

Hlavní Takeaways
Binance využívá správu kapacity pro neplánované nárůsty provozu způsobené vysokou volatilitou a zajišťuje adekvátní, včasnou infrastrukturu a výpočetní zdroje pro obchodní požadavky.
Binance zátěžové testy v produkčním prostředí (spíše než ve zkušebním prostředí), abyste získali přesné srovnávací testy služeb. Tato metoda pomáhá ověřit, že naše alokace zdrojů je dostatečná pro obsluhu definované zátěže.
Infrastruktura Binance se zabývá velkým objemem provozu a údržba služby, na kterou se uživatelé mohou spolehnout, vyžaduje řádnou správu kapacity a automatické testování zátěže.

Proč Binance potřebuje specializovaný proces řízení kapacity?
Řízení kapacity je základem stability systému. Zahrnuje správnou velikost aplikací a zdrojů infrastruktury se současnými a budoucími obchodními požadavky za správnou cenu. Abychom tohoto cíle dosáhli, vytváříme nástroje a kanály pro správu kapacity, abychom se vyhnuli přetížení a pomohli podnikům poskytovat bezproblémové uživatelské prostředí.
Trhy s kryptoměnami se často vypořádávají s pravidelnějšími obdobími volatility než tradiční finanční trhy. To znamená, že systém Binance musí čas od času odolat nárůstu návštěvnosti, když uživatelé reagují na pohyby trhu. Při správném řízení kapacity udržujeme kapacitu odpovídající obecné obchodní poptávce a těmto scénářům nárůstu provozu. Tento klíčový bod je přesně to, co dělá procesy správy kapacity Binance jedinečnými a náročnými.
Podívejme se na faktory, které často brání procesu a vedou k pomalé nebo nedostupné službě. Za prvé, máme přetížení, obvykle způsobené náhlým nárůstem dopravy. Může to být například důsledkem marketingové události, oznámení push nebo dokonce útoku DDoS (distribuované odmítnutí služby).
