
Wichtigste Erkenntnisse
Das Ledger von Binance speichert Kontostände und Transaktionen und ermöglicht es Diensten außerdem, Transaktionen durchzuführen.
Es schafft die Voraussetzungen für hohen Durchsatz, Verfügbarkeit rund um die Uhr und Datengenauigkeit auf Bitebene.
Die Rolle von Binance Ledger hinter den Kulissen macht es zu einer der wichtigsten Technologien von Binance. Hier erfahren Sie genau, wie es funktioniert und welche Probleme es im Betrieb der größten Kryptobörse der Welt löst.

Haben Sie sich schon einmal gefragt, was Binance so antreibt? Angesichts der Notwendigkeit, täglich Millionen von Transaktionen über eine riesige Benutzerbasis hinweg abzuwickeln, lohnt es sich, einen Blick darauf zu werfen, was Binance unter der Haube hat.
Grundlage der technischen Abläufe von Binance ist das Ledger. Das Ledger speichert Kontostände und Transaktionen und ermöglicht es Diensten, Transaktionen durchzuführen.
Binance stellt hohe Anforderungen an das Ledger
Wie Sie sich vorstellen können, sind die Anforderungen an das Ledger hoch, um die enorme Benutzernachfrage zu erfüllen. Es gibt drei wichtige Punkte, die berücksichtigt werden müssen:
Hoher Durchsatz mit der Möglichkeit einer großen Anzahl von TPS (Transaktionen pro Sekunde) zu Spitzenzeiten.
24/7-Verfügbarkeit ohne Ausfallzeiten.
Datengenauigkeit auf Bit-Ebene, ohne Geldverlust oder Transaktionsfehler.
Schauen wir uns ein Beispiel für einen einfachen Eintrag im Ledger an. Hier ist eine gängige Transaktion, bei der Konto 1 1 BTC auf Konto 2 überweist.
Saldo vor der Transaktion:
KONTO-ID | VERMÖGENSWERT | GLEICHGEWICHT |
1 | BTC | 10 |
2 | BTC | 0,1 |
Tabelle 1
Saldo nach der Transaktion:
KONTO-ID | VERMÖGENSWERT | GLEICHGEWICHT |
1 | BTC | 9 |
2 | BTC | 1.1 |
Tabelle 2
In dieser Transaktion gibt es zwei Befehle:
Konto 1 -1 BTC
Konto 2 +1 BTC
Wenn die Transaktion durchgeführt wird, werden zwei Saldenprotokolle zur Prüfung und Abstimmung gespeichert.
KONTO-ID | VERMÖGENSWERT | DELTA | TX_ID | ZEIT |
100001 | BTC | -1 | tx-001 | 01.01.2022 01:02:03 |
100002 | BTC | +1 | tx-001 | 01.01.2022 01:02:03 |
Tisch 3
Die Standard-Branchenlösung
Eine branchenübliche Ledger-Lösung basiert auf einer relationalen Datenbank. Um auf das vorherige Beispiel zurückzukommen: Die beiden Befehle der Transaktion können in zwei SQL-Anweisungen übersetzt und in einer Datenbanktransaktion ausgeführt werden (Tabelle 4).
Transaktion beginnen; |
UPDATE Balance_1 Setze Balance = Balance - 1 WO Konto-ID=1 und Vermögenswert = „BTC“ und Guthaben – 1 >= 0; Wenn 0 Zeilen betroffen sind, dann Rollback; |
UPDATE balance_2 setze Balance = Balance + 1 WO Konto-ID=2 und Vermögenswert = „BTC“ und Guthaben + 1 >= 0; Wenn 0 Zeilen betroffen sind, dann Rollback; |
begehen; |
Tabelle-4
Die Vorteile der Lösung
Die Umsetzung ist ganz einfach.
Zur Verbesserung der Leistung können Sie problemlos gängige Datenbankoptimierungstechniken wie Lese-/Schreibaufteilung und Sharding anwenden.
Für die DevOps ist es nicht schwer, sich nach einem Failover zu erholen und eine kommerzielle Datenbank zu überwachen und zu pflegen.
Die Nachteile der Lösung
Bei Race Conditions aufgrund von Zeilensperren sinkt der TPS-Wert stark ab.
Es ist schwierig, horizontal zu skalieren, um die Leistung zu verbessern.
Das Hot-Account-Problem
Leider erfüllt die oben gezeigte Branchenlösung die hohen Anforderungen von Binance nicht. Wenn eine Transaktion stattfindet, muss sie die Zeilensperren aller beteiligten Zeilen aufrechterhalten. Während einige Konten relativ wenige Transaktionen verarbeiten müssen, gibt es natürlich stark ausgelastete Konten mit vielen gleichzeitigen Transaktionen. In diesem Fall kann nur eine Transaktion die Zeilensperre des Kontos aufrechterhalten.
Die anderen Transaktionen können dann nichts anderes tun, als auf die Freigabe der Sperre zu warten. Wir bezeichnen diese Situation als Hot-Account-Problem und interne Tests zeigen, dass TPS in dieser Situation mindestens 10 Mal sinkt. Sie können dieses Problem in Tabelle 5 unten sehen.
