

Benchmarking von Schaltungsframeworks mit SHA-256

Wir möchten den Teams von Polygon Zero, dem Gnark-Projekt bei Consensys, Pado Labs und Delphinus Lab für ihre wertvollen Rezensionen und ihr Feedback zu diesem Blog danken.
Das Pantheon der Zero-Knowledge-Beweise
In den letzten Monaten haben wir viel Zeit und Mühe in die Entwicklung einer hochmodernen Infrastruktur investiert, die prägnante zk-SNARK-Beweise nutzt. Im Rahmen unserer Entwicklungsbemühungen haben wir eine Vielzahl von Zero-Knowledge-Proof (ZKP)-Entwicklungsframeworks getestet und verwendet. Obwohl dieser Weg lohnend war, ist uns bewusst, dass die Fülle der verfügbaren ZKP-Frameworks oft eine Herausforderung für neue Entwickler darstellt, die versuchen, die beste Lösung für ihre spezifischen Anwendungsfälle und Leistungsanforderungen zu finden. Angesichts dieses Problems glauben wir, dass eine Community-Evaluierungsplattform erforderlich ist, die umfassende Benchmark-Ergebnisse liefern kann und die Entwicklung dieser neuen Anwendungen erheblich erleichtern wird.
Um diesen Bedarf zu decken, starten wir das Pantheon of Zero Knowledge Proof als Gemeinschaftsinitiative zum Wohle der Allgemeinheit. Der erste Schritt wird darin bestehen, die Community zu ermutigen, reproduzierbare Benchmarking-Ergebnisse aus verschiedenen ZKP-Frameworks zu teilen. Unser oberstes Ziel ist es, gemeinsam und gemeinschaftlich ein allgemein anerkanntes Evaluierungstestbed zu erstellen und zu pflegen, das Low-Level-Frameworks für die Schaltungsentwicklung, High-Level-zkVMs und -Compiler und sogar Anbieter von Hardwarebeschleunigung abdeckt. Wir hoffen, dass diese Initiative die Einführung von ZKPs beschleunigt, indem sie fundierte Entscheidungen erleichtert, und gleichzeitig die Entwicklung und Iteration der ZKP-Frameworks selbst fördert, indem sie eine Reihe allgemein referenzierbarer Benchmarking-Ergebnisse bereitstellt. Wir sind entschlossen, in diese Initiative zu investieren, und laden alle gleichgesinnten Community-Mitglieder ein, sich uns anzuschließen und gemeinsam zu diesem Vorhaben beizutragen!
Ein erster Schritt: Benchmarking von Schaltungsframeworks mit SHA-256
In diesem Blogbeitrag machen wir den ersten Schritt zum Aufbau des Pantheons von ZKP, indem wir einen reproduzierbaren Satz von Benchmark-Ergebnissen mit SHA-256 für eine Reihe von Low-Level-Schaltkreisentwicklungs-Frameworks bereitstellen. Obwohl wir anerkennen, dass andere Benchmarking-Granularitäten und -Primitive möglich sind, haben wir uns aufgrund seiner Anwendbarkeit auf eine breite Palette von ZKP-Anwendungsfällen, darunter Blockchain-Systeme, digitale Signaturen, zkDID und mehr, für SHA-256 entschieden. Erwähnenswert ist auch, dass wir SHA-256 auch in unserem eigenen System nutzen, sodass es auch für uns recht praktisch ist! 😂
Unser Benchmark bewertet die Leistung von SHA-256 auf verschiedenen zk-SNARK- und zk-STARK-Schaltkreisentwicklungsframeworks. Durch diesen Vergleich möchten wir Entwicklern Einblicke in die Effizienz und Praktikabilität jedes Frameworks geben. Unser Ziel ist es, dass diese Erkenntnisse es Entwicklern ermöglichen, fundierte Entscheidungen bei der Auswahl des am besten geeigneten Frameworks für ihre Projekte zu treffen.
