
Die 3D-Avatar-Diffusion ist ein maschineller Lernalgorithmus, der aus einem einzelnen 2D-Bild eines menschlichen Gesichts einen dreidimensionalen (3D) Avatar erstellen kann. Der Avatar kann dann verwendet werden, um ein Virtual-Reality- (VR) oder Augmented-Reality- (AR) Erlebnis zu schaffen oder einfach eine realistische 3D-Ansicht der Person für Spiele oder andere Zwecke bereitzustellen.
Das Diffusionsmodell wurde von einem Forscherteam bei Microsoft Research entwickelt und in einem in der Zeitschrift arXiv veröffentlichten Artikel beschrieben.

Die 3D-Avatar-Diffusion basiert auf einem Typ von maschinellem Lernalgorithmus, der als Diffusionsmodell bezeichnet wird. Diffusionsmodelle sind generative Modelle, was bedeutet, dass sie neue Daten generieren können, die den Trainingsdaten ähnlich sind. Diffusionsmodelle wurden bereits früher verwendet, um 3D-Bilder aus 2D-Bildern zu generieren, aber das ADM ist das erste Diffusionsmodell, das aus einem einzelnen 2D-Bild einen realistischen 3D-Avatar generieren kann.
Um das Modell zu trainieren, nutzten die Forscher einen Datensatz mit über 200.000 3D-Gesichtsmodellen. Der Datensatz umfasste eine große Vielfalt an Gesichtern mit unterschiedlichen Hauttönen, Frisuren und Gesichtszügen. Der ADM konnte dann die Beziehung zwischen dem 2D-Bild und dem 3D-Gesichtsmodell erlernen und aus einem einzigen 2D-Bild einen realistischen 3D-Avatar generieren.
Das Modell kann auch verwendet werden, um einen Avatar aus einem Foto zu generieren, das aus einem anderen Winkel aufgenommen wurde
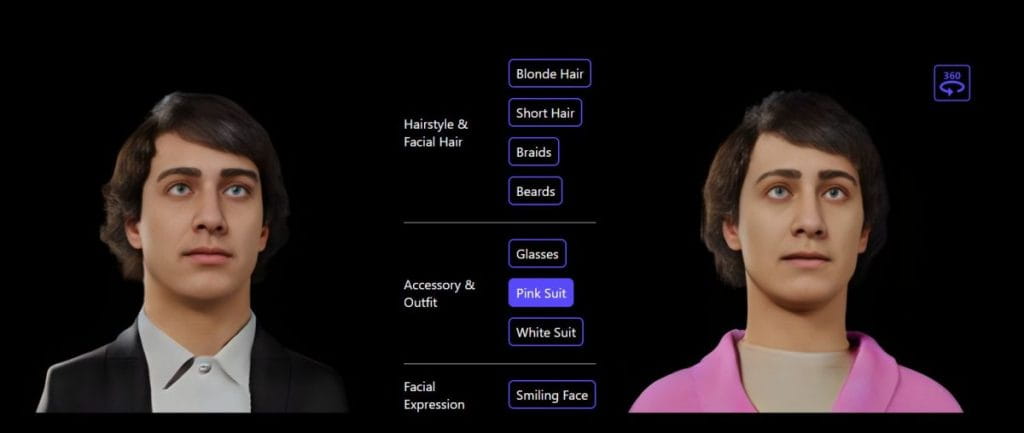 Für den personalisierten 3D-Avatar bietet das Rodin-Modell textgesteuerte Manipulation. Die Bearbeitung in natürlicher Sprache ist eine intuitive Möglichkeit, viele verschiedene 3D-Avatar-Funktionen zu ändern.
Für den personalisierten 3D-Avatar bietet das Rodin-Modell textgesteuerte Manipulation. Die Bearbeitung in natürlicher Sprache ist eine intuitive Möglichkeit, viele verschiedene 3D-Avatar-Funktionen zu ändern.
Diese Studie schlägt ein 3D-generatives Modell vor, das automatisch 3D-digitale Avatare erstellt, die mithilfe von Diffusionsmodellen als neuronale Strahlungsfelder dargestellt werden. Aufgrund der untragbaren Speicher- und Verarbeitungsanforderungen, die mit 3D verbunden sind, ist die Erstellung der umfangreichen Funktionen, die für qualitativ hochwertige Avatare erforderlich sind, ein großes Problem. Die Entwickler schlagen vor, dass das Rollout-Diffusionsnetzwerk (Rodin) dieses Problem löst.
 In Bezug auf Geschlecht, Alter, Rasse, Ausdruck, Gesichtsaccessoires usw. weist das Modell eine außergewöhnliche Generationenvielfalt auf.
In Bezug auf Geschlecht, Alter, Rasse, Ausdruck, Gesichtsaccessoires usw. weist das Modell eine außergewöhnliche Generationenvielfalt auf.
Dieses Netzwerk rollt zahlreiche 2D-Merkmalskarten eines neuronalen Strahlungsfelds in eine einzelne 2D-Merkmalsebene aus, wo das Modell dann eine 3D-bewusste Diffusion ausführt. Das Rodin-Modell verwendet eine 3D-bewusste Faltung, die projizierte Merkmale in der 2D-Merkmalsebene entsprechend ihrer ursprünglichen Beziehung in 3D berücksichtigt, um die dringend benötigte Rechenleistung bereitzustellen und gleichzeitig die Integrität der Diffusion in 3D aufrechtzuerhalten.
Lesen Sie mehr zum Thema KI:
VALL-E: Microsofts neues Zero-Shot-Text-to-Speech-Modell kann jede Stimme in drei Sekunden duplizieren
Microsofts VALL-E scheint die gefährlichste Betrugssoftware aller Zeiten zu sein
Künstler erstellt ein Anti-Diebstahl-Skript zum Schutz von Kunstwerken und verwendet dasselbe Wasserzeichen wie KI-Generatoren
Microsoft und Google im Jahr 2023: Der wichtigste Showdown des Jahres zwischen den KI-Titanen
Der Beitrag „Microsoft hat ein Diffusionsmodell veröffentlicht, mit dem aus einem einzigen Foto einer Person ein 3D-Avatar erstellt werden kann“ erschien zuerst auf Metaverse Post.