Beispiel für ein Hot-Account:
Tx 1 (1 BTC von Konto 1 auf Konto 2 überweisen) | Tx 2 (2 BTC von Konto 1 auf Konto 3 überweisen) |
Transaktion beginnen; | |
Transaktion beginnen; | |
UPDATE Saldo festlegen Saldo = Saldo - 1 WO Konto-ID=1 und Vermögenswert = „BTC“ und Guthaben – 1 >= 0; (Zeile gesperrt: Konto-ID = 1 und Vermögenswert = „BTC“) Wenn 0 Zeilen betroffen sind, dann Rollback; | UPDATE Saldo festlegen Saldo = Saldo - 2 WO Konto-ID = 1 und Vermögenswert = „BTC“ und Balance - 2 >= 0; Wenn 0 Zeilen betroffen sind, dann Rollback; |
UPDATE Saldo festlegen Saldo = Saldo + 1 WO Konto-ID=2 und Vermögenswert = „BTC“ und Guthaben + 1 >= 0; Wenn 0 Zeilen betroffen sind, dann Rollback; | warten sperren |
begehen; | warten sperren |
Sperre erhalten, ausführen | |
UPDATE Saldo festlegen Saldo = Saldo + 2 WO Konto-ID=3 und Vermögenswert = „BTC“ und Guthaben + 1 >= 0; Wenn 0 Zeilen betroffen sind, dann Rollback; | |
begehen; |
Tabelle-5
Die Ledger-Lösung von Binance
Wie lösen wir das Hot-Account-Problem?
Eine mögliche Lösung für unser Problem besteht darin, das Multithread-Modell innovativ in einen Singlethread-Modus umzuwandeln. Dadurch wird das Race-Condition-Problem vermieden und es kommt nicht zu Hot-Account-Problemen.
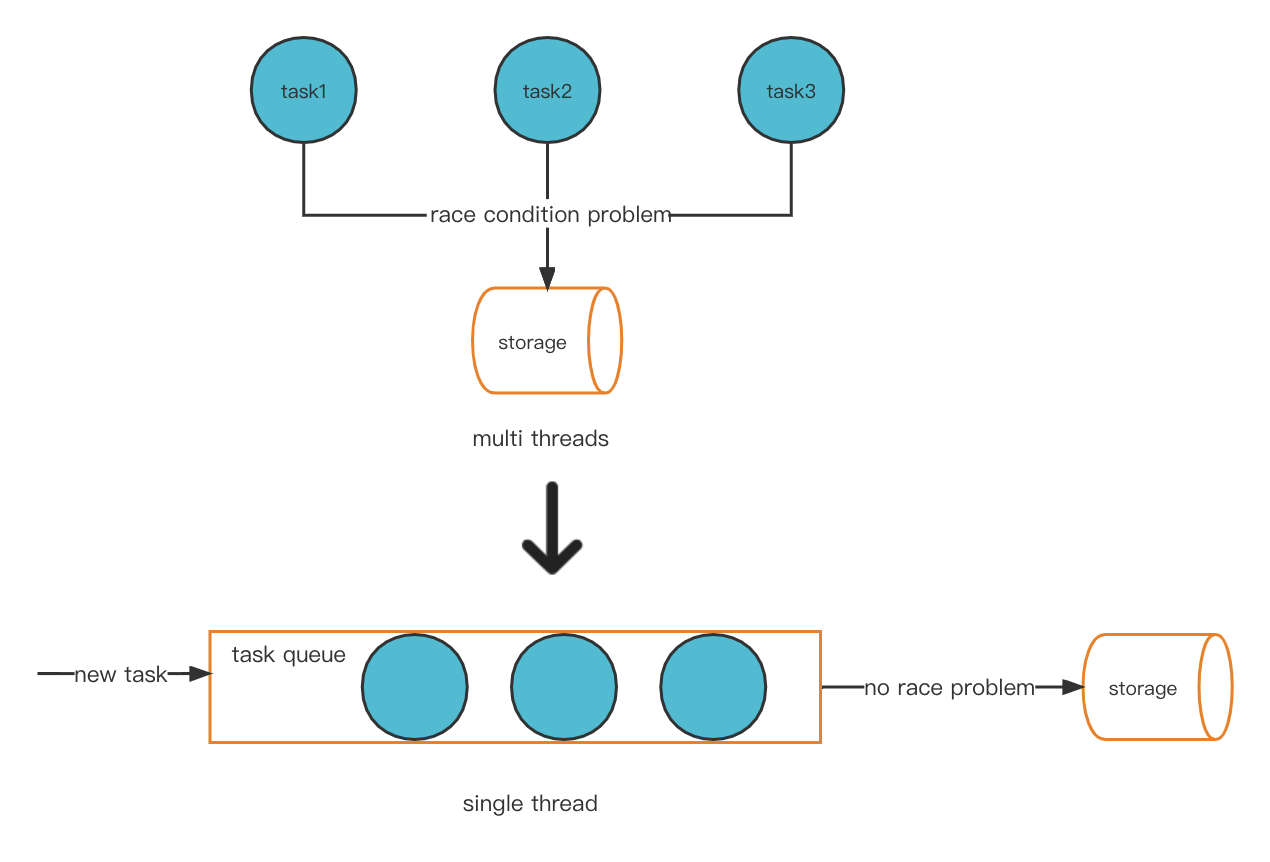
Neues Thread-Modell
Nachrichtenbasierte Kommunikation
Nach der Implementierung unseres neuen Thread-Modells muss ein Kommunikationsproblem gelöst werden. Die Zustandsmaschinenschicht ist Single-Thread, die Netzwerkschicht jedoch Multi-Thread. Wie können wir also effizient zwischen beiden kommunizieren?
Der nächste Schritt im Puzzle ist ein Disruptor [1]. Er erzeugt eine lock-freie, hochperformante Warteschlange auf Basis eines Ringpuffer-Designs.
