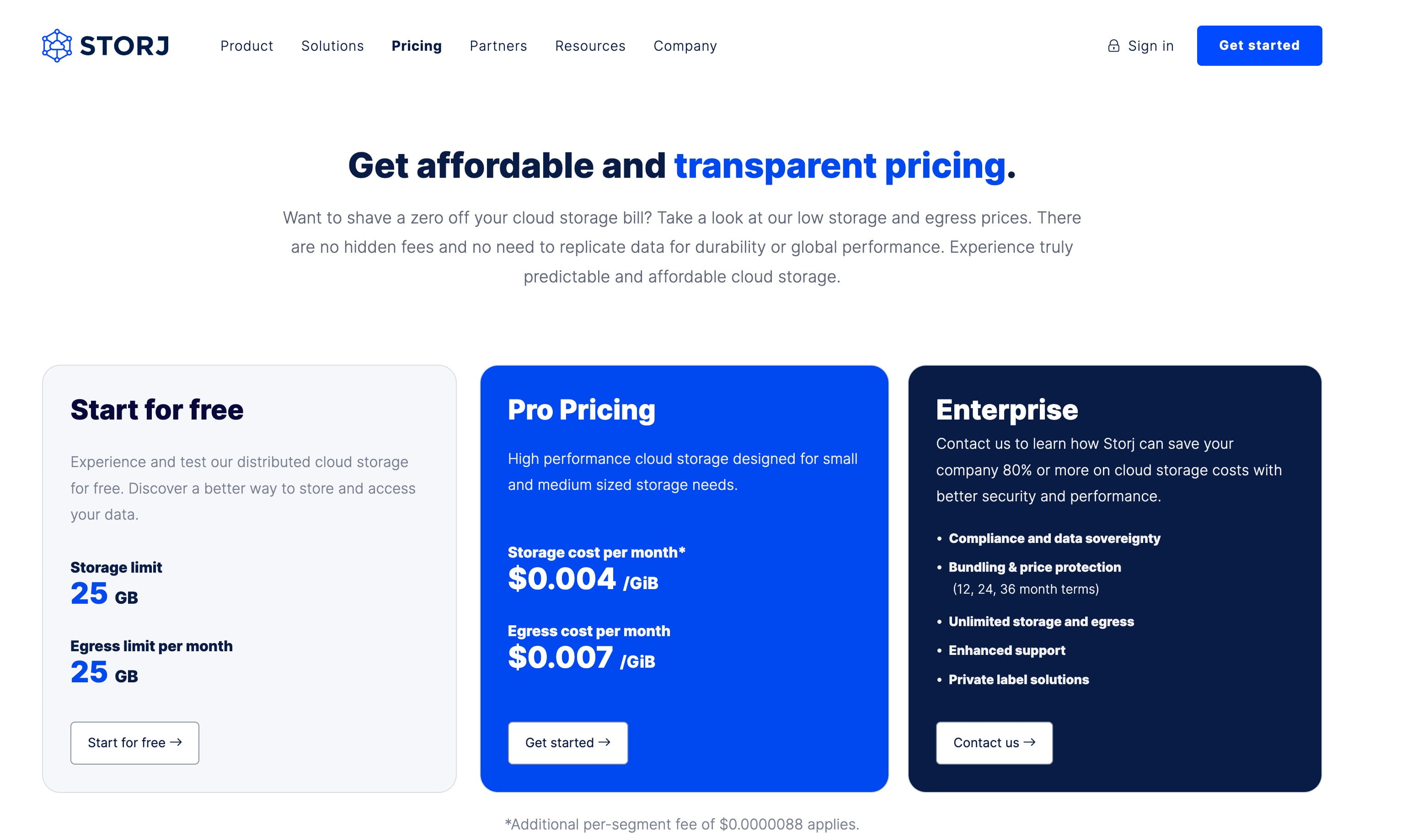
Aus dem tatsächlichen Speichervorgang ist ersichtlich, dass das Transaktionsverarbeitungsmodell von Arweave mit Blockchains wie Bitcoin/Ethereum übereinstimmt. Filecoin stellt kein nutzbares SDK und keine Schnittstellen zur Verfügung. Leider ist der sogenannte Speicherführer für Entwickler nicht verfügbar, was enttäuschend ist. Die Speichermethode von Storj ist genau die gleiche wie die von Web2.
Es ist erwähnenswert, dass Arweave ein nativer Blockchain-Speicher ist und die Daten, sobald sie an Arweave gesendet wurden, weder gelöscht noch manipuliert werden können. Filecoin und Storj sind Leasingmodelle. Die Projektpartei kann den Speicherleasingdienst jederzeit beenden. In diesem Modus weisen die Daten keine Blockchain-Eigenschaften auf und die Dateneigenschaften stimmen mit denen überein, die in zentralisierten Cloud-Diensten gespeichert sind.
Um den Unterschied zwischen Datenspeichern wie Arweave und Filecoin deutlicher zu machen, können wir die Daten auf Arweave als „Konsensdaten“ bezeichnen. Unabhängig davon, ob es sich um Daten zu BTC oder Ethereum handelt, sind diese Daten nicht manipulierbar und können Rückverfolgbarkeitsfunktionen sein. Die auf dem Filecoin-Speichermietmarkt gespeicherten Daten können nicht als Konsensdaten bezeichnet werden.