Nárazový provoz a nedostatečná kapacita ovlivňují funkčnost systému, protože:
Služba zabírá stále více práce.
Doba odezvy se prodlouží do té míry, že během časového limitu klienta nelze odpovědět na žádný požadavek. K této degradaci obvykle dochází kvůli saturaci zdrojů (CPU, paměť, IO, síť atd.) nebo prodlouženým GC pauzám v samotné službě nebo jejích závislostech.
Výsledkem je, že služba nebude schopna rychle zpracovat požadavky.
Rozbití procesu
Nyní, když jsme diskutovali o obecném principu řízení kapacity, podívejme se, jak to Binance aplikuje na své podnikání. Zde je pohled na architekturu našeho systému řízení kapacity s některými klíčovými pracovními postupy.
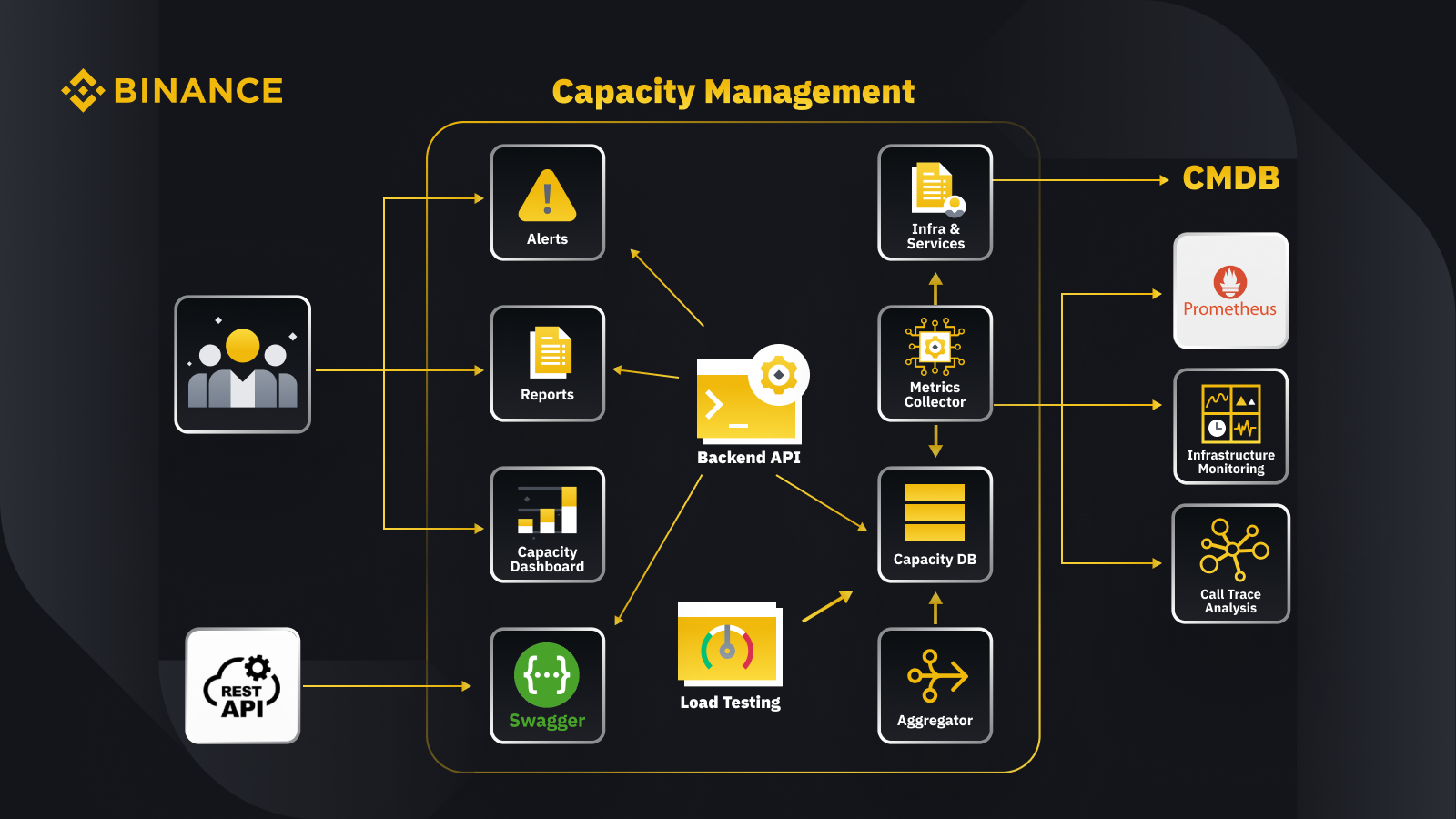
Načtením dat z databáze pro správu konfigurace (CMDB) vygenerujeme konfigurace infra a služeb. Položky v těchto konfiguracích jsou objekty správy kapacity.
Kolektor metrik načítá metriky kapacity z Prometheus pro data vrstvy obchodu a služeb, monitorování infrastruktury pro metriky vrstvy zdrojů a systém analýzy trasování volání pro informace o trasování. Kolektor metrik ukládá data do kapacitní databáze (CDB).
Systém zátěžového testování provádí zátěžové testy služeb a ukládá srovnávací data do CDB.
Agregátor získává údaje o kapacitě z CDB a agreguje je pro denní a trvale vysoké (ATH) dimenze. Po agregaci zapíše agregovaná data zpět do CDB.
Zpracováním dat z CDB poskytuje backend API rozhraní pro řídicí panel kapacity, výstrahy a sestavy, stejně jako zbývající API a související data o kapacitě pro integraci.
Zúčastněné strany získají přehled o kapacitě prostřednictvím řídicího panelu kapacity, výstrah a zpráv. Mohou také používat další související systémy, včetně monitorování dat o kapacitě služeb s odpočinkovým rozhraním API poskytovaným systémem řízení kapacity se Swaggerem.
