
Původní autor: YBB Capital Zeke

Předmluva
Dne 16. února OpenAI oznámila nejnovější textově řízený model šíření videa „Sora“, který demonstroval další milník v generativní AI prostřednictvím několika vysoce kvalitních generovaných videí pokrývajících širokou škálu typů vizuálních dat. Na rozdíl od nástrojů pro generování videa AI, jako je Pika, které jsou stále ve stavu generování několika sekund videa z více snímků, Sora dosahuje škálovatelného generování videa trénováním v komprimovaném latentním prostoru videí a obrázků a jejich rozkladem na časoprostorové lokační záplaty. . Model navíc odráží i schopnost simulace fyzického světa a světa digitálního. Konečně představené 60sekundové demo nelze s nadsázkou říci, že jde o „univerzální simulátor fyzického světa“.
Co se týče konstrukční metody, Sora pokračuje technickou cestou „zdrojových dat-Transformer-Diffusion-emergence“ předchozího modelu GPT, což znamená, že jeho vyspělý vývoj vyžaduje také výpočetní výkon jako motoru, a protože množství dat potřebných pro video trénink je mnohem větší než text Množství tréninkových dat dále zvýší nároky na výpočetní výkon. O důležitosti výpočetního výkonu v éře umělé inteligence jsme však již hovořili v našem dřívějším článku (Preview of Potential Track: Decentralized Computing Power Market) a s nedávným nárůstem popularity umělé inteligence již existuje velké množství Na trhu se začaly objevovat projekty výpočetní energie a další projekty společnosti Depin (úložiště, výpočetní výkon atd.), které pasivně těžily, také zaznamenaly prudký nárůst. S jakými jiskrami se tedy kromě Depina může střetnout průnik Web3 a AI? Jaké další možnosti tato trať obsahuje? Hlavním účelem tohoto článku je aktualizovat a doplnit předchozí články a zamyslet se nad možnostmi Web3 v éře AI.
Tři hlavní směry v historii vývoje AI
Umělá inteligence (Artificial Intelligence) je nově vznikající věda a technologie určená k simulaci, rozšiřování a zlepšování lidské inteligence. Od svého zrodu v 50. a 60. letech minulého století prošla umělá inteligence více než půlstoletím vývoje a nyní se stala důležitou technologií, která podporuje změny společenského života a všech oblastí života. V tomto procesu se provázaný vývoj tří hlavních výzkumných směrů symbolismu, konekcionismu a behaviorismu stal základním kamenem dnešního rychlého rozvoje umělé inteligence.
Symbolismus
Také známý jako logicismus nebo regularismus, je to víra, že je možné simulovat lidskou inteligenci zpracováním symbolů. Tato metoda využívá symboly k reprezentaci a provozování objektů, pojmů a jejich vzájemných vztahů v problémové doméně a využívá logické uvažování k řešení problémů, zejména v expertních systémech a reprezentaci znalostí, což dosáhlo pozoruhodných výsledků. Základní myšlenkou symbolismu je, že inteligentního chování lze dosáhnout působením symbolů a logického uvažování, kde symboly představují vysoký stupeň abstrakce od skutečného světa;
Konekcionismus
Nebo nazývaná metoda neuronové sítě, jejím cílem je dosáhnout inteligence napodobováním struktury a funkce lidského mozku. Tato metoda dosahuje učení vybudováním sítě mnoha jednoduchých procesních jednotek (podobně jako neurony) a úpravou síly spojení mezi těmito jednotkami (podobně jako synapse). Konekcionismus zvláště zdůrazňuje schopnost učit se a zobecňovat z dat a je zvláště vhodný pro problémy s rozpoznáváním vzorů, klasifikací a průběžným mapováním vstupů a výstupů. Hluboké učení jako rozvoj konekcionismu přineslo průlomy v oblastech, jako je rozpoznávání obrazu, rozpoznávání řeči a zpracování přirozeného jazyka;
Behaviorismus
Behaviorismus úzce souvisí s výzkumem bionické robotiky a autonomních inteligentních systémů, přičemž zdůrazňuje, že inteligentní agenti se mohou učit prostřednictvím interakce s prostředím. Na rozdíl od prvních dvou se behaviorismus nezaměřuje na simulaci vnitřních reprezentací nebo myšlenkových procesů, ale spíše na dosažení adaptivního chování prostřednictvím cyklů vnímání a jednání. Behaviorismus věří, že inteligence se projevuje dynamickou interakcí a učením se s prostředím. Tato metoda je zvláště účinná při aplikaci na mobilní roboty a adaptivní řídicí systémy, které potřebují působit ve složitých a nepředvídatelných prostředích.