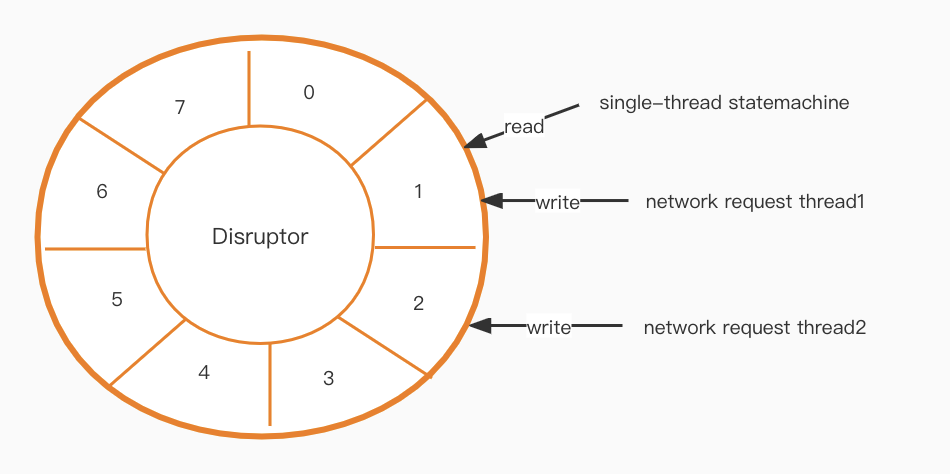
Hohe Verfügbarkeit
Bisher haben wir durch die Verwendung eines In-Memory-Modells und des lokalen Speichers RocksDB [2] eine hohe Leistung erreicht. Doch nun steht uns eine neue Herausforderung bevor. Jetzt müssen wir für eine hohe Datenverfügbarkeit sorgen.
Um die Datenkonsistenz zwischen den Knoten zu gewährleisten, verwenden wir einen Raft-Konsensalgorithmus [3]. Das bedeutet, dass die Anzahl der Datensicherungen der Anzahl der vorhandenen Nicht-Leader-Knoten entspricht. Der Algorithmus stellt außerdem sicher, dass das System auch dann noch funktioniert, wenn mindestens die Hälfte der Knoten intakt ist, um eine hohe Serviceverfügbarkeit zu gewährleisten.
Raft-Domänenrollen:
Anführer. Der Anführer verarbeitet alle Clientanforderungen und repliziert den Vorgang an alle Follower.
Follower. Follower folgen dem Anführer bei allen Operationen. Wenn der Anführer ausfällt, wird einer der Follower zum neuen Anführer gewählt.
Lernender. Lernende sind nicht stimmberechtigte Follower, die jeden idempotenten/transaktionalen Änderungsdatensatz an andere Dienste senden.
