Pokračujeme v předchozích dvou článcích o záležitostech, které vyžadují pozornost v programatickém obchodování:
Hard-core suché zboží - podrobnosti a myšlenky na automatizované obchodování kvantitativních obchodních systémů v reálném čase (1. Problémy a potíže)
Kvantitativní obchodní systém – podrobnosti a myšlenky automatizované nabídky firmy (2. Účel nabídky firmy)
Zde budeme pokračovat v hovořit o některých podrobných manipulačních dovednostech v návrhu kódu.
databáze
Jak bylo zmíněno v předchozích dvou článcích, stavový záznam složitější kombinace strategií je velmi důležitý a vyžaduje použití databáze.
Ve skutečnosti lze většinu programátorských podniků zařadit do kategorie CRUD, to znamená, že hlavním procesem je pouze přidávání, mazání, úprava a kontrola databáze. Obchodní kódy nejsou výjimkou. Chování středně a nízkofrekvenčního obchodování na sekundárním trhu se ve skutečnosti příliš neliší od toho, když lidé nakupují určitý poklad. Nakupují i prodávají. Těžiště automatizovaného obchodování spočívá v řízení strategického stavu.
Pokud ještě nejste obeznámeni s relačními databázemi, jako je SQL, doporučuje se, abyste se přímo naučili používat in-memory databáze NoSQL, jako je Redis. Jeho výhoda spočívá v tom, že se snadno začíná, má vynikající výkon a je ze své podstaty jednovláknový.Není potřeba uvažovat o nízkoúrovňových operacích, jako je zamykání dat při čtení a zápisu. Nevýhodou však je, že zde není primární klíč a nelze realizovat funkce jako automatické zvyšování čísla. V případě potřeby musíte napsat kód, abyste jej implementovali sami. Nikdy jsem však tuto funkci v automatizovaném obchodování tak dlouho nepoužíval.
Dalším nedůležitým problémem je, že v případě in-memory databází, pokud je množství dat, které je třeba uložit, relativně velké, musí být paměť serveru větší. Pro obecné kvantitativní obchodování však stačí 4G nebo dokonce 2G paměti a je není potřeba. Ušetřete tolik dat.
Redis je v reálném světě opravdu mocný. Pokud má vaše strategie vysokofrekvenční požadavky, může také implementovat model odběru zpráv typu pub/sub, čímž odpadá nutnost přidávat různé další moduly MQ. Pokud používáte relační databázi, jako je MySQL, jak již bylo zmíněno dříve, pokud jste ji dosud v praxi nepoužívali, budete muset investovat čas a energii do učení SQL, což je poměrně nechutný a obtížný programovací jazyk. Všimněte si, že každý je tu od toho, aby dělal kvantitativní obchodování, ne aby se učil psát kód. Zkuste použít jednodušší řešení.
Pokud navíc chcete vybudovat market centrum, s ohledem na výkon využijete i databázi Redis a budete pro pohodlí spolupracovat s frontou zpráv. Řešení je jednoduché a vhodné pro většinu scénářů. Lze použít jeden server (nebo více serverů).
návrh kódu
V zásadě je při psaní kódu nejdůležitější základní datová struktura. Návrh datové struktury není dostatečně rozumný a kód bude napsán nešikovně, protože to nevyhnutelně způsobí spojení různých modulů, což způsobí velmi obtížné úpravy. Ale abyste to správně navrhli, potřebujete nějaké obchodní zkušenosti, tedy obchodní zkušenosti. Všechny jsou o tom, jak psát kód, není moc co říct. Strategie každého jsou jiné a nelze s nimi zacházet stejně. Některé principy jsou však pravděpodobně stejné.
Například po odeslání objednávky neexistuje žádná záruka úspěchu, i když se jedná o tržní objednávku, protože může být burzou odmítnuta. Například ústředna je příliš zaneprázdněná nebo dojde k dočasné ztrátě síťových datových paketů. Poté je nejlepší navrhnout nějaké přechodné stavy podobné 2 Phase Commit. Pokud selže, zkoušejte to dál (samozřejmě ne příliš často, jinak bude zakázáno, pokud překročí limit. K tomu existuje speciální dekorátor opakování) nebo přidejte další metodu pro opravu chybového stavu.
