

Originaltitel: „Von GPT-1 bis GPT-4, schauen Sie sich den Aufstieg von ChatGPT an“
Ursprünglicher Autor: Alpha Rabbit Research Notes
Was ist ChatGPT?

Was ist ChatGPT?
Kürzlich veröffentlichte OpenAI ChatGPT, ein Modell, das aufgrund seiner Intelligenz auf Konversationsbasis interagieren kann und von vielen Benutzern begrüßt wurde. ChatGPT ist auch ein Verwandter von InstructGPT, das zuvor von OpenAI veröffentlicht wurde. Das ChatGPT-Modell wird mit RLHF (Reinforcement Learning with Human Feedback) trainiert. Möglicherweise ist die Einführung von ChatGPT auch der Auftakt vor dem offiziellen Start von OpenAIs GPT-4.
Was ist GPT? Von GPT-1 bis GPT-3
Generative Pre-trained Transformer (GPT) ist ein Deep-Learning-Modell zur Textgenerierung, das auf im Internet verfügbaren Daten trainiert wird. Es wird zur Beantwortung von Fragen, Textzusammenfassung, maschineller Übersetzung, Klassifizierung, Codegenerierung und Konversations-KI verwendet.
Im Jahr 2018 wurde GPT-1 geboren, was auch das erste Jahr der Vorschulung von Modellen für NLP (Natural Language Processing) war. Leistungsmäßig verfügt GPT-1 über eine gewisse Generalisierungsfähigkeit und kann bei NLP-Aufgaben eingesetzt werden, die nichts mit Supervisionsaufgaben zu tun haben. Zu den üblichen Aufgaben gehören:
Argumentation in natürlicher Sprache: Bestimmen Sie die Beziehung zwischen zwei Sätzen (Eindämmung, Widerspruch, Neutralität).
Frage und Antwort und Argumentation mit gesundem Menschenverstand: Geben Sie einen Artikel und mehrere Antworten ein und geben Sie die Richtigkeit der Antwort aus
Semantische Ähnlichkeitserkennung: Bestimmen Sie, ob zwei Sätze semantisch verwandt sind
Kategorie: Bestimmen Sie, zu welcher Kategorie der Eingabetext gehört
Obwohl GPT-1 einige Auswirkungen auf nicht abgestimmte Aufgaben hat, ist seine Generalisierungsfähigkeit viel geringer als die von fein abgestimmten überwachten Aufgaben. Daher kann GPT-1 nur als ein recht gutes Sprachverständnis-Tool und nicht als Konversations-KI angesehen werden.
GPT-2 kam ebenfalls wie geplant im Jahr 2019 an. GPT-2 führte jedoch nicht allzu viele strukturelle Neuerungen und Designs am ursprünglichen Netzwerk durch, sondern nutzte lediglich mehr Netzwerkparameter und einen größeren Datensatz: Das maximale Modell umfasst insgesamt 48 Schichten und 1,5 Milliarden Parameter. Das Lernziel verwendet ein unbeaufsichtigtes Vortrainingsmodell, um überwachte Aufgaben auszuführen. In Bezug auf die Leistung hat GPT-2 neben den Verständnisfähigkeiten zum ersten Mal in seiner Generation ein starkes Talent gezeigt: Zusammenfassungen lesen, chatten, weiterschreiben, Geschichten erfinden und sogar Fake News, Phishing-E-Mails oder Rollenspiele generieren online. Kein Problem. Nachdem GPT-2 „größer geworden“ war, stellte es seine universellen und leistungsstarken Fähigkeiten unter Beweis und erzielte die damals beste Leistung bei mehreren spezifischen Sprachmodellierungsaufgaben.