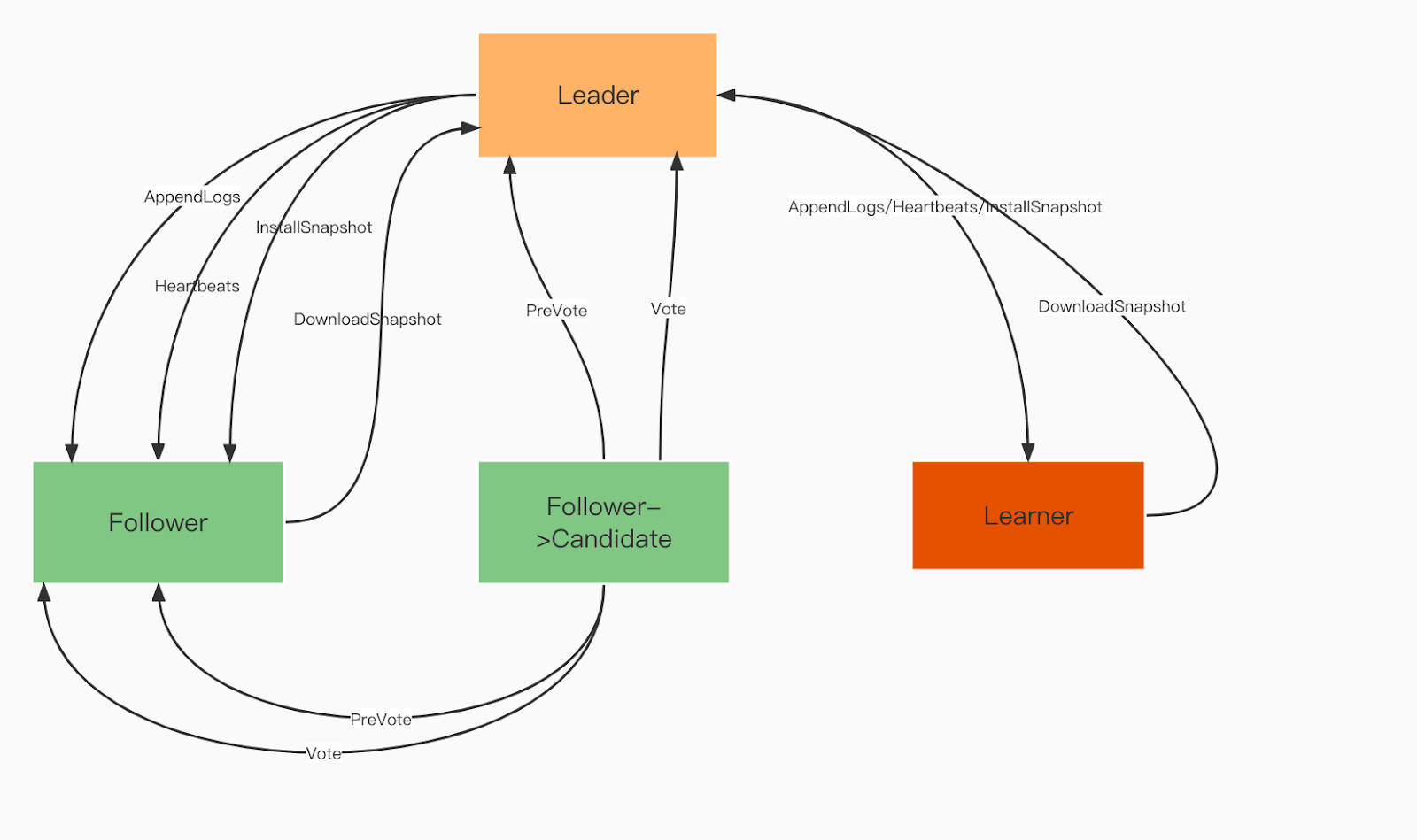
Raft-Domänenrollen
CQRS (Trennung der Verantwortung für Befehlsabfragen)
Ein weiteres wichtiges Kriterium, das wir sicherstellen möchten, ist die höhere Schreibleistung des Ledgers und seine Fähigkeit, vielfältigere Abfragebedingungen zu erfüllen. Dazu müssen wir verschiedene Domänen erstellen. Die Raft-Domäne bietet effizienteres Schreiben basierend auf Rocksdb+Raft, und die Ansichtsdomäne hört die Nachrichten der Raft-Domäne ab und speichert sie für externe Abfragen in der relationalen Datenbank. Wir können auch eine Trennung der Befehlsabfrageverantwortung auf Architekturebene implementieren.
Ledger-Architektur
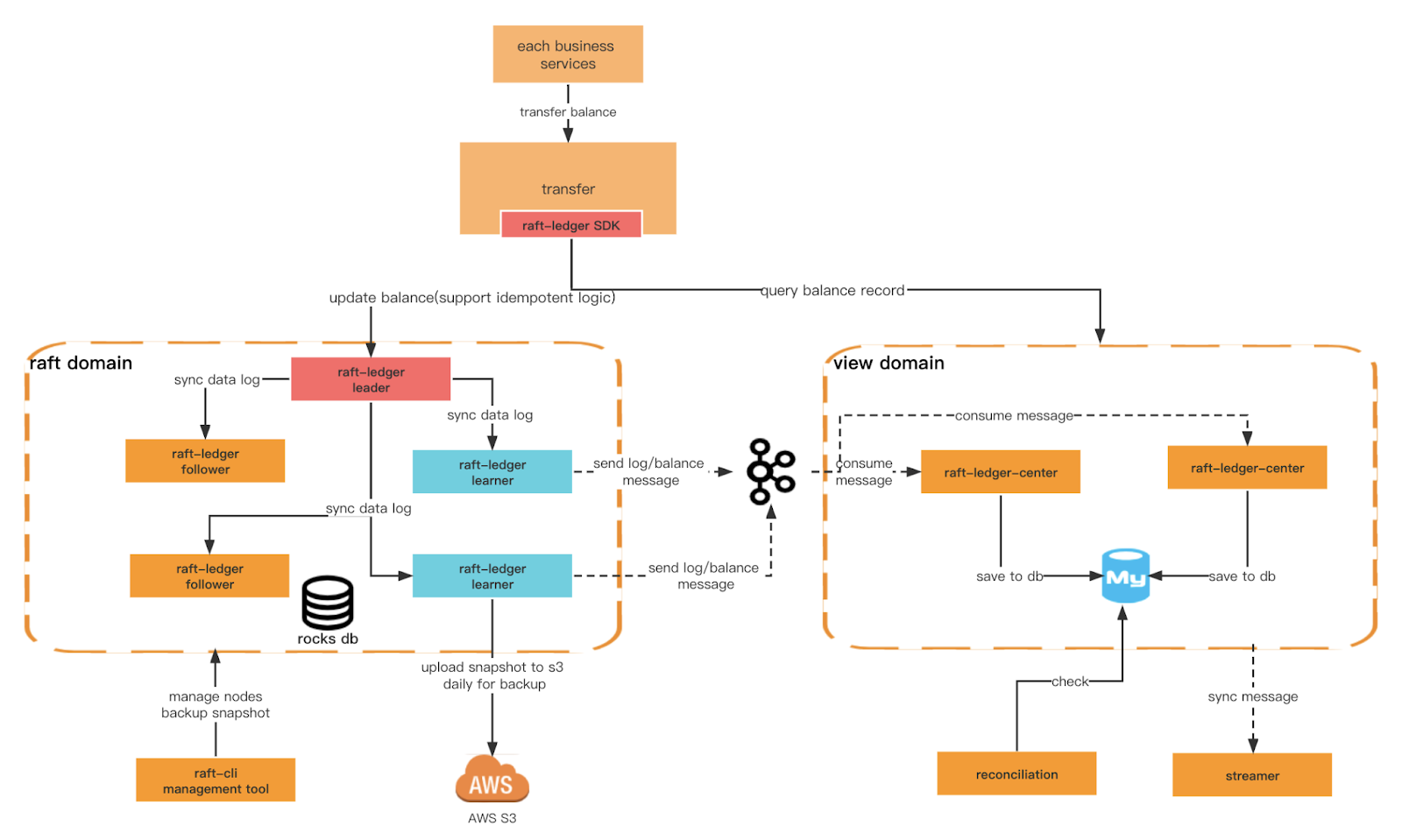
Gesamtarchitektur
Begriffe zwischen Raft und Ledger:
Floß | Hauptbuch |
replizierte Zustandsmaschinen | Ledger-Knoten |
Zustand | Gleichgewicht |
Befehl | Transaktion |
Tabelle-6
Domänenrollen anzeigen
Floß-Ledger-Zentrum
Nutzen Sie die vom Lernenden erstellte Nachricht und speichern Sie die Transaktions- und Saldendaten zu Abfragezwecken in MySQL.