Přestože mezi těmito třemi výzkumnými směry existují zásadní rozdíly, ve skutečném výzkumu a aplikacích AI se mohou také vzájemně ovlivňovat a integrovat, aby společně podporovaly rozvoj oblasti AI.
Přehled principů AIGC
Generativní umělá inteligence (Artificial Intelligence Generated Content, AIGC), která v současné době prochází explozivním vývojem, je evolucí a aplikací konekcionismu AIGC může napodobovat lidskou kreativitu a vytvářet nový obsah. Tyto modely jsou trénovány pomocí velkých datových souborů a algoritmů hlubokého učení, aby se naučily základní struktury, vztahy a vzorce přítomné v datech. Vytvářejte neotřelý a jedinečný výstup na základě uživatelských vstupních výzev, včetně obrázků, videí, kódu, hudby, návrhů, překladů, odpovědí na otázky a textu. Současné AIGC se v zásadě skládá ze tří prvků: Deep Learning (DL), velká data a rozsáhlý výpočetní výkon.
hluboké učení
Hluboké učení je podpolí strojového učení (ML) a algoritmy hlubokého učení jsou neuronové sítě modelované podle lidského mozku. Například lidský mozek obsahuje miliony vzájemně propojených neuronů, které spolupracují na učení a zpracování informací. Stejně tak neuronové sítě pro hluboké učení (nebo umělé neuronové sítě) jsou složeny z více vrstev umělých neuronů spolupracujících uvnitř počítače. Umělé neurony jsou softwarové moduly nazývané uzly, které ke zpracování dat používají matematické výpočty. Umělé neuronové sítě jsou algoritmy hlubokého učení, které využívají tyto uzly k řešení složitých problémů.
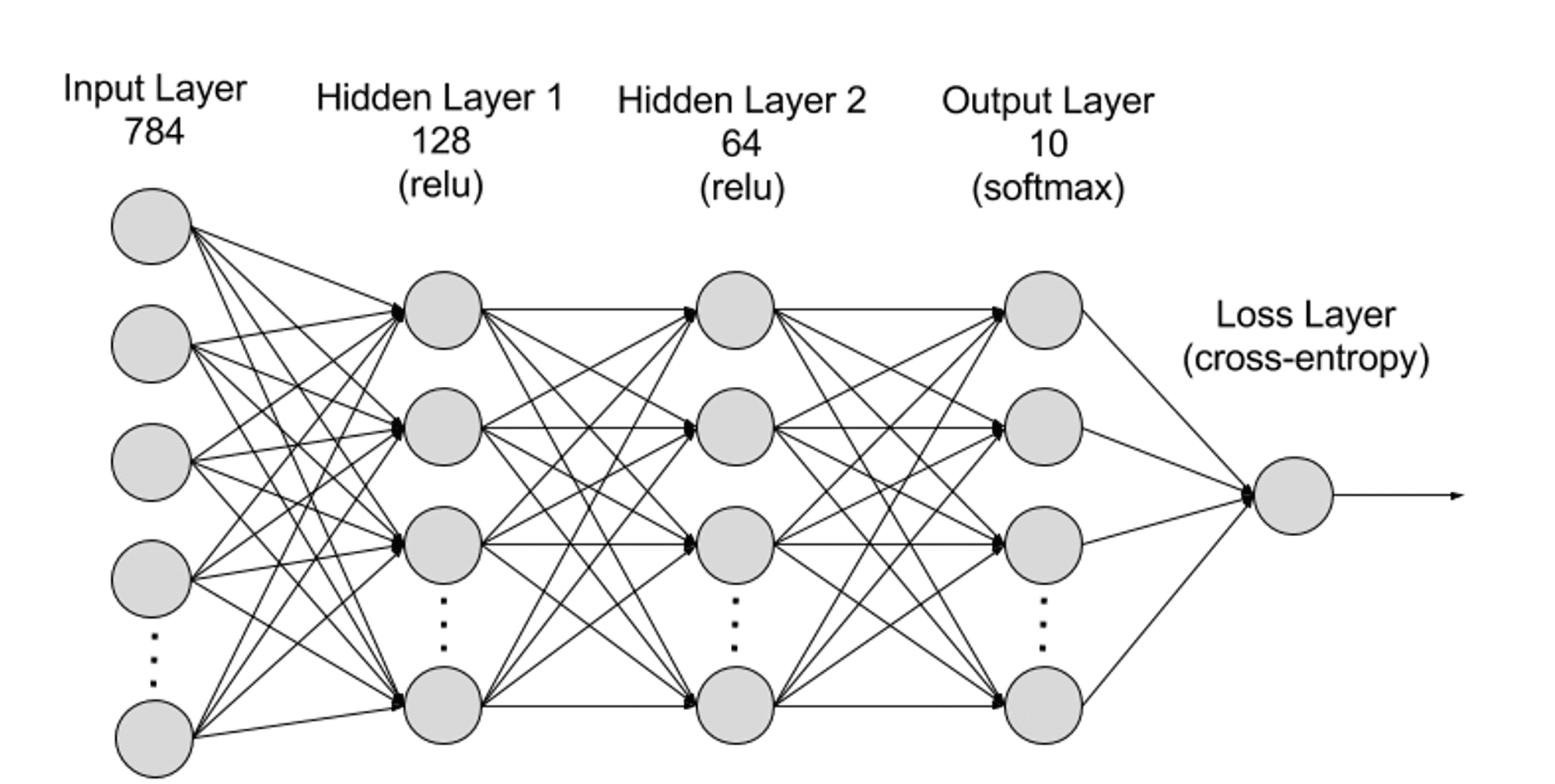
Neuronové sítě lze z hierarchické úrovně rozdělit na vstupní vrstvu, skrytou vrstvu a výstupní vrstvu, přičemž parametry jsou propojeny mezi různými vrstvami.
Vstupní vrstva: Vstupní vrstva je první vrstvou neuronové sítě a je zodpovědná za příjem externích vstupních dat. Každý neuron ve vstupní vrstvě odpovídá rysu vstupních dat. Například při zpracování obrazových dat může každý neuron odpovídat hodnotě pixelu v obrázku;