Danach erschien GPT-3 als unbeaufsichtigtes Modell (heute oft als selbstüberwachtes Modell bezeichnet) und kann die meisten Aufgaben der Verarbeitung natürlicher Sprache wie problemorientierte Suche, Leseverständnis, semantische Schlussfolgerung und maschinelle Übersetzung nahezu erfüllen ., Artikelgenerierung und automatische Frage und Antwort usw. Darüber hinaus schneidet das Modell bei vielen Aufgaben gut ab, beispielsweise beim Erreichen des aktuellen Stands der Technik bei maschinellen Übersetzungsaufgaben Französisch-Englisch und Deutsch-Englisch. Bei den automatisch generierten Artikeln ist es nahezu unmöglich, zwischen Menschen und Maschinen zu unterscheiden 52 % Genauigkeit, vergleichbar mit zufälligem Raten), und was noch überraschender ist, ist, dass es bei zweistelligen Additions- und Subtraktionsaufgaben eine fast 100 %ige Genauigkeit erreicht und sogar automatisch Code basierend auf der Aufgabenbeschreibung generieren kann. Ein unbeaufsichtigtes Modell hat viele Funktionen und gute Auswirkungen, und es scheint, dass die Menschen die Hoffnung auf allgemeine künstliche Intelligenz darin sehen, dass dies der Hauptgrund dafür sein könnte, dass GPT-3 einen so großen Einfluss hat.
Was genau ist das GPT-3-Modell?
Tatsächlich ist GPT-3 ein einfaches statistisches Sprachmodell. Aus der Perspektive des maschinellen Lernens modellieren Sprachmodelle die Wahrscheinlichkeitsverteilung von Wortsequenzen, d. h. sie verwenden die gesagten Fragmente als Bedingungen, um die Wahrscheinlichkeitsverteilung verschiedener Wörter vorherzusagen, die im nächsten Moment auftauchen. Einerseits kann das Sprachmodell den Grad der Übereinstimmung eines Satzes mit der Sprachgrammatik messen (z. B. messen, ob die vom Mensch-Computer-Dialogsystem automatisch generierte Antwort natürlich und flüssig ist), und es kann auch verwendet werden um neue Sätze vorherzusagen und zu generieren. Beispielsweise kann das Sprachmodell für einen Clip „Es ist 12 Uhr mittags, lass uns zusammen in ein Restaurant gehen“ die Wörter vorhersagen, die nach „Restaurant“ erscheinen könnten. Ein allgemeines Sprachmodell wird vorhersagen, dass das nächste Wort „essen“ ist. Ein leistungsfähiges Sprachmodell kann die Zeitinformationen erfassen und das Wort „essen“ vorhersagen, das zum Kontext passt.
Ob ein Sprachmodell leistungsfähig ist, hängt normalerweise hauptsächlich von zwei Punkten ab: Erstens, ob das Modell alle historischen Kontextinformationen nutzen kann. Wenn es im obigen Beispiel nicht die semantischen Langstreckeninformationen von „12 Uhr“ erfassen kann Das Sprachmodell wird das nächste Mal kaum vorhersagen können. Zweitens hängt es auch davon ab, ob der historische Kontext reich genug ist, damit das Modell lernen kann, das heißt, ob der Trainingskorpus reich genug ist. Da es sich bei dem Sprachmodell um selbstüberwachtes Lernen handelt, besteht das Optimierungsziel darin, die Sprachmodellwahrscheinlichkeit des gesehenen Textes zu maximieren, sodass jeder Text ohne Kennzeichnung als Trainingsdaten verwendet werden kann.
Aufgrund der stärkeren Leistung und der deutlich größeren Parameter von GPT-3 enthält es mehr Thementext, was offensichtlich besser ist als das GPT-2 der vorherigen Generation. Als derzeit größtes dichtes neuronales Netzwerk kann GPT-3 Webseitenbeschreibungen in entsprechende Codes umwandeln, menschliche Erzählungen nachahmen, benutzerdefinierte Gedichte erstellen, Spielskripte generieren und sogar verstorbene Philosophen nachahmen und so den wahren Sinn des Lebens vorhersagen. Und GPT-3 erfordert keine Feinabstimmung, sondern erfordert nur wenige Beispiele des Ausgabetyps (ein wenig Lernaufwand), um schwierige Grammatikprobleme zu lösen. Man kann sagen, dass GPT-3 anscheinend alle unsere Vorstellungen von Sprachexperten erfüllt hat.