Anfragebearbeitung
Eine Transaktionsanforderung durchläuft zunächst die Netzwerkschicht, die Ledger-Schicht (Anforderungshandler) und die Raft-Schicht (Raft-Log-Sync). Anschließend geht sie zurück zur Ledger-Schicht (Zustandsmaschine), zur Netzwerkschicht (Antworthandler) und gibt schließlich eine Antwort an den Client zurück.
Die Daten werden über die Warteschlange zwischen den beiden Schichten übergeben.
Netzwerkschicht – Deserialisieren Sie die RPC-Anforderung und stellen Sie sie in die Anforderungswarteschlange.
Ledger-Ebene – Ruft die Anfrage aus der Warteschlange ab und bereitet den Kontext vor. Anschließend werden die Metadaten der Anfrage in die Raft-Warteschlange eingefügt.
Raft-Ebene – Ruft die Anforderungsmetadaten aus der Raft-Warteschlange ab und synchronisiert sie mit allen Followern. Anschließend wird das Ergebnis in die Anwendungswarteschlange gestellt.
Ledger-Ebene – Ruft die Daten aus der Anwendungswarteschlange ab und aktualisiert die Zustandsmaschine. Anschließend wird das Ergebnis in die Antwortwarteschlange gestellt.
Netzwerkschicht – Holen Sie das Ergebnis aus der Antwortwarteschlange und erstellen und serialisieren Sie die Antwortdaten, bevor Sie sie an den Client zurückgeben.
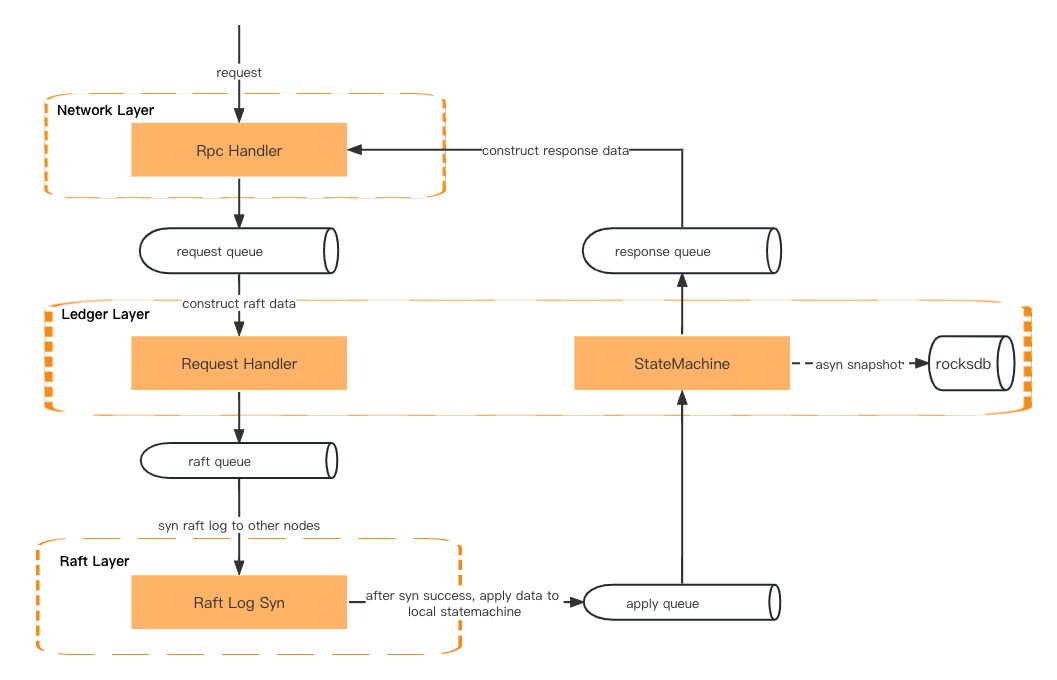
Anfragebearbeitung
Datenwiederherstellung
Jeder Ledger-Knoten löst einen generischen Snapshot basierend auf einem Zeitraum aus. Zusätzlich implementieren wir auch einen konsistenten Snapshot. Jeder Knoten wird beim gleichen Raft-Log-Index ausgelöst, um sicherzustellen, dass die Zustandsmaschine genau gleich ist, wenn jeder Knoten einen Snapshot auslöst. Der Snapshot wird dann zur Überprüfung durch Checker und als Cold Backup auf S3 hochgeladen.
Beim Neustart liest Ledger den lokalen Snapshot und erstellt die Zustandsmaschine neu. Anschließend spielt es das lokale Raft-Protokoll erneut ab und synchronisiert das neueste Protokoll vom Leader, bis es den neuesten Index einholt. Wenn der lokale Snapshot oder das Raft-Protokoll nicht vorhanden ist, wird es vom Leader abgerufen.