Prüfsysteme
In den letzten Jahren haben wir eine Zunahme von Zero-Knowledge-Proofing-Systemen beobachtet. Obwohl es eine Herausforderung ist, mit all den spannenden Fortschritten in diesem Bereich Schritt zu halten, haben wir die folgenden Proving-Systeme sorgfältig auf der Grundlage ihrer Reife und der Akzeptanz bei Entwicklern ausgewählt. Unser Ziel ist es, eine repräsentative Auswahl verschiedener Frontend-/Backend-Kombinationen zu präsentieren.
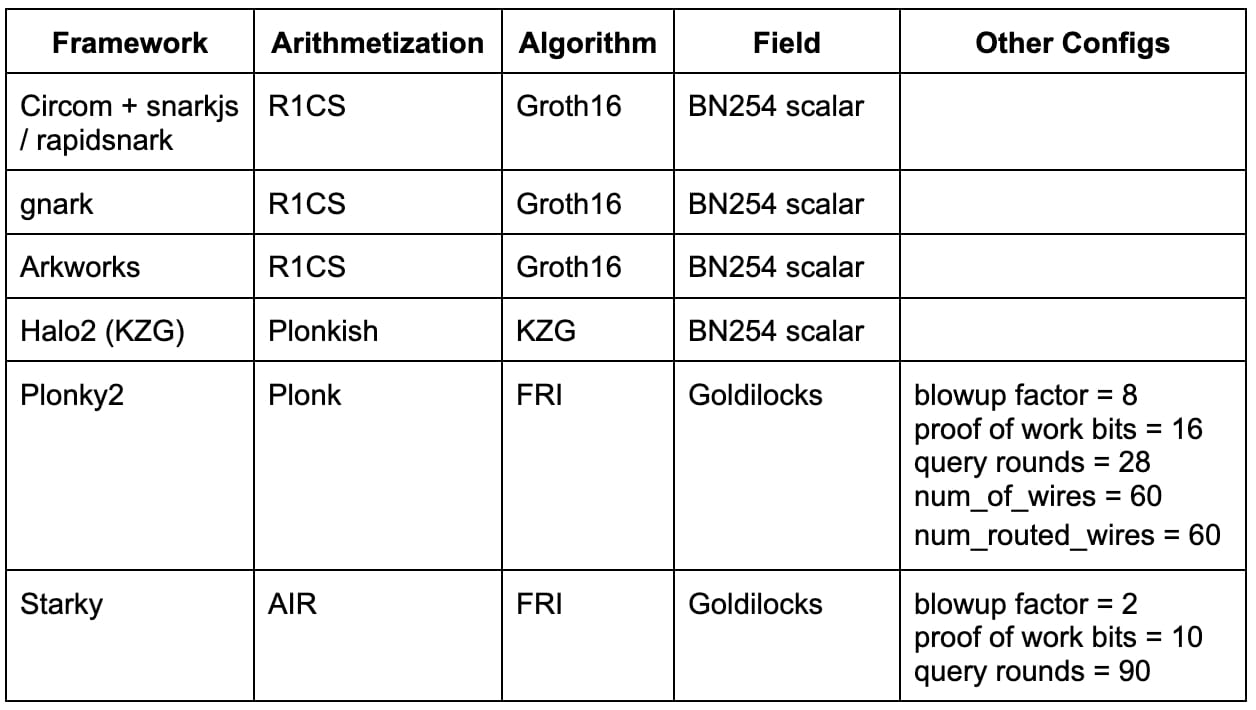
Circom + snarkjs / rapidsnark: Circom ist eine beliebte DSL zum Schreiben von Schaltkreisen und Generieren von R1CS-Einschränkungen, während snarkjs Groth16- oder Plonk-Beweise für Circom generieren kann. Rapidsnark ist auch ein Beweiser für Circom, der Groth16-Beweise generiert und aufgrund der Verwendung der ADX-Erweiterung, die die Beweisgenerierung so weit wie möglich parallelisiert, normalerweise viel schneller ist als snarkjs.
gnark: gnark ist ein umfassendes Golang-Framework von Consensys, das Groth16, Plonk und viele weitere erweiterte Funktionen unterstützt.