Hinweis: Das Obige bezieht sich hauptsächlich auf die folgenden Artikel:
1. GPT 4 steht kurz vor der Veröffentlichung und ist mit dem menschlichen Gehirn vergleichbar. Viele große Player der Branche können nicht still sitzen! -Xu Jiecheng, Yun Zhao -Öffentliches Konto 51 CTO Technology Stack- 24.11.2022 18:08
2. Beantworten Sie Ihre Neugier auf GPT-3 in einem Artikel! Was ist GPT-3? Warum ist es so ausgezeichnet? -Zhang Jiajun Institute of Automation, Chinesische Akademie der Wissenschaften Veröffentlicht in Peking am 11.11.2020 um 17:25 Uhr
3.The Batch: 329 |. InstructGPT, ein benutzerfreundlicheres und sanfteres Sprachmodell – öffentliches Konto DeeplearningAI-2022-02-07 12:30
Was sind die Probleme mit GPT-3?
Aber GTP-3 ist nicht perfekt. Eines der Hauptprobleme, über das sich die Menschen bei der künstlichen Intelligenz am meisten Sorgen machen, besteht darin, dass Chatbots und Textgenerierungstools wahrscheinlich alle Texte im Internet wahllos und in falscher, böswilliger Absicht erlernen. oder es wird sogar eine anstößige Sprachausgabe erzeugt, die ihre nächste Anwendung vollständig beeinträchtigt.
OpenAI hat außerdem vorgeschlagen, dass in naher Zukunft ein leistungsfähigeres GPT-4 veröffentlicht wird:
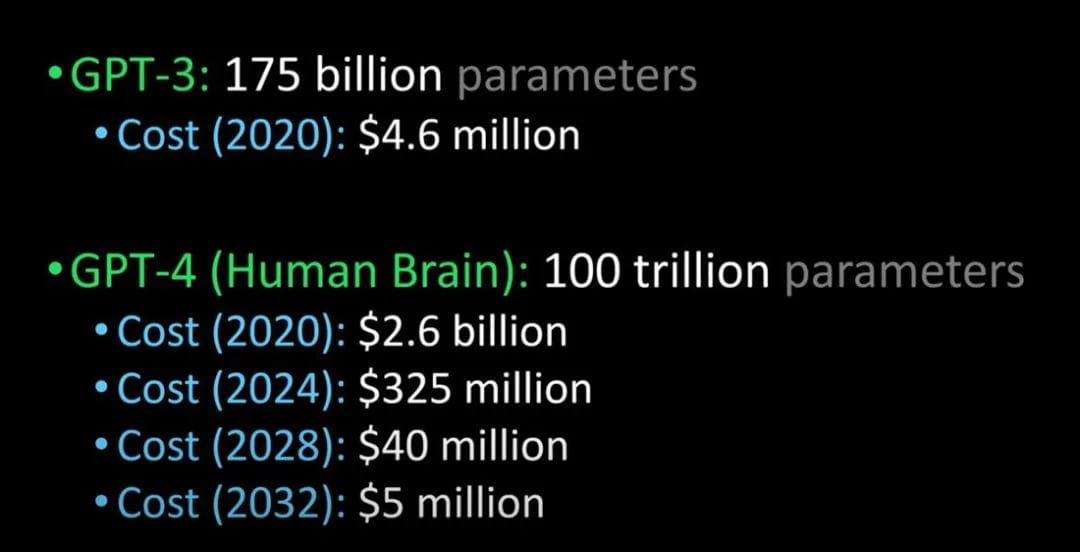
Vergleich von GPT-3 mit GPT-4 und dem menschlichen Gehirn (Bildnachweis: Lex Fridman @youtube)
Es wird gesagt, dass GPT-4 nächstes Jahr veröffentlicht wird. Es kann den Turing-Test bestehen und so weit fortgeschritten sein, dass es nicht mehr von Menschen zu unterscheiden ist. Darüber hinaus werden auch die Kosten für die Einführung von GPT-4 erheblich gesenkt.
ChatGP und InstructGPT
ChatGPT und InstructGPT
Wenn wir über Chatgpt sprechen, müssen wir über seinen „Vorgänger“ InstructGPT sprechen.
Anfang 2022 veröffentlichte OpenAI InstructGPT. Im Vergleich zu GPT-3 nutzte OpenAI Alignment-Forschung, um ein Sprachmodell zu trainieren, das realistischer und harmloser ist und InstructGPT besser folgt Version von GPT-3, die schädliche, unrealistische und voreingenommene Ausgaben minimiert.
Wie funktioniert InstructGPT?