Strategie
Naše strategie řízení kapacity a plánování se opírá o zpracování založené na špičce. Zpracování řízené špičkou je pracovní zátěž, kterou zažívají zdroje služby (webové servery, databáze atd.) během špičkového využití.
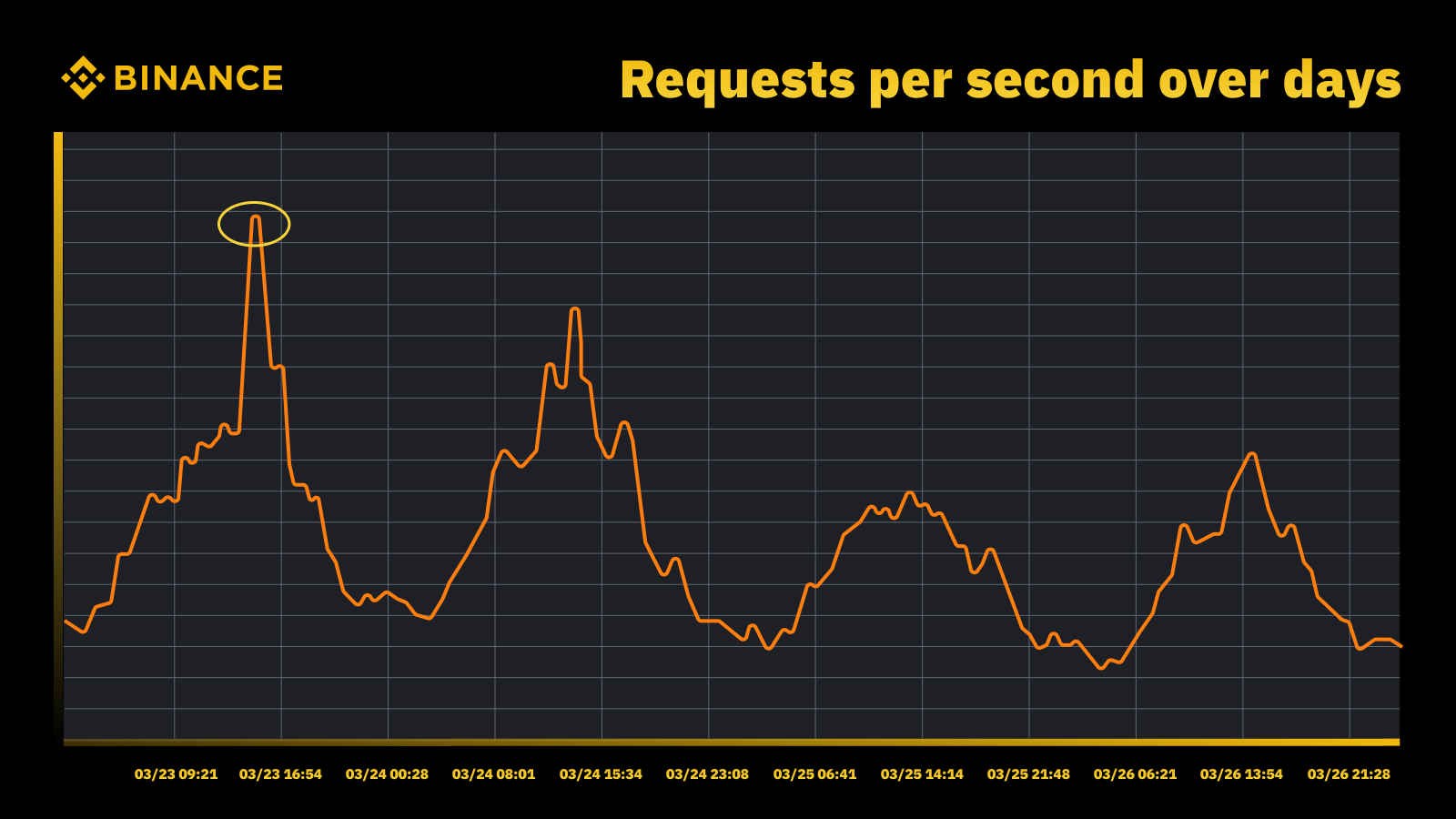
Nárůst návštěvnosti, když Fed zvýšil sazbu v březnu 2023
Analyzujeme periodické špičky a používáme je k řízení trajektorie kapacity. Jako u každého zdroje založeného na špičkách chceme zjistit, kdy nastanou špičky, a poté prozkoumat, co se během těchto cyklů skutečně děje.