Arkworks: Arkworks ist ein umfassendes Rust-Framework für zk-SNARKs.
Halo2 (KZG): Halo2 ist Zcashs zk-SNARK-Implementierung mit Plonk. Es ist mit der hochflexiblen Plonkish-Arithmetisierung ausgestattet, die viele nützliche Primitive unterstützt, wie benutzerdefinierte Gates und Nachschlagetabellen. Wir verwenden einen Halo2-Fork mit KZG-Unterstützung von der Ethereum Foundation und Scroll.
Plonky2: Plonky2 ist eine SNARK-Implementierung, die auf Techniken von PLONK und FRI von Polygon Zero basiert. Plonky2 verwendet ein kleines Goldilocks-Feld und unterstützt effiziente Rekursion. Bei unserem Benchmarking haben wir auf 100-Bit-Sicherheit abgezielt und die Parameter verwendet, die die beste Testzeit für den Benchmark-Job ergaben. Insbesondere haben wir 28 Merkle-Abfragen, einen Blowup-Faktor von 8 und eine 16-Bit-Proof-of-Work-Grinding-Challenge verwendet. Darüber hinaus haben wir num_of_wires = 60 und num_routed_wires = 60 gesetzt.
Starky: Starky ist ein hochleistungsfähiges STARK-Framework von Polygon Zero. Bei unserem Benchmarking haben wir uns auf 100-Bit-Sicherheit konzentriert und die Parameter verwendet, die die beste Testzeit ergaben. Konkret haben wir 90 Merkle-Abfragen, einen Blowup-Faktor von 2 und eine 10-Bit-Proof-of-Work-Grinding-Challenge verwendet.
Die folgende Tabelle fasst die oben genannten Frameworks mit den relevanten Konfigurationen zusammen, die in unserem Benchmarking verwendet wurden. Diese Liste ist keineswegs vollständig und viele hochmoderne Frameworks/Techniken (z. B. Nova, GKR, Hyperplonk) bleiben zukünftigen Arbeiten vorbehalten.
Bitte beachten Sie, dass diese Benchmark-Ergebnisse nur für Frameworks zur Schaltungsentwicklung gelten. Wir planen, in Zukunft einen separaten Blog zu veröffentlichen, in dem verschiedene zkVMs (z. B. Scroll, Polygon zkEVM, Consensys zkEVM, zkSync, Risc Zero, zkWasm) und IR-Compiler-Frameworks (z. B. Noir, zkLLVM) verglichen werden.
Benchmark-Methodik
Um diese verschiedenen Prüfsysteme zu vergleichen, haben wir den SHA-256-Hash für N Bytes Daten berechnet, wobei wir mit N = 64, 128, ..., 64K experimentiert haben (mit einer Ausnahme: Starky, wo die Schaltung die SHA-256-Berechnung für einen festen 64-Byte-Eingang wiederholt, aber die gleiche Gesamtzahl an Nachrichtenblöcken beibehält). Der Benchmark-Code und die SHA-256-Schaltungsimplementierungen finden Sie in diesem Repository.
Darüber hinaus haben wir für jedes System ein Benchmarking anhand der folgenden Leistungskennzahlen durchgeführt:
Zeit für die Beweiserstellung (einschließlich Zeit für die Zeugenerstellung)
Maximale Speichernutzung während der Proof-Generierung
Durchschnittliche CPU-Auslastung in % während der Proof-Generierung. (Diese Metrik spiegelt den Grad der Parallelisierung während der Proof-Generierung wider.)
