
Das erste Mal, dass Walrus für mich wirklich klickte, war nicht wegen eines Benchmarks oder einer kühnen Behauptung. Es war, weil es sich seltsam praktisch anfühlte. In Web3 wird Speicher normalerweise wie ein Lagerhaus behandelt. Man legt Dateien irgendwo ab, kopiert sie ein paar Dutzend Male und hofft, dass sie noch da sind, wenn jemand sie braucht. Walrus stellt diese Annahme in Frage. Es behandelt Daten nicht als etwas, das man ablegt und vergisst. Es behandelt Daten als etwas Lebendiges. Etwas, das verfügbar, verifizierbar und schnell bleiben muss, selbst wenn Teile des Systems ausfallen oder sich ändern. Dieser Wandel klingt subtil, hat aber echte Konsequenzen dafür, wie Anwendungen gebaut werden.
Im Herzen von Walrus liegt eine andere Denkweise über Resilienz. Die meisten dezentralen Speichersysteme verlassen sich stark auf Replikation. Die Idee ist einfach: Kopiere dieselbe Datei viele Male, damit, wenn einige Kopien verschwinden, andere übrig bleiben. Das Problem sind Kosten und Ineffizienz. Walrus verwendet ein Design namens Red Stuff, das auf Fehlerkorrektur anstelle von brutaler Kopie basiert. Einfach ausgedrückt, wird eine Datei in viele Teile zerlegt und mit Redundanz in zwei Dimensionen codiert. Wenn einige Teile fehlen, kann das System sie mit den verbleibenden rekonstruieren. Es ist ähnlich, wie moderne Fehlerkorrektur bei der Datenübertragung funktioniert. Man sendet nicht alles erneut, sondern nur das, was benötigt wird. Das Ergebnis ist ein Speicher, der sich selbst unter Last heilen kann, ohne übermäßige Bandbreite oder Speicherverschwendung. Es geht nicht darum, clever aus Eigeninteresse zu sein. Es geht darum, große Daten in großem Maßstab nutzbar zu machen, ohne die Kosten aus dem Ruder laufen zu lassen.
Was Walrus wirklich von vielen Speicherprojekten trennt, ist, wie eng es Daten mit Anwendungen verbindet. Speicher ist nicht hinter den Kulissen verborgen. Durch die Integration mit dem Objektmodell von Sui können Speicherkapazität und Datenblobs als Ressourcen dargestellt werden, auf die Anwendungen verweisen können. Das ist wichtig, denn es ermöglicht Apps, über die Verfügbarkeit von Daten nachzudenken, anstatt sie blind zu vertrauen. In einigen Designs können Smart Contracts sogar überprüfen, ob Daten noch über On-Chain-Koordination zugänglich sind. Das verwandelt Speicher in einen Teil der Anwendungslogik, anstatt eine stille Abhängigkeit zu sein. Für Entwickler ändert sich dadurch die Denkweise. Daten sind nicht mehr einfach „irgendwo außerhalb der Kette“. Sie werden zu etwas, das die App überprüfen, verfolgen und darauf reagieren kann, wenn sich die Bedingungen ändern.
Geschwindigkeit ist ein weiteres Gebiet, in dem Walrus eine bodenständige Wahl trifft. Viele Web3-Systeme tun so, als ob traditionelle Infrastruktur nicht existiert, oder schlimmer, dass sie vollständig ersetzt werden sollte. Walrus spielt dieses Spiel nicht. Es akzeptiert eine einfache Wahrheit: Benutzer erwarten schnelle Ladezeiten. Frontends können nicht auf langsame Peer-to-Peer-Abfragen warten, wenn eine Seite geladen wird. Walrus ist so konzipiert, dass der Datenzugriff durch Aggregatoren fließen und über Caches oder CDNs bereitgestellt werden kann. Dies untergräbt nicht die Dezentralisierung. Es ergänzt sie. Die dezentrale Schicht gewährleistet Datenintegrität und Wiederherstellbarkeit, während vertraute Bereitstellungstools die Leistung übernehmen. Benutzer erhalten Geschwindigkeit. Entwickler vermeiden schmerzhafte Kompromisse. Das System funktioniert mit dem Internet, wie es existiert, nicht als idealisierte Version davon.