Další důležitou věcí, kterou zvažujeme spolu s prevencí přetížení, je automatické škálování. Automatické škálování řeší přetížení dynamickým zvyšováním kapacity s více instancemi služby. Přebytečný provoz je pak distribuován a provoz, který zpracovává jedna instance služby (nebo závislosti), zůstává spravovatelný.
Automatické škálování má své místo, ale zaostává pouze při řešení situací přetížení. Obvykle nedokáže dostatečně rychle reagovat na náhlý nárůst provozu a funguje nejlépe pouze při postupném nárůstu.
Měření
Měření hraje klíčovou roli v práci správy kapacity Binance a sběr dat je naším prvním krokem měření. Na základě standardů Information Technology Infrastructure Library (ITIL) shromažďujeme data pro měření v dílčích procesech správy kapacity, konkrétně:
Zdroj – spotřeba zdrojů IT infrastruktury řízená využitím aplikací/služeb. Zaměřuje se na interní metriky výkonu fyzických a virtuálních výpočetních zdrojů, včetně CPU serveru, paměti, diskového úložiště, šířky pásma sítě atd.
Servis. Míry výkonu na úrovni aplikace, SLA, latence a propustnosti, které vyplývají z obchodních aktivit. Zaměřuje se na externí metriky výkonu založené na tom, jak uživatelé vnímají službu, včetně latence služby, propustnosti, špiček atd.
podnikání. Shromažďuje data, která měří obchodní aktivity zpracovávané cílovou aplikací, včetně objednávek, registrace uživatelů, plateb atd.
Řízení kapacity založené pouze na využití zdrojů infrastruktury povede k nepřesnému plánování. Je to proto, že nemusí představovat skutečné obchodní objemy a propustnost, která řídí kapacitu naší infrastruktury.
Naplánované akce poskytují skvělé místo k další diskusi. Zúčastněte se Watch Web Summit 2022 na Binance Live a sdílejte kampaň Crypto Box Rewards až o 15 000 BUSD. Kromě základních metrik vrstvy zdrojů a služeb jsme také museli vzít v úvahu obchodní objemy. Plánování kapacity jsme zde založili na obchodních metrikách, jako je odhadovaný počet diváků živého přenosu, maximální počet žádostí o kryptobox během letu, latence end-to-end a další faktory.
Po shromáždění dat naše procesy správy kapacity agregují a shrnují četné datové body shromážděné proti konkrétnímu ovladači kapacity. Souhrnná hodnota metriky je jediná hodnota, kterou lze použít při upozorňování na kapacitu, vytváření sestav a dalších funkcích souvisejících s kapacitou.
Na periodické datové body můžeme použít několik metod agregace dat, jako je součet, průměr, medián, minimum, maximum, percentil a all-time-high (ATH).

Námi zvolená metoda určuje naše výstupy z procesu řízení kapacit az nich vyplývajících rozhodnutí. Vybíráme různé metody na základě různých scénářů. Například používáme maximální metodu pro kritické služby a související datové body. Pro zaznamenání nejvyšší návštěvnosti používáme metodu ATH.
Pro různé případy použití používáme různé typy granularity pro agregaci dat. Ve většině případů používáme buď minutu, hodinu, den nebo ATH.
S minutovou granularitou měříme pracovní vytížení služby pro včasné upozornění na přetížení.
Hodinová agregovaná data používáme k vytváření denních dat a agregujeme hodinová data k zaznamenání denního maxima.
Obvykle používáme denní data pro zprávy o kapacitě a využíváme data ATH pro modelování a plánování kapacity.