Bitte beachten Sie, dass wir einige „vage“ Annahmen bezüglich der Beweisgröße und der Kosten der Beweisüberprüfung machen, da diese Aspekte durch eine Komposition mit Groth16/KZG vor dem Gang in die Kette gemildert werden können.
Die Maschinen
Wir haben unser Benchmarking auf zwei verschiedenen Maschinen durchgeführt:
Linux-Server: 20 Kerne @2,3 GHz, 384 GB Speicher
Macbook M1 Pro: 10 Kerne @3,2 GHz, 16 GB Speicher
Der Linux-Server wurde verwendet, um das Szenario mit vielen CPU-Kernen und reichlich Speicher zu simulieren. Während das Macbook M1 Pro, das häufig für Forschung und Entwicklung verwendet wird, über eine leistungsstärkere CPU mit weniger Kernen verfügt.
Wir haben Multithreading aktiviert, sofern dies optional war, haben in diesem Benchmark jedoch keine GPU-Beschleunigung verwendet. Wir planen, GPU-Benchmarking in unsere zukünftige Arbeit einzubeziehen.
Benchmark Ergebnisse
Anzahl der Einschränkungen
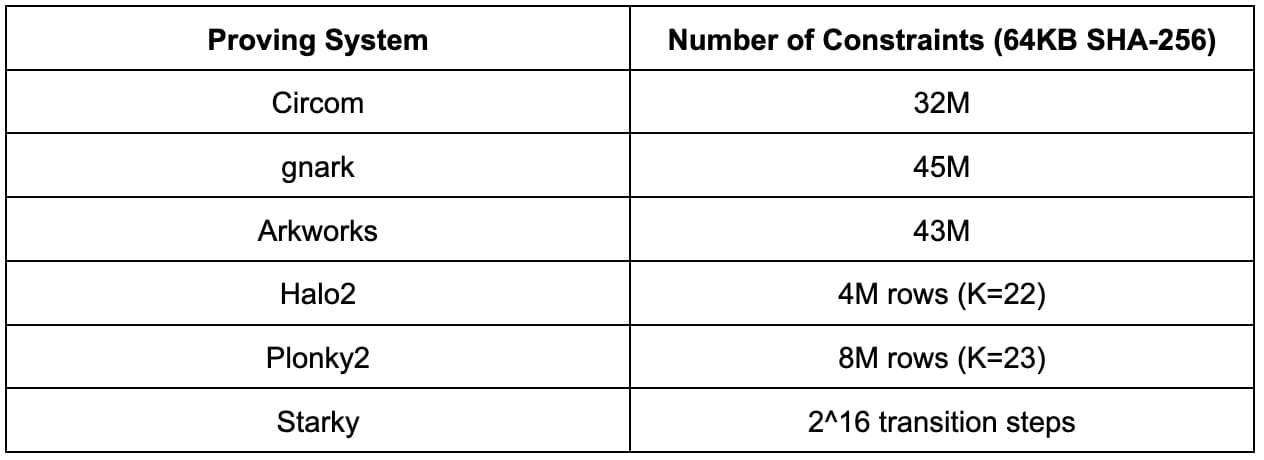
Bevor wir zu den detaillierten Benchmarking-Ergebnissen übergehen, ist es sinnvoll, zunächst die Komplexität des SHA-256 zu verstehen, indem man sich die Anzahl der Einschränkungen in jedem Prüfsystem ansieht. Es ist wichtig zu wissen, dass die Einschränkungszahlen in verschiedenen Arithmetisierungsschemata nicht direkt vergleichbar sind.
Die folgenden Ergebnisse entsprechen einer Vorschaubildgröße von 64 KB. Bei anderen Vorschaubildgrößen können die Ergebnisse zwar abweichen, sie können jedoch ungefähr linear skaliert werden.