Diese praktische Haltung spiegelt sich auch darin wider, wie Walrus sein Ökosystem aufgebaut hat. Jüngste Integrationen und Partnerschaften deuten auf eine Nutzung in der realen Welt hin, anstatt auf enge Experimente. Der Fokus lag auf der Verbesserung der Bandbreite, der Reduzierung der Latenz und der Unterstützung von Echtzeitanwendungsfällen für Daten. Dies sind keine auffälligen Ankündigungen, aber sie sind bedeutend. Sie deuten darauf hin, dass Walrus sich als ernstzunehmende Datenschicht positioniert, auf der andere aufbauen können. Kein Nebenergebnis. Kein Werkzeug für einen einzigen Zweck. Infrastruktur, die in den Hintergrund tritt, während sie ambitioniertere Anwendungen ermöglicht.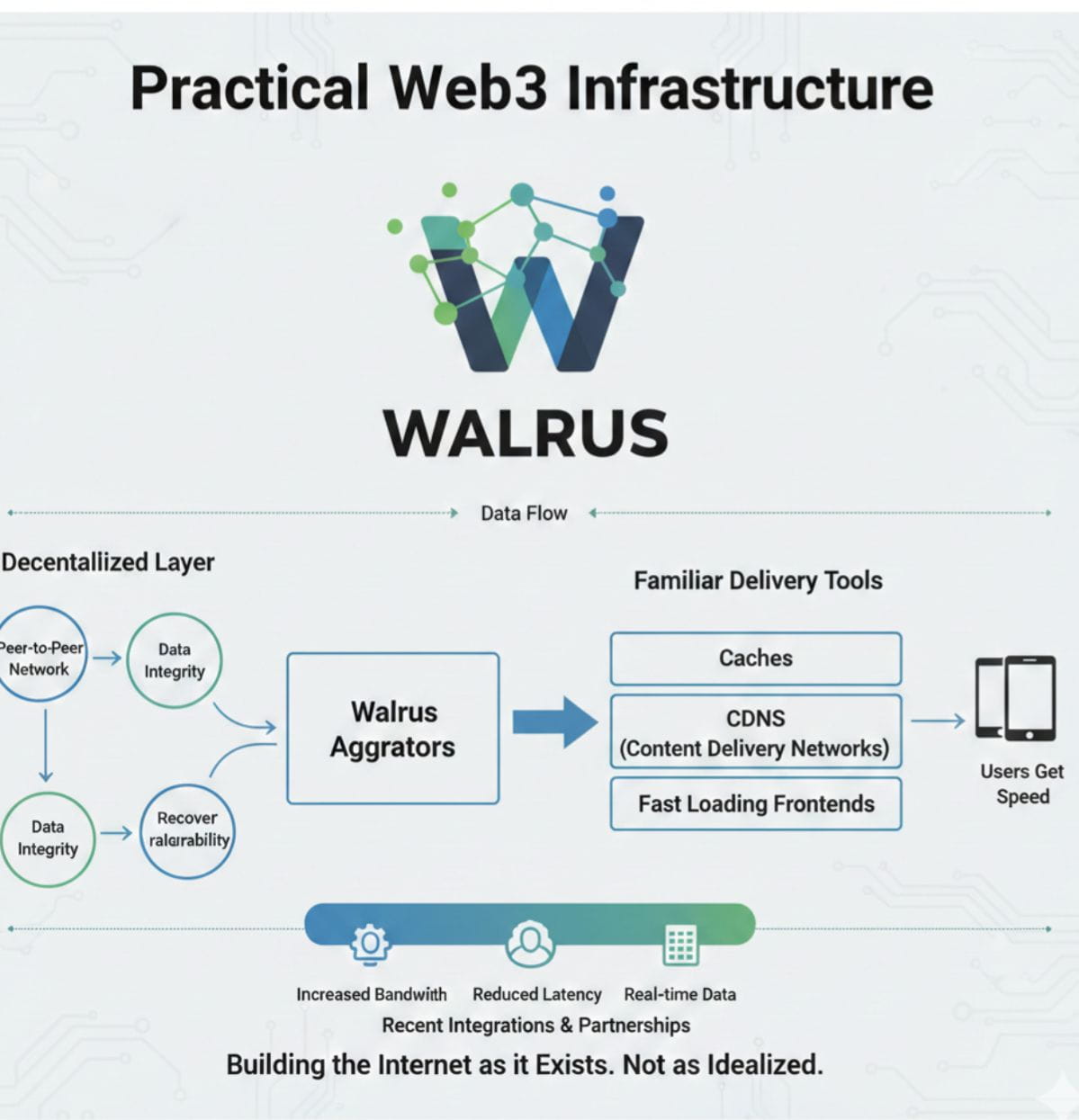
Die beste Art, Walrus heute zu beschreiben, ist nicht als Speicher, sondern als Koordination rund um Daten. Es erlaubt, große Objekte als Blobs zu speichern, hält sie wiederherstellbar, selbst wenn Knoten kommen und gehen, macht sie verifizierbar genug, um von Anwendungen referenziert zu werden, und bedient sie schnell genug, dass Benutzer sich nicht bestraft fühlen, weil sie dezentrale Systeme wählen. Jedes dieser Teile existiert anderswo isoliert. Walrus kombiniert sie zu einer kohärenten Schicht. Diese Kombination macht es interessant. Es versucht nicht, die Erzählung zu dominieren. Es löst ein leises Problem, mit dem jede ernsthafte Anwendung letztlich konfrontiert ist.