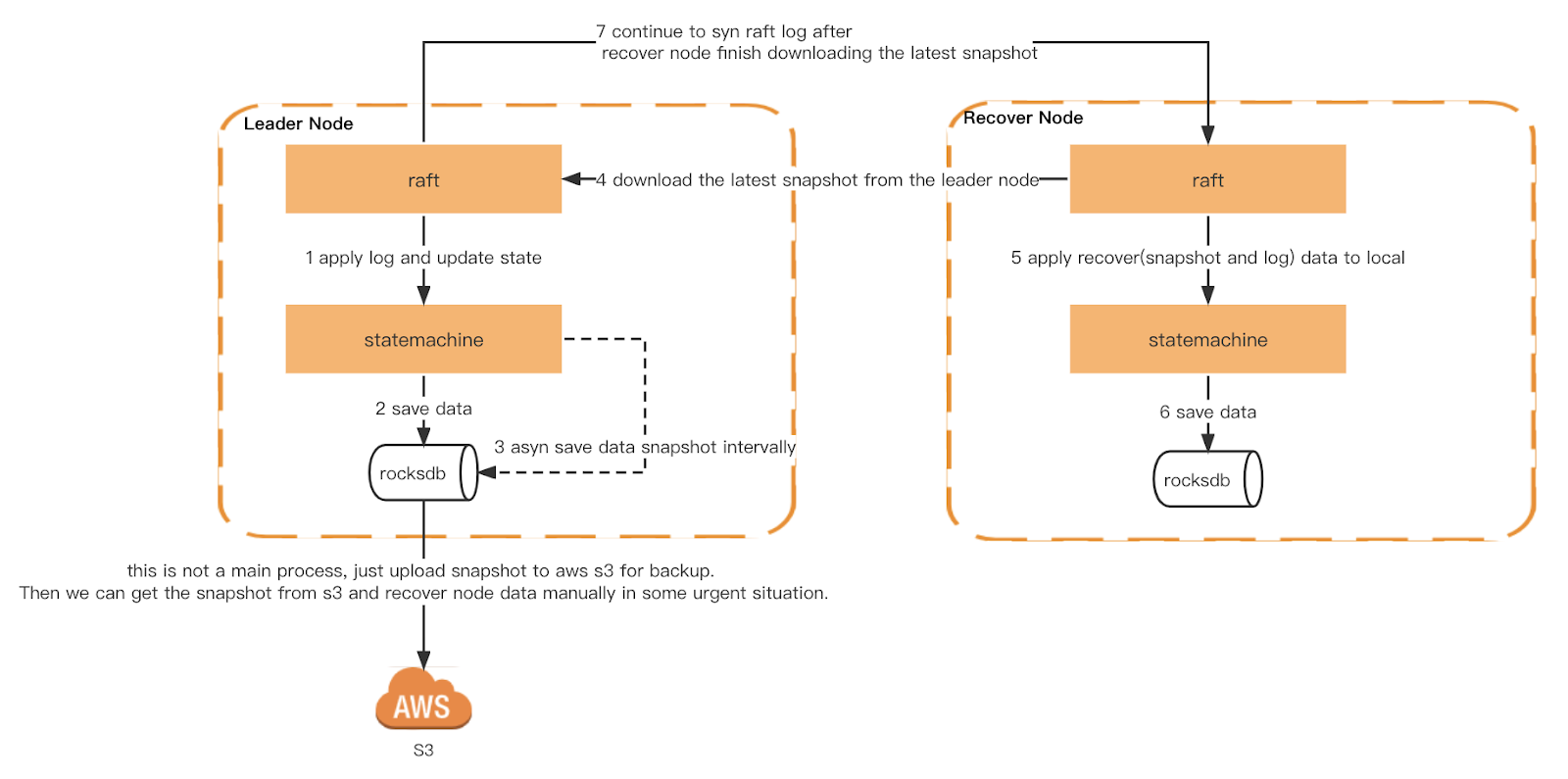
Schnappschuss und Wiederherstellung
Katastrophentoleranz
Um die Verfügbarkeit und Fehlertoleranz zu verbessern, werden Ledger-Knoten in verschiedenen Zonen bereitgestellt. Solange mehr als die Hälfte der Knoten fehlerfrei ist, gehen die Daten nicht verloren und das Failover ist in einer Sekunde abgeschlossen.
Selbst wenn der gesamte Cluster ausfällt, was sehr unwahrscheinlich ist, können wir den Cluster immer noch über den konsistenten Snapshot wiederherstellen, der in Amazon S3 gespeichert ist, und die neuesten verlorenen Daten über das nachgelagerte System abrufen.