Circom, Gnark und Arkworks verwenden alle dieselbe R1CS-Arithmetisierung, und die Anzahl der R1CS-Einschränkungen zum Berechnen von 64 KB SHA-256 beträgt ungefähr 30 M bis 45 M. Der Unterschied zwischen Circom, Gnark und Arkworks ist wahrscheinlich auf Implementierungsunterschiede zurückzuführen.
Halo2 und Plonky2 verwenden beide die Plonkish-Arithmetisierung, bei der die Anzahl der Zeilen zwischen 2^22 und 2^23 liegt. Die Implementierung von SHA-256 in Halo2 ist aufgrund der Verwendung von Nachschlagetabellen viel effizienter als die in Plonky2.
Starky verwendet AIR-Arithmetisierung, bei der die Ausführungsverfolgungstabellen 2^16 Übergangsschritte erfordern.
Zeit für die Beweiserstellung
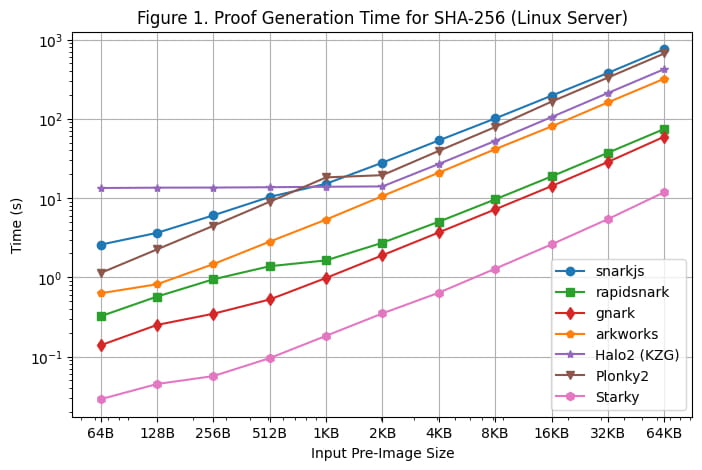
[Abbildung 1] veranschaulicht die Beweisgenerierungszeit jedes Frameworks für SHA-256 über die verschiedenen Pre-Image-Größen unter Verwendung des Linux-Servers. Wir können die folgenden Beobachtungen machen:
Für SHA-256 generieren Groth16-Frameworks (Rapidsnark, Gnark und Arkworks) Beweise schneller als Plonk-Frameworks (Halo2 und Plonky2). Dies liegt daran, dass SHA-256 hauptsächlich aus bitweisen Operationen besteht, bei denen Wire-Werte entweder 0 oder 1 sind. Für Groth16 reduziert dies die meisten Berechnungen von der elliptischen Kurvenskalarmultiplikation auf die elliptische Kurvenpunktaddition. Wire-Werte werden jedoch nicht direkt in den Berechnungen von Plonk verwendet, sodass die spezielle Wire-Struktur in SHA-256 den in Plonk-Frameworks erforderlichen Rechenaufwand nicht reduziert.
Unter allen Groth16-Frameworks sind Gnark und Rapidsnark 5-10-mal schneller als Arkworks und Snarkjs. Dies ist ihrer überlegenen Fähigkeit zu verdanken, mehrere Kerne zur Parallelisierung der Beweisgenerierung zu nutzen. Gnark ist 25 % schneller als Rapidsnark.
Bei den Plonk-Frameworks ist Plonky2 bei SHA-256 50 % langsamer als Halo2, wenn eine größere Pre-Image-Größe von >= 4 KB verwendet wird. Dies liegt daran, dass die Implementierung von Halo2 stark eine Nachschlagetabelle verwendet, um bitweise Operationen zu beschleunigen, was zu 2x weniger Zeilen als bei Plonky2 führt. Wenn wir jedoch Plonky2 und Halo2 mit der gleichen Anzahl von Zeilen vergleichen (z. B. SHA-256 über 2 KB in Halo2 vs. SHA-256 über 4 KB in Plonky2), ist Plonky2 50 % schneller als Halo2. Wenn wir SHA-256 mit einer Nachschlagetabelle in Plonky2 implementieren, sollten wir erwarten, dass Plonky2 schneller ist als Halo2, obwohl die Plonky2-Beweisgröße größer ist.