Za normálních okolností, i když je burza mimo provoz, se během krátké doby obnoví. Pokud se neobnovíte, jedna strana bude zcela mimo provoz, buď burza, nebo váš vlastní kódový server. To je třeba sledovat a upozorňovat. Není možné, aby automatický kód pokryl vše, pokud jej nelze zpracovat automaticky, spustí se alarm, je nutný ruční zásah. Pokud se ruční zpracování nezvládne včas, dokud nebudeme pokračovat v otevírání pozic, abychom zvýšili expozici, problém nebude příliš velký, protože existují algoritmické stop-loss příkazy k pokrytí dna.
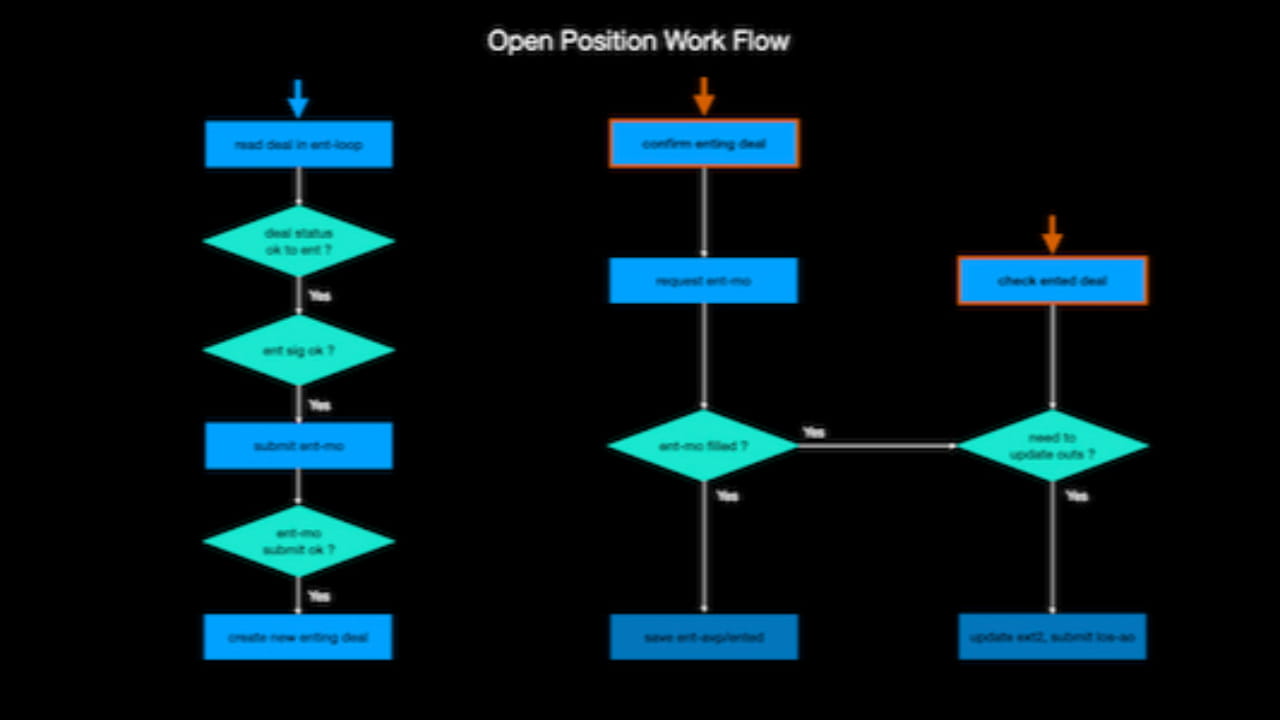
Následuje logika otevírání strategie, kterou jsem sám vyřešil:
V podstatě nakreslením podobného vývojového diagramu bude kód mnohem organizovanější a sníží se počet potenciálních chyb. Proto je nejlepší si před psaním kódu nakreslit vývojový diagram nebo si ho během psaní roztřídit, aby byla jasná logika a měli jste představu.