Jednou ze základních metrik správy kapacity je srovnávání služeb. To nám pomáhá přesně měřit výkon a kapacitu služeb. Srovnávací test služby získáváme pomocí zátěžového testování a podrobněji se tomu budeme věnovat později.
Řízení kapacity na základě priority
Zatím jsme viděli, jak shromažďujeme metriky kapacity a agregujeme data v různých typech podrobnosti. Další kritickou oblastí, kterou je třeba prodiskutovat, je priorita, která je užitečná v kontextu zpráv o výstrahách a kapacitě. Po seřazení IT aktiv je upřednostněno omezené využití infrastruktury a výpočetní zdroje a jako první jsou přiděleny kritické služby a činnosti.
Existuje několik způsobů, jak definovat kritičnost služeb a požadavků. Užitečnou referencí je Google. V knize SRE. Definují úrovně kritičnosti jako CRITICAL_PLUS, CRITICAL, SHEDDABLE_PLUS atd. Podobně definujeme více úrovní priority, jako je P0, P1, P2 a tak dále.
Úrovně priority definujeme takto:
P0: U nejkritičtějších služeb a požadavků, u těch, jejichž selhání bude mít vážný, uživatelsky viditelný dopad.
P1: Pro ty služby a požadavky, které budou mít za následek uživatelsky viditelný dopad, ale dopad je menší než u P0. Očekává se, že služby P0 a P1 budou poskytovány s dostatečnou kapacitou.
P2: Toto je výchozí priorita pro dávkové úlohy a offline úlohy. Tyto služby a požadavky nemusí mít za následek viditelný dopad na uživatele, pokud jsou částečně nedostupné.
Co je zátěžové testování a proč jej používáme v produkčním prostředí?
Zátěžové testování je nefunkční proces testování softwaru, při kterém je výkon aplikace testován při specifické zátěži. To pomáhá určit, jak se aplikace chová, když k ní přistupuje více koncových uživatelů současně.
Ve společnosti Binance jsme vytvořili řešení, které nám umožňuje spouštět zátěžové testování v produkci. Testování zátěže se obvykle spouští ve zkušebním prostředí, ale tuto možnost jsme nemohli použít na základě našich celkových cílů správy kapacity. Zátěžové testování v produkčním prostředí nám umožnilo:
Získejte přesný benchmark našich služeb v podmínkách reálného zatížení.
Zvyšte důvěru v systém a jeho spolehlivost a výkon.
Identifikujte úzká místa v systému dříve, než k nim dojde v produkčním prostředí.
Umožňují nepřetržité monitorování produkčního prostředí.
Povolte proaktivní správu kapacity s normalizovanými testovacími cykly, které probíhají pravidelně.
Níže si můžete prohlédnout náš rámec pro testování zátěže s několika klíčovými poznatky:

Rámec mikroslužeb Binance má základní vrstvu pro podporu směrování provozu řízeného konfigurací a na základě příznaků, což je zásadní pro náš přístup TIP.
K posouzení instance, kterou testujeme, byla přijata automatická analýza kanárů (ACA). Porovnává klíčové metriky shromážděné v monitorovacím systému, takže můžeme test pozastavit/ukončit, pokud dojde k neočekávanému problému, abychom minimalizovali dopady na uživatele.
Benchmarky a metriky se shromažďují během zátěžového testování, aby se generovaly statistiky dat týkající se chování a výkonu aplikací.
Rozhraní API jsou vystavena sdílení cenných dat o výkonu v různých scénářích, například řízení kapacity a zajištění kvality. To pomáhá budovat otevřený ekosystém.
Vytváříme automatizační pracovní postupy, abychom řídili všechny kroky a kontrolní body z hlediska komplexního testování. Poskytujeme také flexibilitu integrace s jinými systémy, jako je potrubí CI/CD a provozní portál.
Náš přístup k testování ve výrobě (TIP).
Tradiční přístup k testování výkonu (provádění testů ve zkušebním prostředí se simulovaným nebo zrcadleným provozem) poskytuje určité výhody. Nasazení produkčního pracovního prostředí má však v našem kontextu více nevýhod:
Téměř zdvojnásobuje náklady na infrastrukturu a náklady na údržbu.