Wenn andererseits die Größe des Eingabe-Pre-Image klein ist (<=512 Bytes), ist Halo2 langsamer als Plonky2 (und andere Frameworks), da die festen Einrichtungskosten der Nachschlagetabelle für den Großteil der Einschränkungen verantwortlich sind. Mit zunehmender Größe des Pre-Image wird die Leistung von Halo2 jedoch konkurrenzfähiger, mit einer Proof-Generierungszeit, die für Pre-Image-Größen bis zu 2 KB konstant bleibt und dann fast linear skaliert, wie in der Grafik zu sehen ist.
Wie erwartet ist die Beweisgenerierungszeit von Starky wesentlich kürzer (5x-50x) als bei jedem SNARK-Framework, dies geht jedoch auf Kosten einer viel größeren Beweisgröße.
Eine zusätzliche Anmerkung besteht darin, dass selbst wenn die Schaltungsgröße linear zur Größe des Urbildes ist, die Beweisgenerierung für SNARKs aufgrund der O(nlogn) FFT überlinear wächst (obwohl dies auf dem Diagramm aufgrund des logarithmischen Maßstabs nicht offensichtlich ist).
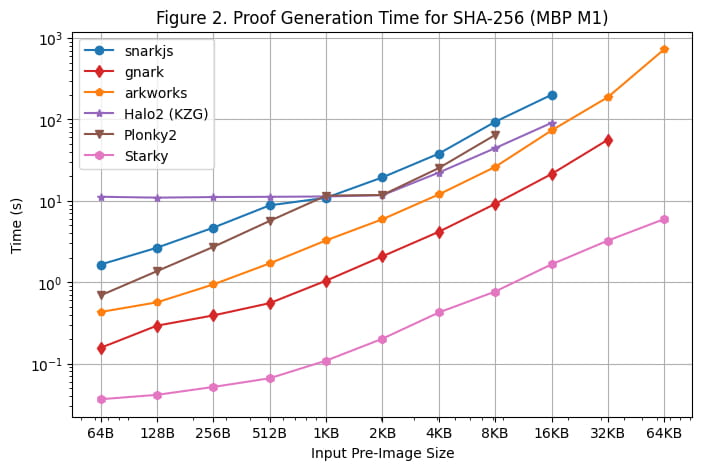
Wir haben auch einen Zeitbenchmark für die Beweisgenerierung auf dem Macbook M1 Pro durchgeführt, wie in [Abbildung 2] dargestellt. Es ist jedoch wichtig zu beachten, dass Rapidsnark aufgrund fehlender Unterstützung für die arm64-Architektur nicht in diesen Benchmark aufgenommen wurde. Um Snarkjs auf arm64 zu verwenden, mussten wir den Zeugen mit Webassembly generieren, was langsamer ist als die auf dem Linux-Server verwendete C++-Zeugengenerierung.
Beim Ausführen des Benchmarks auf dem Macbook M1 Pro gab es mehrere zusätzliche Beobachtungen:
Mit Ausnahme von Starky traten bei allen SNARK-Frameworks Out-of-Memory-Fehler (OOM) auf oder sie verwendeten Swap-Speicher (was zu einer längeren Testzeit führte), wenn die Größe des Pre-Image zu groß wurde. Insbesondere begannen Groth16-Frameworks (snarkjs, gnark, Arkworks) Swap-Speicher zu verwenden, wenn die Größe des Pre-Image größer oder gleich 8 KB war, und gnark stieß bei 64 KB auf OOM. Bei Halo2 trat ein Speicherlimit auf, wenn die Größe des Pre-Image größer oder gleich 32 KB war. Plonky2 begann Swap-Speicher zu verwenden, wenn die Größe des Pre-Image größer oder gleich 8 KB war.