Es gibt natürlich Grenzen und offene Fragen. Langfristige Resilienz hängt von gesunden Anreizen für Betreiber ab. Tiefe Angriffe oder extreme Netzwerkfehler testen weiterhin jedes verteilte System. Und auf einem spezifischen Ökosystem wie Sui aufzubauen bedeutet, sowohl dessen Stärken als auch dessen Risiken zu übernehmen. Walrus beseitigt diese Realitäten nicht. Was es tut, ist, sie anzuerkennen und durchdacht um sie herum zu gestalten. Das allein hebt es in einem Raum hervor, der oft zu viel verspricht und zu wenig erklärt.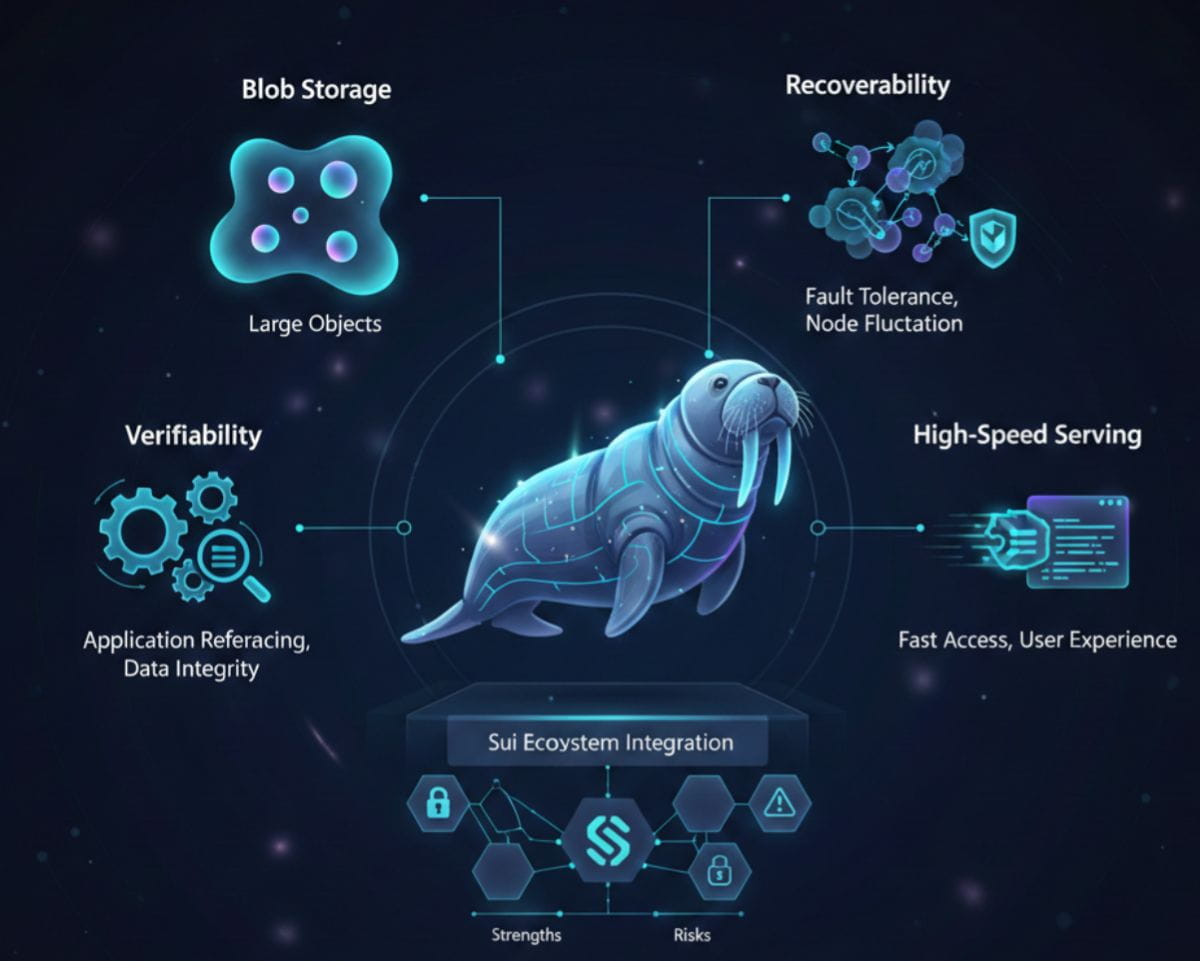
Am Ende hat Walrus mich dazu gebracht, darüber nachzudenken, was Speicher in Web3 bedeuten sollte. Nicht ein Ort, an dem Dateien unberührt bleiben. Nicht ein Wettlauf, um zu sehen, wer die meisten Daten replizieren kann. Sondern eine lebendige Schicht, auf die Anwendungen angewiesen sein können, über die sie nachdenken und mit der sie skalieren können. Es ist die Art von Infrastruktur, die selten in sozialen Feeds im Trend liegt, aber still das formt, was möglich wird. Und in einem System, das echte Benutzer und echte Arbeitslasten unterstützen möchte, kann dieser stille Fortschritt mehr zählen als jede Schlagzeile.