Je neuvěřitelně složité získat komplexní práci ve výrobě, zejména v prostředí rozsáhlých mikroslužeb napříč několika obchodními jednotkami.
Přináší další rizika pro ochranu osobních údajů a zabezpečení, protože nevyhnutelně můžeme potřebovat duplikovat data ve fázi.
Simulovaný provoz nikdy nebude replikovat to, co se skutečně děje ve výrobě. Srovnávací hodnota získaná ve zkušebním prostředí by byla nepřesná a měla by menší hodnotu
Testování v produkci, známé také jako TIP, je testovací metodologie s posunem doprava, kde se nový kód, funkce a verze testují v produkčním prostředí. Zátěžové testování ve výrobě, které jsme přijali, je velmi přínosné, protože nám pomáhá:
Analyzujte stabilitu a robustnost systému.
Objevte benchmarky a úzká místa aplikací v rámci různých úrovní provozu, specifikací serveru a parametrů aplikací.
Směrování založené na FlowFlag
Naše směrování založené na FlowFlag vložené do základního rámce mikroslužeb je základem pro umožnění TIP. To platí pro specifické případy, včetně aplikací využívajících zjišťování služeb Eureka pro distribuci provozu.
Jak je znázorněno na diagramu, webový server Binance jako vstupní body označuje určité procento provozu, jak je uvedeno v konfiguracích s hlavičkami FlowFlag, během zátěžového testu můžeme vybrat jednoho hostitele konkrétní služby a označit jej jako cílovou instanci výkonu v configs, pak budou tyto označené požadavky perf nakonec směrovány do instance perf, když se dostanou ke službě ke zpracování.
Je plně řízen konfigurací a načítání za provozu, můžeme snadno upravit procento pracovní zátěže pomocí automatizace, aniž bychom museli nasazovat nové vydání
Lze jej široce aplikovat na většinu našich služeb, protože mechanismus je součástí brány a základního balíčku
Jediný bod změny také znamená snadný návrat ke snížení rizik ve výrobě

Při transformaci našeho řešení tak, aby bylo více cloudové, také zkoumáme, jak bychom mohli vytvořit podobný přístup k podpoře jiného směrování provozu, které nabízejí poskytovatelé veřejných cloudů nebo Kubernetes.
Automatická analýza kanárků pro minimalizaci rizik dopadu na uživatele
Nasazení Canary je strategie nasazení, která má snížit riziko nasazení nové verze softwaru do výroby. Obvykle zahrnuje nasazení nové verze softwaru, nazývané kanárková verze, pro malou podskupinu uživatelů vedle stabilní běžící verze. Poté rozdělíme provoz mezi obě verze tak, aby část příchozích požadavků byla přesměrována na kanárek.
Kvalita kanárské verze se pak posuzuje tzv. kanárskou analýzou. To porovnává klíčové metriky, které popisují chování staré a nové verze. Pokud dojde k výraznému zhoršení metrik, kanár se přeruší a veškerý provoz je směrován do stabilní verze, aby se minimalizoval dopad neočekávaného chování.
Stejný koncept používáme k vytvoření našeho řešení automatického zátěžového testování. Řešení využívá platformu Kayenta pro automatizovanou analýzu kanárů (ACA) prostřednictvím Spinnakeru, která umožňuje automatizované nasazení kanárků. Náš typický průběh zátěžového testu při použití této metody vypadá takto:
Prostřednictvím pracovního postupu postupně přidáváme provozní zatížení (např. 5 %, 10 %, 25 %, 50 %) k cílovému hostiteli, jak je specifikováno, nebo dokud nedosáhne svého bodu zlomu.
Při každém zatížení se s Kayentou opakovaně po určitou dobu (např. 5 minut) spouští kanárská analýza, aby se porovnaly klíčové metriky testovaného hostitele s obdobím před zatížením jako základní hodnotou a současnou periodou po zatížení jako experimentem.