Skrytá vrstva: Vstupní vrstva zpracovává data a předává je dalším vrstvám v neuronové síti. Tyto skryté vrstvy zpracovávají informace na různých úrovních a upravují své chování, když přijímají nové informace. Sítě pro hluboké učení mají stovky skrytých vrstev a lze je použít k analýze problémů z mnoha různých perspektiv. Pokud například dostanete obrázek neznámého zvířete, které musíte klasifikovat, můžete jej porovnat se zvířaty, která již znáte. O jaké zvíře se jedná, poznáte například podle tvaru uší, počtu nohou a velikosti zorniček. Skryté vrstvy v hlubokých neuronových sítích fungují stejně. Pokud se algoritmus hlubokého učení pokouší klasifikovat obrázek zvířete, každá z jeho skrytých vrstev zpracuje jiný rys zvířete a pokusí se jej zařadit přesně;
Výstupní vrstva: Výstupní vrstva je poslední vrstvou neuronové sítě a je zodpovědná za generování výstupu sítě. Každý neuron ve výstupní vrstvě představuje možnou výstupní kategorii nebo hodnotu. Například v klasifikačním problému může každý neuron výstupní vrstvy odpovídat kategorii, zatímco v regresním problému může mít výstupní vrstva pouze jeden neuron, jehož hodnota představuje výsledek predikce;
Parametry: V neuronových sítích jsou spojení mezi různými vrstvami reprezentována parametry vah a zkreslení, které jsou během tréninkového procesu optimalizovány, aby umožnily síti přesně identifikovat vzory v datech a provádět předpovědi. Zvýšení parametrů může zlepšit kapacitu modelu neuronové sítě, to znamená schopnost modelu učit se a reprezentovat složité vzory v datech. Ale odpovídajícím způsobem zvýšení parametrů zvýší nároky na výpočetní výkon.
velká data
Aby byly efektivně trénovány, neuronové sítě obvykle vyžadují velké množství různorodých a vysoce kvalitních dat z více zdrojů. Je to základ pro trénování a ověřování modelů strojového učení. Analýzou velkých dat se modely strojového učení mohou naučit vzorce a vztahy v datech a vytvářet předpovědi nebo klasifikace.