Entwicklungsperspektiven
Bei der dezentralen Speicherung haben sich zwei völlig unterschiedliche Geschäftszweige herausgebildet. Unter ihnen nimmt der von Arweave vertretene Geschäftsbereich Konsensdaten als Kern und legt Wert auf Datendezentralisierung, Zensurresistenz, Rückverfolgbarkeit und andere Merkmale. Der von Filecoin vertretene Geschäftsbereich konzentriert sich auf den dezentralen Markt und legt Wert auf die Zuweisung von Speicherressourcen und den Nachweis des Speichererfolgs. Analog zur Entwicklung von DeFi nutzte die frühe IDEX die Blockchain-Technologie, um einen Orderbuchmarkt zu schaffen. Das Orderbuch ist ein sehr traditionelles Geschäftsmodell, das darauf abzielt, das Problem des Ticketaustauschs mithilfe des Hang-up-and-Take-Order-Modells zu lösen. Die Explosion von DeFi ist die Liquiditäts-Mining-Technologie, die das AMM-Handelsmodell von Uniswap mit sich bringt und die eine vollständige Automatisierung und Ausführung von Aufträgen ermöglicht, die Kombination von Liquidität realisiert und schließlich die Explosion von DeFi Summer einleitet. Im aktuellen dezentralen Speicherbereich stellt Filecoin auch die Blockchain-Technologie dar, die den Orderbuchmarkt schafft, während Arweave ein einheitliches Modell ähnlich AMM verwendet, um Datenangebot und -nachfrage zu verwalten. Das einheitliche Modell von Arweave ist praktischer für die Datenpreisgestaltung und -verarbeitung. Mit Arweave kann die Umwandlung gewöhnlicher Daten in Konsensdaten bequemer durchgeführt werden. Daten, die auf diesem Konsens basieren, können eine Explosion der „Datenzusammensetzung“ einleiten.
Gleichzeitig muss ich die SCP-Theorie (speicherbasiertes Konsensparadigma) erwähnen. Ihre Kernidee besteht darin, dass die aus diesen Daten zusammengesetzten Anwendungen auch einen Konsens bilden können, solange die Datenspeicherung einen Konsens aufweist. SCP legt Wert auf Off-Chain-Computing. Daten können auf verschiedenen Ketten wie BTC und Ethereum gespeichert werden, und durch die Aggregation von Daten auf der Blockchain wird ein eindeutiger Zustand gebildet. Da diese Zustände bei der Ausführung auf jeder Recheneinheit die gleichen Ergebnisse liefern, warum müssen wir sie dann trotzdem in der Kette bearbeiten? So viele Rechenressourcen verschwenden?
Der derzeit beliebte BRC20 und Bitcoin Inscription nutzen beide den Konsens des Off-Chain-Computing. Der vom BRC20-Protokoll und Arweave SCP betonte Speicherkonsens ist konsistent. Beide nutzen die Blockchain als Datenschicht, um unveränderliche und nachvollziehbare Transaktionsdaten bereitzustellen, und die Berechnung des Zustands erfolgt vollständig außerhalb der Kette. Mit den Speicherfunktionen von Arweave kann SCP Theory einen robusteren Konsensdatensatz erhalten. Die Arweave SCP-Theorie hat einen kompletten Satz technischer Anwendungslösungen entwickelt – Permaweb, das der ultimativen Version des Bitcoin-Indexers entspricht und nicht nur Assets, sondern auch Texte, Bilder und sogar Videos verarbeiten kann. Stellen Sie sich eine nahe Zukunft vor, in der supermächtige Indexer Medien streamen können und so ein vollständig dezentralisiertes Douyin schaffen.

Derzeit unterstützt die Permaweb-Lösung eine Vielzahl von Anwendungstypen, egal ob es sich um Netzwerkfestplatten, die gemeinsame Erstellung von Inhalten oder Spiele handelt, sie kann mit dieser Architektur problemlos entwickelt werden. Daten zwischen Permaweb-Anwendungen können miteinander kombiniert werden. Beispielsweise lädt ein Autor den Text und das Urheberrecht seiner Kreation durch die gemeinsame Erstellung von Inhalten auf Arweave hoch. In einem anderen Spiel kann der Entwickler den Inhalt des Autors direkt zitieren und den Spielern erlauben, den Autor für das Urheberrecht zu bezahlen.
Die größte Schwierigkeit, auf die DePIN stößt, ist derzeit die Leistung der Blockchain. DePIN-Geräte werden in Tausende von Haushalten gelangen, aber keine Blockchain kann so große Benutzerinteraktionen übertragen. Die meisten DePINs verwenden immer noch einen zentralisierten Ansatz zur Datenverarbeitung, wodurch DePINs ihren dezentralen Charakter verlieren. Konsensdaten können DePIN stärker stärken. Sobald DePIN-Daten dauerhaft sind, erhalten diese Daten auch kombinatorische Eigenschaften. Beispielsweise kann ein Zertifikat für grüne Energie den Energieverbrauch bei Blockchain-PoW-Berechnungen ausgleichen, als Logo bei der Erstellung von Inhalten dienen und auch als Abzeichen in Spielen dienen. Daten und Werte werden überall fließen.
Konsensdaten gelten auch für den Bereich KI. Menschliches Wissen und Geschichte sollten ewig bestehen bleiben, und Konsensdaten können sicherstellen, dass KI menschliches Wissen und Geschichte nicht verunreinigen oder manipulieren kann. Ebenso können Konsensdaten als bestes Datenrohmaterial für KI verwendet werden, sodass die KI eine Vielzahl effektiver Informationen lernen und verarbeiten kann.