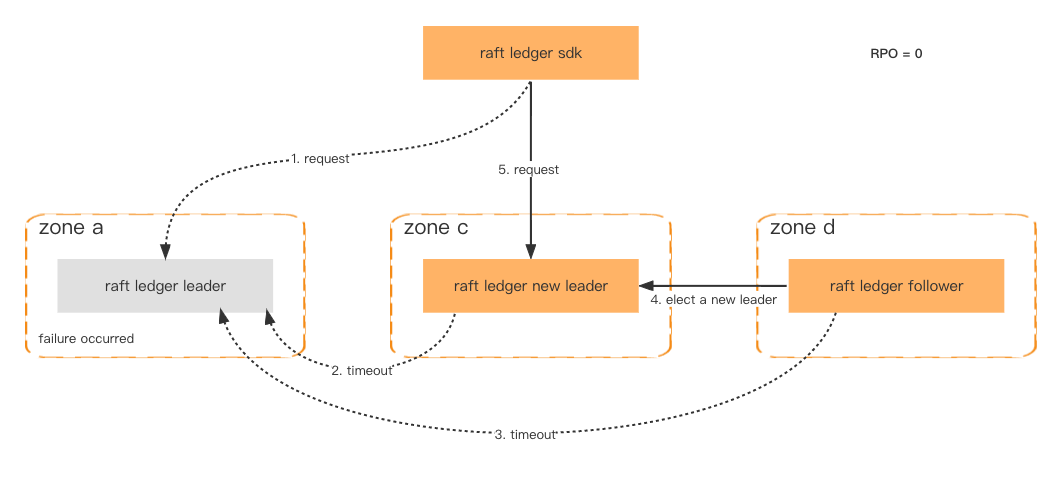
Fehlertoleranz
Leistung
Die folgende Tabelle zeigt die Hardwarespezifikationen für den Leistungstest
Komponente | Instanztyp | Netzwerkbandbreite (Gbit/s) | EBS-Bandbreite (Gbit/s) | EBS-Speichertyp |
Anführer/ Anhänger | M6i.4xlarge 16c64g | Bis zu 12,5 | Bis zu 10 | 2T GP3 * 3 IOPS6000 625 MB/s |
Lerner | M6i.4xlarge 16c64g | Bis zu 12,5 | Bis zu 10 | 2T GP3 * 3 IOPS6000 625 MB/s |
Bank | C5.4xgroß 16c32g | Bis zu 10 | 4,750 | Nur Root-Volume |
Interne Tests beweisen, dass ein 4-Knoten-Cluster (ein Leader, zwei Follower und ein Learner) mehr als 10.000 TPS verarbeiten kann. Der Cluster verarbeitet alle Transaktionen konzeptgemäß einzeln. Es gibt keinerlei Sperr- oder Race-Conditions. Daher ist der TPS im Hot-Account-Szenario genauso hoch wie in den normalen Szenarien.
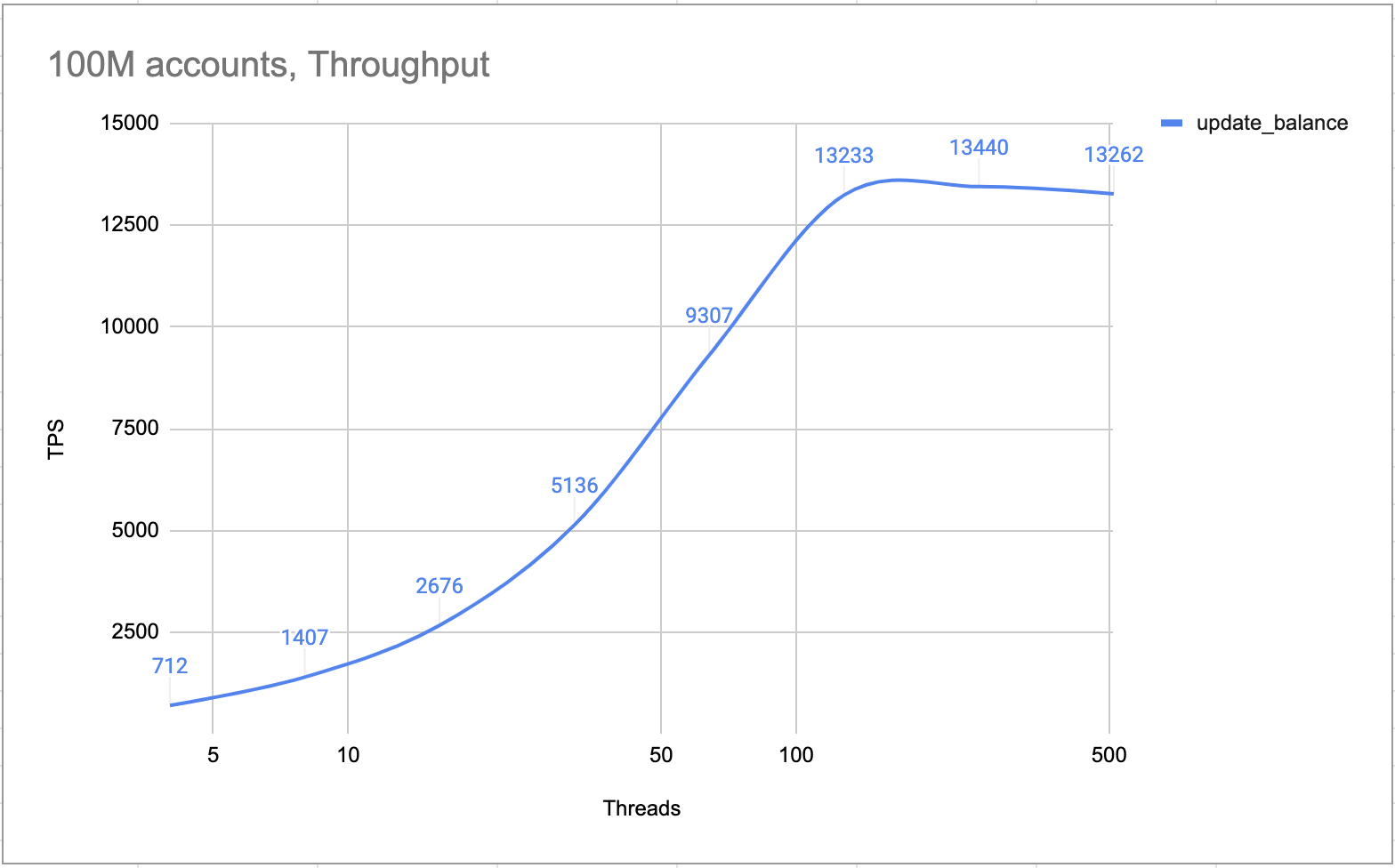
Heißes Konto TPS
Die folgende Abbildung zeigt die Latenz jeder Transaktion. Die meisten Transaktionen konnten innerhalb von 10 ms abgeschlossen werden. Die langsameren Transaktionen konnten innerhalb von 25 ms abgeschlossen werden.