Velký výpočetní výkon
Vícevrstvá komplexní struktura neuronové sítě, velké množství parametrů, požadavky na zpracování velkých dat a iterativní trénovací metody (ve fázi trénování je nutné model opakovaně iterovat a během trénovacího procesu dopředné šíření a zpět šíření je vyžadováno pro každý výpočet vrstvy, včetně výpočtu aktivační funkce, výpočtu ztrátové funkce, výpočtu gradientu a aktualizace hmotnosti), požadavky na vysoce přesné výpočty, možnosti paralelního výpočtu, optimalizační a regularizační techniky a procesy vyhodnocování a ověřování modelu společně vedou k jeho požadavek na vysoký výpočetní výkon.

Sora
Jako nejnovější model umělé inteligence videa vydaný OpenAI představuje Sora obrovský pokrok ve schopnosti umělé inteligence zpracovávat a chápat různá vizuální data. Pomocí sítě pro kompresi videa a technologie prostorově-časových záplat je Sora schopna převést masivní vizuální data zachycená různými zařízeními z celého světa do jednotné reprezentace, čímž dosáhne efektivního zpracování a pochopení složitého vizuálního obsahu. Na základě textově podmíněného modelu Diffusion může Sora generovat vysoce shodná videa nebo obrázky na základě textových výzev, které vykazují extrémně vysokou kreativitu a přizpůsobivost.
Přestože Sora udělala průlom v generování videa a simulaci interakcí v reálném světě, stále čelí určitým omezením, včetně přesnosti simulace fyzického světa, konzistence dlouhého generování videa, porozumění složitým textovým instrukcím a efektivity školení a generování. A Sora v podstatě dosahuje násilné estetiky prostřednictvím staré technologické cesty „Big Data-Transformer-Diffusion-Emergence“ prostřednictvím monopolního výpočetního výkonu OpenAI a výhody prvního tahu .
Přestože Sora nemá s blockchainem mnoho společného, osobně si myslím, že v příštím roce nebo dvou. Vzhledem k tomu, že vliv Sory přinutí další vysoce kvalitní nástroje pro generování umělé inteligence, aby se rychle objevily a vyvíjely, a bude vyzařovat do mnoha tratí, jako je GameFi, sociální sítě, platformy pro tvorbu a Depin v rámci Web3, je nutné mít obecné povědomí o Sora, jak bude AI v budoucnu efektivně kombinována s Web3, může být klíčovým bodem, o kterém musíme přemýšlet.
Čtyři hlavní cesty AI x Web3
Jak bylo uvedeno výše, můžeme vědět, že základním základem potřebným pro generativní umělou inteligenci jsou ve skutečnosti pouze tři body: algoritmus, data a výpočetní výkon způsob výroby. Největší role blockchainu je dvojí: rekonstrukce produkčních vztahů a decentralizace. Osobně si proto myslím, že kolizemi těchto dvou lze vygenerovat čtyři cesty:
Decentralizovaný výpočetní výkon
Vzhledem k tomu, že související články byly napsány v minulosti, hlavním účelem tohoto odstavce je aktualizovat aktuální stav dráhy výpočetního výkonu. Pokud jde o AI, výpočetní výkon je vždy nevyhnutelným faktorem. Požadavky AI na výpočetní výkon jsou tak velké, že to bylo po narození Sory nepředstavitelné. Nedávno, během Světového ekonomického fóra 2024 ve švýcarském Davosu, generální ředitel OpenAI Sam Altman bez obalu prohlásil, že výpočetní výkon a energie jsou v této fázi největšími okovy a jejich význam se v budoucnu bude dokonce rovnat měně. února oznámil Sam Altman na Twitteru mimořádně úžasný plán, jak získat 7 bilionů USD (což odpovídá 40 % čínského národního HDP v roce 2023), aby přepsal současný model globálního polovodičového průmyslu Vytvořte impérium čipů. Při psaní článků týkajících se výpočetní síly se moje představivost stále omezovala na národní blokády a obří monopoly. V dnešní době je opravdu šílené, aby jedna společnost chtěla ovládat globální polovodičový průmysl.