Porovnání (model canary config) se zaměřuje na kontrolu, zda cílový hostitel:
Dosahuje omezení zdrojů, např. využití CPU přesahuje 90 %.
Má výrazný nárůst metrik selhání, např. protokoly chyb, výjimky HTTP nebo odmítnutí s omezením rychlosti.
Má základní metriky aplikace stále rozumné, např. latence HTTP menší než 2 sekundy (lze přizpůsobit pro každou službu)
Pro každou analýzu nám Kayenta poskytne zprávu s uvedením výsledku a test se po selhání okamžitě ukončí.
Tato detekce selhání obvykle trvá méně než 30 sekund, což výrazně snižuje možnost ovlivnění zkušeností našich koncových uživatelů.

Povolení Data Insights
Je důležité shromáždit dostatečné informace o všech dříve popsaných procesech a provádění testů. Konečným cílem je zlepšit spolehlivost a robustnost našeho systému, což je nemožné bez přehledu dat.
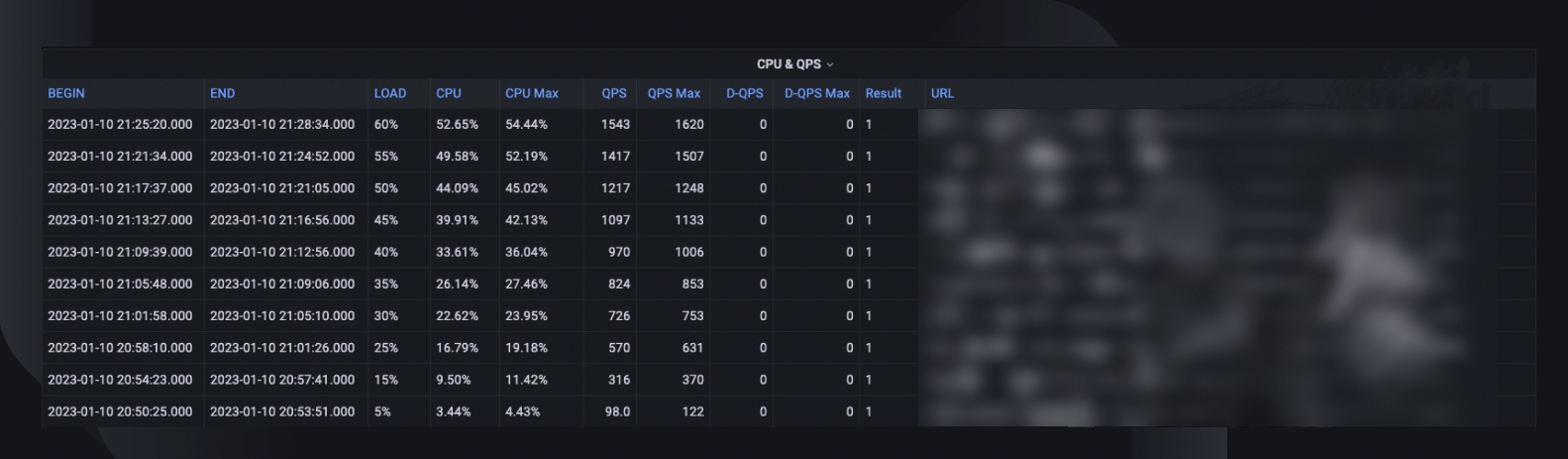
Celkový souhrn testu zachycuje maximální procento zatížení, které byl hostitel schopen zvládnout, maximální využití procesoru a QPS hostitele. Na základě toho také odhaduje počet instancí, které možná budeme muset nasadit, abychom splnili naši rezervaci kapacity, s ohledem na trvale vysokou QPS služeb.
Mezi další cenné informace pro analýzu patří verze softwaru, specifikace serveru, počet nasazení a odkaz na řídicí panel monitoru, kde se můžeme podívat zpět na to, co se stalo během testu.