FRI-basierte Frameworks (Starky und Plonky2) waren auf dem Macbook M1 Pro etwa 60 % schneller als auf dem Linux-Server, während andere Frameworks ähnliche Testzeiten wie die auf dem Linux-Server aufwiesen. Infolgedessen erreichte Plonky2 auf dem Macbook M1 Pro fast die gleiche Testzeit wie Halo2, obwohl die Nachschlagetabelle in Plonky2 nicht verwendet wurde. Der Hauptgrund dafür ist, dass das Macbook M1 Pro eine leistungsstärkere CPU, aber weniger Kerne hat. FRI führt hauptsächlich Hash-Operationen durch, die empfindlicher auf CPU-Taktzyklen reagieren, aber nicht so parallelisierbar sind wie KZG/Groth16.
Maximale Speicherauslastung
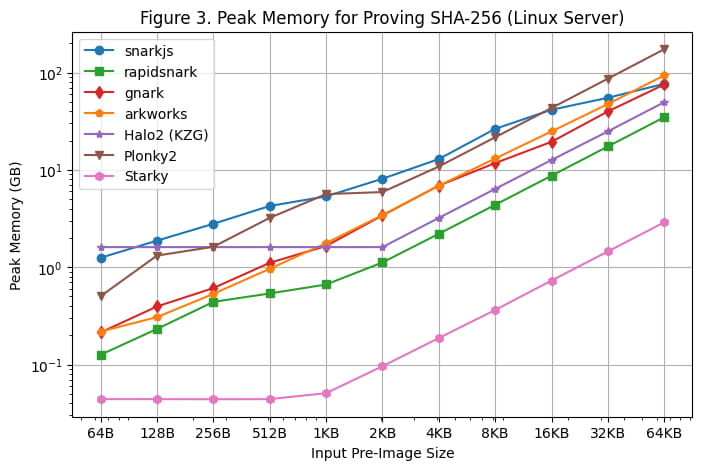
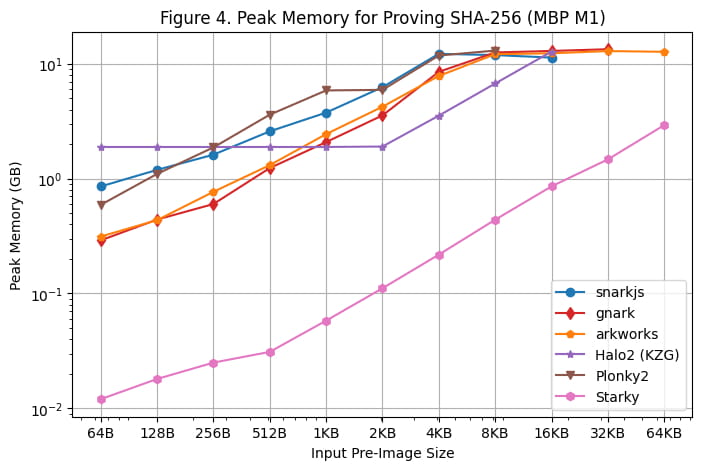
Die maximale Speichernutzung während der Proof-Generierung auf dem Linux-Server und dem Macbook M1 Pro ist in [Abbildung 3] bzw. [Abbildung 4] dargestellt. Basierend auf diesen Benchmarking-Ergebnissen können folgende Beobachtungen gemacht werden:
Rapidsnark ist von allen SNARK-Frameworks das speichereffizienteste. Wir sehen auch, dass Halo2 aufgrund der festen Einrichtungskosten der Nachschlagetabelle mehr Speicher verwendet, wenn die Größe des Pre-Image kleiner ist, aber insgesamt weniger Speicher verbraucht, wenn die Größe des Pre-Image größer ist.
Starky ist mehr als 10x speichereffizienter als SNARK-Frameworks. Dies liegt teilweise daran, dass es weniger Zeilen verwendet.