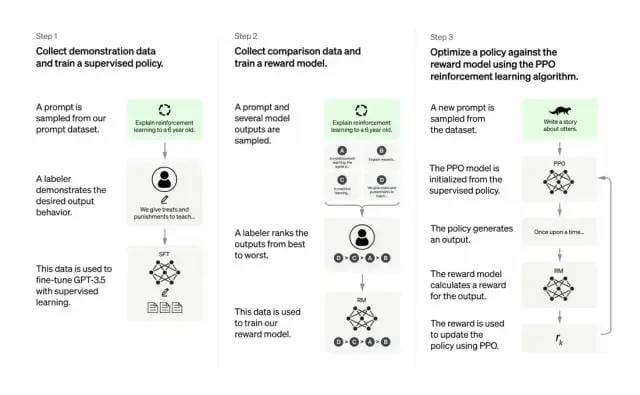
Entwickler tun dies, indem sie überwachtes Lernen und verstärkendes Lernen aus menschlichem Feedback kombinieren. Um die Ausgabequalität von GPT-3 zu verbessern. Bei dieser Art des Lernens bewerten Menschen die potenziellen Ergebnisse eines Modells. Algorithmen für verstärkendes Lernen belohnen Modelle, die Material produzieren, das dem High-Level-Output ähnelt.
Der Trainingsdatensatz beginnt mit der Erstellung von Eingabeaufforderungen, von denen einige auf Eingaben von GPT-3-Benutzern basieren, wie zum Beispiel „Erzähl mir eine Geschichte über einen Frosch“ oder „Erkläre einem 6-Jährigen in wenigen Sätzen die Mondlandung“. ”
Die Entwickler haben die Eingabeaufforderung in drei Teile unterteilt und die Antworten für jeden Teil unterschiedlich erstellt:
Menschliche Autoren reagieren auf die ersten Aufforderungen. Die Entwickler optimierten ein trainiertes GPT-3 und wandelten es in InstructGPT um, um für jede Eingabeaufforderung vorhandene Antworten zu generieren.
Der nächste Schritt besteht darin, ein Modell zu trainieren, um bessere Antworten mit höheren Belohnungen zu belohnen. Für den zweiten Satz von Eingabeaufforderungen generiert das optimierte Modell mehrere Antworten. Menschliche Bewerter bewerten jede Antwort. Anhand einer Eingabeaufforderung und zweier Antworten lernte ein Belohnungsmodell (ein weiteres vorab trainiertes GPT-3), eine höhere Belohnung für die hoch bewertete Antwort und eine niedrigere Belohnung für die niedrig bewertete Antwort zu berechnen.
Die Entwickler haben das Sprachmodell mithilfe eines dritten Satzes von Hinweisen und der Reinforcement-Learning-Methode Proximal Policy Optimization (PPO) weiter verfeinert. Wenn eine Eingabeaufforderung gegeben wird, generiert das Sprachmodell eine Antwort und das Belohnungsmodell belohnt sie entsprechend. PPO verwendet Belohnungen, um das Sprachmodell zu aktualisieren.
Referenz für diesen Absatz: The Batch: 329 |. InstructGPT, ein benutzerfreundlicheres und sanfteres Sprachmodell – öffentliches Konto DeeplearningAI – 2022-02-07 12: 30
Was ist wichtig? Der Kern besteht darin, dass künstliche Intelligenz verantwortungsvolle künstliche Intelligenz sein muss
Das Sprachmodell von OpenAI kann in den Bereichen Bildung, virtuelle Therapeuten, Schreibhilfen, Rollenspiele usw. hilfreich sein. In diesen Bereichen ist das Vorhandensein sozialer Vorurteile, Fehlinformationen und toxischer Informationen problematischer, und Systeme, die diese Mängel vermeiden können, können dies tun nützlicher sein.
Was sind die Unterschiede zwischen den Schulungsprozessen von Chatgpt und InstructGPT?