Proto je význam decentralizovaného výpočetního výkonu samozřejmý Charakteristiky blockchainu skutečně mohou vyřešit současný problém extrémního monopolu výpočetního výkonu a drahého nákupu dedikovaných GPU. Z pohledu toho, co AI vyžaduje, lze využití výpočetního výkonu rozdělit do dvou směrů: inference a školení V současné době existuje jen několik projektů zaměřených na školení od potřeby decentralizovaných sítí po kombinaci s návrhem neuronových sítí potřeba ultrahardwaru Vysoká poptávka je předurčena jako směr s extrémně vysokým prahem a extrémně obtížně realizovatelný. Zdůvodnění je poměrně jednoduché Na jednu stranu není návrh decentralizované sítě složitý a na druhou stranu jsou nízké nároky na hardware a šířku pásma, což je v současnosti považováno za relativně mainstreamový směr.
Prostor představivosti centralizovaného trhu s výpočetní energií je obrovský a často je spojován s klíčovým slovem „bilionová úroveň“, což je také nejčastěji medializované téma v éře AI. Nicméně, soudě podle velkého množství projektů, které se v poslední době objevily, většina z nich stále spěchá na pulty, aby si získaly popularitu. Vždy držet nahoře správný prapor decentralizace, ale mlčet o neefektivitě decentralizovaných sítí. Navíc existuje vysoký stupeň homogenity v designu a velké množství projektů je velmi podobných (na jedno kliknutí L2 plus těžební design), což může nakonec vést k situaci, kdy je obtížné získat podíl na tradiční AI. dráha.
Algoritmus a modelový systém spolupráce
Algoritmy strojového učení odkazují na tyto algoritmy, které se mohou učit pravidla a vzory z dat a na jejich základě provádět předpovědi nebo rozhodnutí. Algoritmy jsou náročné na technologie, protože jejich návrh a optimalizace vyžadují hluboké odborné znalosti a technologické inovace. Algoritmy jsou jádrem trénovacích modelů umělé inteligence a definují, jak se data transformují na užitečné poznatky nebo rozhodnutí. Běžnější generativní algoritmy AI, jako je Generative Adversarial Network (GAN), Variational Autoencoder (VAE) a Transformer, jsou navrženy pro konkrétní oblast (jako je malba, rozpoznávání jazyka, překlad a generování videa) nebo jinými slovy , rodí se na základě účelu a poté je pomocí algoritmu trénován vyhrazený model umělé inteligence.
Existuje tedy tolik algoritmů a modelů, z nichž každý má své vlastní výhody. Můžeme je integrovat do modelu, který může být civilní i vojenský? Bittensor, který se v poslední době stal velmi populárním, je v tomto směru lídrem a využívá pobídky k těžbě, aby umožnily různým modelům a algoritmům AI spolupracovat a učit se od sebe navzájem, a tím vytvářet efektivnější a všestrannější modely AI. Tímto směrem se také zaměřují Commune AI (cooperace na kódu) atd. Pro současné společnosti s umělou inteligencí jsou však algoritmy a modely jejich vlastní magickou zbraní a nebudou se půjčovat libovolně.
Proto je příběh o kolaborativní ekologii AI velmi nový a zajímavý Ekosystém pro spolupráci využívá blockchain k integraci nevýhod ostrova algoritmů AI, ale zatím není známo, zda může vytvořit odpovídající hodnotu. Koneckonců, algoritmy a modely s uzavřeným zdrojovým kódem předních společností zabývajících se umělou inteligencí mají velmi silnou schopnost aktualizovat, iterovat a integrovat. Například za méně než dva roky vývoje OpenAI iterovala od raných modelů generování textu k modelům generovaným v různých oblastech Projekty jako Bittensor dosáhly velkého pokroku v modelech a algoritmech. Cílové oblasti mohou vyžadovat nové přístupy.
Decentralizovaná velká data
Z jednoduchého hlediska, používání soukromých dat pro krmení AI a označování dat jsou pokyny, které jsou velmi konzistentní s blockchainem. Musíte pouze věnovat pozornost tomu, jak zabránit nevyžádaným datům a zlovolnému jednání, a úložiště dat může také používat FIL, AR Wait for. projekt Depin ve prospěch. Z komplexního hlediska je zajímavým směrem (jeden ze směrů průzkumu Gízy) také využití blockchainových dat pro strojové učení (ML) k řešení dostupnosti blockchainových dat.