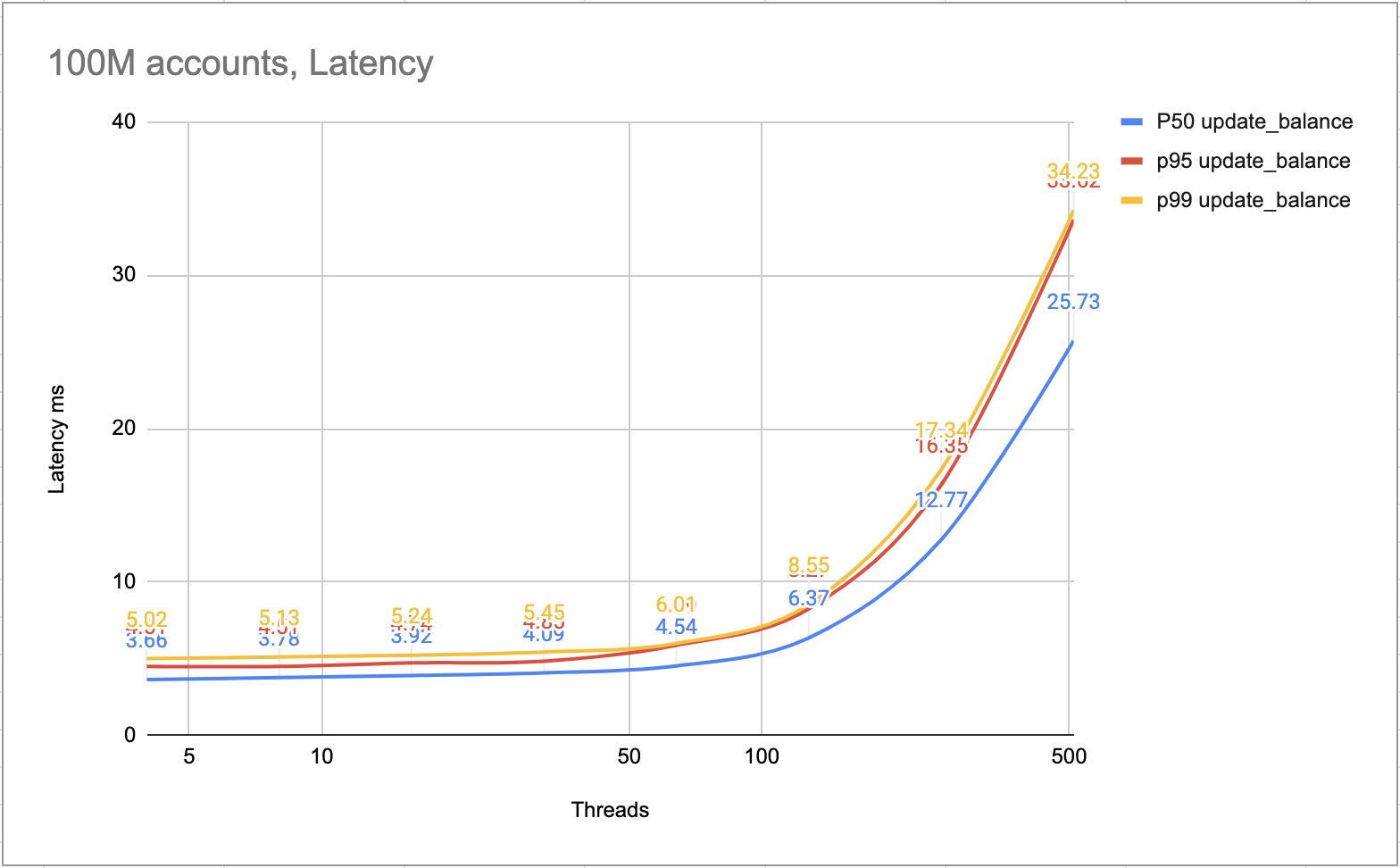
Latenz ms
Unterstützung unserer Dienste mit Binance Ledger
Wie Sie gesehen haben, erfüllt die traditionelle Antwort der Branche auf das Hot-Account-Problem nicht die Bedürfnisse von Binance und seinen Kunden. Durch die Verwendung eines speziell für die Infrastruktur von Binance entwickelten Ansatzes haben wir eines der reibungslosesten Austausch- und Produkterlebnisse auf dem Markt erreicht. Wir freuen uns, unsere Erfahrungen nun mit Ihnen teilen zu können und hoffen, dass Sie besser verstehen, was dazu beiträgt, einen Dienst wie Binance zum Funktionieren zu bringen.
Weitere Informationen zu unserer technologischen Infrastruktur finden Sie im folgenden Artikel:
(Binance Blog) Verwendung von MLOps zum Aufbau einer End-to-End-Pipeline für maschinelles Lernen in Echtzeit
(Binance-Blog) Lernen Sie den CTO kennen: Rohit reflektiert über Krypto, Blockchain, Web3 und seinen ersten Monat bei Binance
Verweise
[1] LMAX-Disruptor
[2] RocksDB
[3] Der Raft-Konsens-Algorithmus