Logika uzavření pozice je mnohem složitější, protože existuje více podmínek pro uzavření pozice, jako jsou stop-profit, stop-loss a výstupní signály různých strategií, které uzavření pozice spustí. Zkrátka důležitost výstupu je vyšší než vstupu a skutečná nabídka je také o něco problematičtější.
Protože logika strategie každého je určitě jiná, nebudu zde zabíhat do podrobností. Hlavní věc je narovnat vaši strategickou logiku a zabránit různým možným chybám.
Ty se však zdají komplikované a jsou to jen shluky if elses (Python nemá ani příkaz switch). Pokud jsou podmínky splněny, pokračujte dalším krokem. Pokud ne, ukončete. Žádný velký problém.
kontrola času
Při provádění transakcí je načasování nepochybně velmi důležité. Zde se podělím o další své dovednosti v oblasti řízení času.
V obecném programování, pokud existují úlohy, které je třeba provádět pravidelně, obvykle se používají balíčky úloh cron, jako je apscheduler. Naplánujte si například naplánovanou úlohu, abyste zjistili, zda cena K-line potřebuje otevřít nebo zavřít pozici, jakmile nastane hodina.
Tento druh balíčku ve skutečnosti otevře nové vlákno okamžitě v nastavený čas (může být přesné na druhou úroveň) a poté provede zadanou úlohu. Problém je v tom, že pokud je doba provedení této úlohy příliš dlouhá, další úloha začne znovu. Budou problémy. I když je lze vyřešit, jsou více problematické.
Takovéto naplánované úlohy obvykle používám, když potřebuji pravidelně vydávat informace z protokolu a provádět autokorekci programu a autotest, což jsou nízkofrekvenční funkce, které lze rychle dokončit. Tyto funkce pouze čtou data v databázi a neprobíhají zde žádné operace zápisu nebo aktualizace, takže není na škodu nechat apscheduler otevřít další vlákno pro zpracování.
Logika, která vyžaduje neustálé a časté dotazování na tržní ceny nebo stav místní politiky, však není pro takový časový balíček vhodná a musí být řízena smyčkou while.
Pokud například strategie používá signály v pruhu linie K, znamená to, že se signál může objevit kdykoli a vy musíte neustále kontrolovat podkladovou cenu nebo objem obchodování, abyste zjistili, zda je třeba provést odpovídající operace. Pokud v tuto chvíli potřebujete přesnější kontrolu času, proveďte logiku série otevření pozice pouze 10 sekund před koncem hodiny k-line. Jak tedy můžete jednoduše posoudit, zda jde o posledních 10 sekund?
Vzal jsem zbytek 3600 pomocí časového razítka.
(Pokud neznáte časové razítko na počítači, tedy časové razítko, začíná od Greenwichského středního času 1970.1.1. Jedná se například o 1691240298 sekundu. Není problém s tím, aby počítač odpovídal mikrosekundová úroveň.)
Po odebrání zbytku z 3600, pokud je zbytek větší než 3590 sekund, je to posledních deset sekund. Chyba může být až na úrovni milisekund. Jak již bylo zmíněno, nejlepší je, když se hlavní transakční operace provádějí sekvenčně v jednom vlákně.Takto lze zhruba řídit dobu provádění nebo lze časové období rozmazat, což nebude žádný problém.
Tento druh ovládání vyžaduje, aby se nastavení času vašeho vlastního serveru příliš nelišilo od standardního času. Tento druh ovládání však nebude příliš přesný, může dosáhnout pouze druhé úrovně. Python však nedokáže řídit čas příliš přesně a tyto funkce spánku způsobí chyby v řádu mikrosekund.