K datům blockchainu lze teoreticky přistupovat kdykoli a odrážejí stav celého blockchainu. Ale pro ty mimo blockchainový ekosystém není přístup k tomuto obrovskému množství dat snadný. Uložení blockchainu jako celku vyžaduje rozsáhlé odborné znalosti a velké množství specializovaných hardwarových zdrojů. K překonání problémů spojených s přístupem k blockchainovým datům se v tomto odvětví objevilo několik řešení. Například poskytovatelé RPC přistupují k uzlům prostřednictvím rozhraní API, zatímco indexovací služby umožňují extrakci dat prostřednictvím SQL a GraphQL, které oba hrají klíčovou roli při řešení problému. Tyto metody však mají svá omezení. Služby RPC nejsou vhodné pro scénáře použití s vysokou hustotou, které vyžadují velké množství dotazů na data a často nemohou uspokojit poptávku. Zároveň, ačkoli služba indexování poskytuje strukturovanější způsob získávání dat, složitost protokolu Web3 extrémně ztěžuje vytváření efektivních dotazů, které někdy vyžadují napsání stovek nebo dokonce tisíců řádků složitého kódu. Tato složitost je obrovskou překážkou pro praktické pracovníky v oblasti dat a pro ty, kteří detailům Web3 do hloubky nerozumí. Kumulativní účinek těchto omezení zdůrazňuje potřebu snazšího způsobu získávání a využívání blockchainových dat, které mohou podpořit širší přijetí a inovace v této oblasti.
Kombinací vysoce kvalitních blockchainových dat se ZKML (strojové učení s nulovými znalostmi, snížení zátěže strojového učení v řetězci) může být možné vytvořit datovou sadu, která vyřeší problém dostupnosti blockchainu, a umělá inteligence může výrazně snížit náklady na blockchain pro přístupnost dat, takže vývojáři, výzkumníci a nadšenci v oblasti ML budou mít postupem času přístup ke kvalitnějším, relevantním datovým sadám pro vytváření efektivních a inovativních řešení.
AI zmocnila Dapp
Od té doby, co se ChatGPT 3 stal populárním v roce 2023, se Dapp s umělou inteligencí stal velmi běžným směrem. Extrémně všestranná generativní umělá inteligence je přístupná prostřednictvím API, což zjednodušuje a inteligentně analyzuje datové platformy, obchodní roboty, blockchainové encyklopedie a další aplikace. Na druhou stranu můžete také fungovat jako chatbot (například Myshell) nebo společník AI (AI bez spánku), nebo dokonce vytvářet NPC v řetězových hrách prostřednictvím generativní AI. Protože jsou však technické bariéry velmi nízké, většina z nich je doladěna po přístupu k API a integrace s projektem sama o sobě není dokonalá, takže se o ní mluví jen zřídka.
Ale po příchodu Sora si osobně myslím, že směřování AI posilující GameFi (včetně Metaverse) a kreativní platformu bude středem dalšího kroku. Vzhledem k povaze pole Web3 zdola nahoru bude rozhodně obtížné vyrábět produkty, které by konkurovaly tradičním hrám nebo kreativním společnostem, a příchod Sora pravděpodobně toto dilema prolomí (možná za pouhé dva až tři roky). Soudě podle Sora's Demo má již potenciál konkurovat mikro-krátkým divadelním společnostem. Aktivní komunitní kultura Web3 může také dát vzniknout velkému množství zajímavých nápadů, pokud je omezením pouze představivost, průmysl zdola nahoru Budou odstraněny bariéry mezi tradičními průmyslovými odvětvími shora dolů.
Závěr
Jak se generativní nástroje umělé inteligence neustále vyvíjejí, zažijeme v budoucnu další epochální „momenty pro iPhone“. Přestože se nad kombinací AI a Web3 mnoho lidí ušklíbne, ve skutečnosti si myslím, že se současným směřováním většinou žádné problémy nejsou. Ve skutečnosti je potřeba vyřešit jen tři bolestivá místa, a to nutnost, efektivita a fit. Ačkoli je integrace těchto dvou ve fázi průzkumu, nebrání to tomu, aby se tato trať stala hlavním proudem dalšího býčího trhu.
Udržet si dostatek zvídavosti a přijetí nových věcí je pro nás nezbytností Historicky se výměna vozů za koňské povozy stala během okamžiku samozřejmostí, stejně jako v minulosti existovaly nápisy a NFT příliš mnoho předsudků jen promeškáte příležitost.