Srovnávací křivka ukazuje, jak se výkon za poslední tři měsíce změnil, takže můžeme odhalit případné problémy související s konkrétní verzí aplikace.

Trendy CPU a QPS ukazují, jak využití CPU korelovalo s objemem požadavků, které musel server zpracovat. Tato metrika může pomoci odhadnout rezervy serveru pro růst příchozího provozu.
Chování latence API zachycuje, jak se mění doba odezvy za různých podmínek zatížení pro pět nejlepších rozhraní API. V případě potřeby pak můžeme systém optimalizovat na úrovni jednotlivých API.

Metriky rozložení zátěže rozhraní API nám pomáhají porozumět tomu, jak složení rozhraní API ovlivňuje výkon služby, a poskytují více informací o oblastech vylepšení.
Normalizace a produkce
Jak se náš systém neustále rozrůstá a vyvíjí, budeme neustále sledovat a zlepšovat stabilitu a spolehlivost služeb. Budeme v tom pokračovat přes:
Pravidelný a zavedený plán zátěžového testování pro kritické služby.
Automatické zátěžové testování jako součást našich CI/CD potrubí.
Zvýšená produktivita celého řešení s cílem připravit se na rozsáhlé přijetí v širší organizaci.
Omezení
Současný přístup k zátěžovému testu má určitá omezení:
Směrování založené na FlowFlag je použitelné pouze pro náš rámec mikroslužeb. Uvažujeme o rozšíření řešení na více scénářů směrování využitím společné funkce váženého směrování cloudových vyrovnávacích zátěží nebo Kubernetes Ingress.
Vzhledem k tomu, že test zakládáme na reálném provozu uživatelů v produkci, nemůžeme provádět testy funkcí proti konkrétním rozhraním API nebo případům použití. Také u služeb s velmi malým objemem by byla hodnota omezená, protože nemusíme být schopni identifikovat jejich úzké místo.
Tyto testy provádíme spíše proti jednotlivým službám, než abychom pokrývali end-to-end volací řetězce.
Test ve výrobě může někdy ovlivnit skutečné uživatele, pokud dojde k selhání. Proto musíme mít analýzu chyb a automatické vrácení zpět s plnou automatizací.
Závěrečné myšlenky
Je pro nás zásadní přemýšlet o scénářích nárůstu provozu, abychom zabránili přetížení systému a zajistili jeho provozuschopnost. Proto jsme vytvořili procesy správy kapacity a zátěžového testování popsané v tomto článku. Shrnout:
Naše správa kapacity je řízena špičkou a je zabudována do každé fáze životního cyklu služby, čímž zabraňuje přetížení činnostmi, jako je měření, nastavování priorit, upozornění a zprávy o kapacitě atd. To je nakonec to, co dělá procesy a potřeby Binance jedinečnými ve srovnání s typickou situací správy kapacity. .
Srovnávací test služeb získaný ze zátěžového testování je ústředním bodem řízení a plánování kapacity. Přesně určuje zdroje infrastruktury potřebné k podpoře současných a budoucích obchodních požadavků. To nakonec muselo být provedeno ve výrobě s jedinečným řešením vytvořeným Binance, které nám umožnilo splnit naše specifické potřeby.
Doufáme, že díky tomu všemu můžete vidět, že dobré plánování a důkladné rámce pomáhají vytvořit službu, kterou Binanciané znají a užívají si ji.
Reference
Dominic Ogbonna, A-Z z Capacity Management: Praktický průvodce pro implementaci Enterprise IT Monitoring & Capacity Planning, Kapitola 4, Kapitola 6
Luis Quesada Torres, Doug Colish, SRE Best Practices for Capacity Management
Alejandro Forero Cuervo, Sarah Chavis, kniha Google SRE, kapitola 21 – Zvládání přetížení
Další čtení
(Blog) Jak Binance Ledger posiluje váš zážitek z Binance
(Blog) Představujeme Binance Oracle VRF: Nová generace ověřitelné náhodnosti
(Blog) Binance se připojuje k Alianci FIDO v přípravě na implementaci přístupového klíče