Im Allgemeinen wird Chatgpt, wie oben InstructGPT, mit RLHF (Reinforcement Learning from Human Feedback) trainiert. Der Unterschied besteht darin, wie die Daten für das Training eingerichtet (und gesammelt) werden. (Erklärung hier: Das vorherige InstructGPT-Modell gab eine Ausgabe für eine Eingabe aus und verglich diese dann mit den Trainingsdaten. Ja, es gab Belohnungen und keine Strafen; das aktuelle Chatgpt ist eine Eingabe, und das Modell liefert mehrere Ausgaben und dann Personen Diese Sortierung der Ausgabeergebnisse ermöglicht es dem Modell, diese Ergebnisse von „menschlicher“ bis „unsinnig“ einzustufen, sodass das Modell lernen kann, wie Menschen sortieren. Diese Strategie wird als überwachtes Lernen bezeichnet dieser Absatz)
Was sind die Einschränkungen von ChatGPT?
wie folgt:
a) Während der Reinforcement-Learning-Phase (RL) des Trainings gibt es keine spezifische Quelle der Wahrheit und keine Standardantworten auf Ihre Fragen.
b) Das Modell ist darauf trainiert, vorsichtiger zu sein und kann Antworten ablehnen (um Fehlalarme bei Eingabeaufforderungen zu vermeiden).
c) Überwachtes Training kann das Modell dazu verleiten/verzerren, die ideale Antwort zu kennen, anstatt dass das Modell einen zufälligen Satz von Antworten generiert und nur menschliche Prüfer die guten/bestplatzierten Antworten auswählen
Hinweis: ChatGPT reagiert empfindlich auf Formulierungen. , manchmal antwortet das Modell nicht auf eine Phrase, aber mit einer kleinen Änderung der Frage/Phrase antwortet es am Ende richtig. Trainer neigen dazu, längere Antworten zu bevorzugen, da diese möglicherweise umfassender erscheinen, was zu einer Tendenz zu längeren Antworten und zur übermäßigen Verwendung bestimmter Formulierungen im Modell führt. Wenn die anfängliche Aufforderung oder Frage nicht eindeutig ist, wird das Modell nicht angemessen um Erläuterungen bitten.
Die von ChatGPT selbst identifizierten Einschränkungen sind wie folgt.
Plausibel klingende, aber falsche Antworten:
a) Es gibt keine wirkliche Quelle der Wahrheit, um dieses Problem während der Reinforcement-Learning-Phase (RL) des Trainings zu beheben.
b) Das Trainingsmodell ist vorsichtiger und kann fälschlicherweise eine Antwort verweigern (falsch-positives Ergebnis bei problematischen Eingabeaufforderungen).
c) Überwachtes Training kann irreführend/voreingenommen sein. Das Modell neigt dazu, die ideale Antwort zu kennen, anstatt dass das Modell eine zufällige Reihe von Antworten generiert und nur menschliche Prüfer eine gute/hoch bewertete Antwort auswählen. ChatGPT reagiert empfindlich auf Formulierungen. Manchmal hat das Modell am Ende keine Antwort auf eine Phrase, aber mit einer kleinen Änderung der Frage/Phrase beantwortet es sie am Ende richtig.
Trainer bevorzugen längere Antworten, die umfassender aussehen könnten, was zu einer Tendenz zu ausführlichen Antworten und einer übermäßigen Verwendung bestimmter Ausdrücke führt. Das Modell bittet nicht angemessen um Klärung, wenn die anfängliche Aufforderung oder Frage mehrdeutig ist. Es wurde eine Sicherheitsebene implementiert, um unangemessene Anfragen über die Moderations-API abzulehnen. Wir können jedoch weiterhin mit falsch negativen und positiven Antworten rechnen.
Verweise:
1.https://medium.com/inkwater-atlas/chatgpt-the-new-frontier-of-artificial-intelligence-9 aee 81287677
2.https://pub.towardsai.net/openai-debuts-chatgpt-50 dd 611278 a 4
3.https://openai.com/blog/chatgpt/
4. GPT 4 steht kurz vor der Veröffentlichung und ist mit dem menschlichen Gehirn vergleichbar. Viele große Player der Branche können nicht still sitzen! -Xu Jiecheng, Yun Zhao -Öffentliches Konto 51 CTO Technology Stack- 24.11.2022 18:08
5. Beantworten Sie Ihre Neugier auf GPT-3 in einem Artikel! Was ist GPT-3? Warum ist es so ausgezeichnet? -Zhang Jiajun Institute of Automation, Chinesische Akademie der Wissenschaften Veröffentlicht in Peking am 11.11.2020 um 17:25 Uhr
6.The Batch: 329 |. InstructGPT, ein benutzerfreundlicheres und sanfteres Sprachmodell – öffentliches Konto DeeplearningAI-2022-02-07 12:30