Snižte frekvenci přístupu k API
Pokud jste přijali nezávislé tržní centrum založené na websocket pro sdílení tržních veřejných informací, jako jsou K-lines mezi různými strategiemi nebo dokonce různými obchodními kódy, pak se v tomto ohledu nemusíte obávat omezení frekvence API.
Potřebujeme ale také včas získat informace o účtu, tedy tři typy informací: fondy, pozice a příkazy. I když informace o účtu mohou také používat websocket a čekat, až je Exchange server aktivně pošle, je jednodušší přímo použít zbytek API ze tří důvodů.
Za prvé, aby se snížilo zatížení informací o účtu, které websocket posílá, výměna vyžaduje, aby burza jednou za čas znovu připojila nebo aktualizovala listenKey (Binance je 60 minut). Tento stav je samozřejmě obtížnější udržovat. Ačkoli to není velký problém, pokud hostujete API a obchodujete s více účty současně, musíte aktivovat samostatný program, abyste zajistili přesnost informací v reálném čase, a logika se stává mnohem komplikovanější.
Za druhé, některé burzy nemají websocket push pro aktualizace informací o účtu. V tomto případě není obchodní logika univerzální a je obtížnější přepínat skutečné obchodní kódy mezi různými burzami. Většina lidí samozřejmě nebude obchodovat na více burzách a s takovou situací se nesetká.
Za třetí, pokud je odkaz na websocket nefunkční nebo se setká s problémy, jako je aktualizace nebo vypršení platnosti funkce listenKey zmíněná dříve, pokud jej program včas neodhalí a náhodou v tuto chvíli dojde k transakci, pak pokud se spoléháte pouze na websocket, způsobí to srovnání Velký problém, protože zmeškané informace o aktualizaci účtu nebudou znovu odeslány. Abyste se vyhnuli možnosti takových potenciálních problémů, musíte se také spolehnout na zbytek API, abyste získali určité informace o účtu. Takže se nakonec musíte spolehnout na zbytek api, není to zbytečné?
Stručně řečeno, pro středně a nízkofrekvenční transakce je lepší přímo použít rest api k získání informací o účtu. Pro důležité zdroje dat je nejlepší řídit se SSOT (Single Source Of Truth), jinak to může způsobit potenciální zmatek.Tento koncept si můžete sami vygooglovat a je velmi užitečný při programování, které se spoléhá na zpracování dat.
Pokud pak k získávání informací o účtu používáte pouze rozhraní REST API, můžete v místní paměti kódu udržovat dočasnou tabulku informací o účtu, zejména dostupné prostředky. To může snížit časté návštěvy burzy. Klíčem je být rychlý a můžete odeslat všechny příkazy najednou Podobně jako u dávkového zadávání příkazů a následného pomalého zpracování logiky aktualizace, čím rychleji je příkaz zadán, tím menší bude skluz přirozeně.
Kromě toho, abyste zjistili, zda byl algoritmický stop-loss příkaz vyplněn, můžete použít nedávné vysoké a nízké ceny namísto přímého získání stavu čekajícího příkazu, protože k určení, zda byl příkaz vyplněn, musíte provést průzkum nepřetržitě, což je poměrně časté a způsobí to hodně neplatný přístup k API. Aktualizace ceny websocketu K-line je velmi aktuální a nezabírá limit frekvence API.
Stejně tak mohou být i některé výstupní příkazy. Pokud váš výstupní signál závisí na ceně v rámci baru, může být lepší použít nedávné vysoké a nízké ceny. Protože někdy se cena spustí a vrátí se okamžitě, pokud vaše frekvence kontrol není příliš vysoká, můžete ji minout. Abyste zajistili konzistenci ve své obchodní strategii, zaškrtněte vysoké a nízké, aby nedošlo ke ztrátě cen. Tento přístup má další výhodu v tom, že skutečná transakční cena může být příznivější než skutečná spouštěcí cena.
Nevím, jestli jsou výše uvedené dva body snadno pochopitelné. Může to vyžadovat určité zkušenosti z reálného života.
Rád bych se podělil o některé své zkušenosti s vývojem skutečného kódu a doufám, že to bude užitečné pro každého.