Es ist zu beachten, dass die maximale Speichernutzung auf dem Macbook M1 Pro relativ flach bleibt, da die Größe des Pre-Image aufgrund der Verwendung des Swap-Speichers groß wird.
CPU-Auslastung
Wir haben den Grad der Parallelisierung für jedes Beweissystem bewertet, indem wir die durchschnittliche CPU-Auslastung während der Beweisgenerierung für SHA-256 über einen 4-KB-Pre-Image-Eingang gemessen haben. Die folgende Tabelle zeigt die durchschnittliche CPU-Auslastung (und die durchschnittliche Auslastung pro Kern in den Klammern) sowohl auf dem Linux-Server (mit 20 Kernen) als auch auf dem Macbook M1 Pro (mit 10 Kernen).
Die wichtigsten Beobachtungen sind wie folgt:
Gnark und Rapidsnark weisen die höchste CPU-Auslastung auf dem Linux-Server auf, was auf ihre Fähigkeit hinweist, mehrere Kerne effizient zu nutzen und die Beweisgenerierung zu parallelisieren. Halo2 weist ebenfalls eine gute Parallelisierungsleistung auf.
Die meisten Frameworks weisen auf dem Linux-Server eine doppelt so hohe CPU-Auslastung auf wie auf dem Macbook Pro M1. Die Ausnahme hiervon ist snarkjs.
Obwohl anfängliche Erwartungen bestanden, dass FRI-basierte Frameworks (Plonky2 und Starky) Schwierigkeiten haben könnten, mehrere Kerne effektiv zu nutzen, schneiden sie in unseren Benchmarks nicht schlechter ab als einige Groth16/KZG-Frameworks. Es bleibt abzuwarten, ob es auf einem Rechner mit noch mehr Kernen (z. B. 100 Kernen) Unterschiede bei der CPU-Auslastung geben wird.

Schlussfolgerung und zukünftige Arbeit
Dieser Blogbeitrag präsentiert einen umfassenden Vergleich der Leistung von SHA-256 auf verschiedenen zk-SNARK- und zk-STARK-Entwicklungsframeworks. Durch die Benchmark-Ergebnisse haben wir Einblicke in die Effizienz und Praktikabilität jedes Frameworks für Entwickler gewonnen, die prägnante Beweise für SHA-256-Operationen benötigen. Groth16-Frameworks (z. B. rapidsnark, gnark) sind bei der Generierung von Beweisen schneller als Plonk-Frameworks (z. B. Halo2, Plonky2). Die Nachschlagetabelle in der Plonkish-Arithmetisierung reduziert die Einschränkungen und die Beweiszeit für SHA-256 erheblich, wenn eine größere Pre-Image-Größe verwendet wird. Darüber hinaus zeigen gnark und rapidsnark eine hervorragende Fähigkeit, mehrere Kerne zur Parallelisierung zu nutzen. Starky hingegen zeigt eine viel kürzere Beweisgenerierungszeit, jedoch auf Kosten einer viel größeren Beweisgröße. In Bezug auf die Speichereffizienz übertreffen rapidsnark und Starky andere Frameworks.
Da dies die ersten Schritte zum Aufbau des Pantheons von ZKP sind, erkennen wir an, dass dieses Benchmark-Ergebnis noch weit davon entfernt ist, das endgültige umfassende Testfeld zu sein, das wir eines Tages anstreben. Wir begrüßen Feedback und Kritik und sind offen dafür. Wir laden alle ein, zu dieser Initiative beizutragen, die ZKP für Entwickler einfacher und zugänglicher machen soll. Wir sind auch bereit, einzelnen Mitwirkenden Zuschüsse zu gewähren, um die Kosten für Rechenressourcen für Benchmarking im großen Maßstab zu decken. Gemeinsam können wir die Effizienz und Praktikabilität von ZKP zum Nutzen der breiteren Community verbessern.