
Jak se systémy AI stávají autonomnějšími, otázka důvěry se přesouvá od modelů k datům. Už nestačí vědět, jak byl model trénován. Musíte přesně vědět, na jakých datech byl trénován, zda tato data zůstala neporušená a zda je někdo mohl změnit, aniž by si toho někdo všiml. Tady většina datových pipeline tiše selhává.
@Walrus 🦭/acc je postaven na jednoduché, ale silné myšlence: datové sady by měly být ověřitelné ve výchozím nastavení, nikoli důvěřovány na základě předpokladu.
Walrus se nesnaží tento problém vyřešit přidáním dalšího monitorování nebo řízení přístupu. Mění způsob, jakým jsou data potvrzena, odkazována a znovu používána napříč systémy, takže ověření se stává součástí samotného pracovního postupu.
Proč jsou tradiční datové soubory těžko ověřitelné
Ve většině AI pipeline dnes žijí datové soubory ve centralizovaném úložišti. Soubory jsou nahrávány, aktualizovány, přepisovány a verzovány podle konvencí spíše než záruk. I když týmy vedou dobré záznamy, ověření stále závisí na důvěře.
Důvěřujete, že:
datový soubor nebyl po zahájení trénování změněn
označení verze skutečně odráží základní data
poskytovatel úložiště tiše nenahradil ani neodstranil záznamy
Jakmile jsou modely vytrénovány, prokázání těchto předpokladů se stává obtížným. Záznamy mohou být upraveny. Soubory mohou být nahrazeny. Starší verze nemusí již existovat. Pro regulované nebo vysoce rizikové AI systémy je tato nedostatečná ověřitelnost vážnou slabinou.
Walrus začíná tím, že předpokládá, že tento model důvěry není dostatečný.
Nejdříve závazek, navždy ověřit
V jádru Walrus je myšlenka kryptografických závazků dat.
Když je datový soubor přidán do Walrus, síť se dohodne na přesné reprezentaci těchto dat v daném okamžiku. Tento závazek působí jako trvalý otisk prstu. Pokud se později změní i jen jeden bajt, závazek se již neshoduje.
Pro pracovní postupy AI to znamená, že tréninkový úkol může odkazovat na konkrétní závazek datového souboru místo na proměnlivou cestu k souboru. Kdo koliv, kdo model později zkoumá, může nezávisle ověřit, že data použita pro trénink jsou přesně ta data, která byla závazně uvedena.
Ověření již nezávisí na tom, kdo data uložil. Závisí na samotném závazku.
Dostupnost, která nezávisí na jedné straně
Ověřitelnost je bezpředmětná, pokud data mohou zmizet.
Walrus spojuje závazky s dostupností podporovanou sítí. Data jsou distribuována a koordinována tak, aby nemohla být selektivně zadržována nebo tiše odstraněna jediným aktérem. Pokud jeden účastník přestane fungovat nebo odmítne poskytovat data, ostatní je stále mohou poskytnout.
To je důležité pro datové soubory, protože částečná dostupnost může zkreslit trénink stejně jako nesprávná data. Model vytrénovaný na neúplném datovém souboru může v testování vypadat dobře, ale chovat se nepředvídatelně v produkci.
S Walrus je dostupnost vlastností systému, nikoli slib od poskytovatele.
Explicitní verzování místo tichého přepisování
Jedním z nejběžnějších způsobů, jak datové soubory ztrácejí integritu, je drift verzí. Aktualizace přepisují předchozí soubory. Označení se mění. V průběhu času si nikdo není jistý, která verze byla skutečně použita.
Walrus činí verzování explicitním.
Každá aktualizace datového souboru produkuje nový závazek. Starší verze zůstávají adresovatelné a ověřitelné. Nic není přepisováno. To vytváří jasnou linii změn dat v průběhu času.
Pro týmy AI to znamená:
můžete přesně reprodukovat trénink
můžete auditovat, jak se datové soubory vyvíjely
můžete porovnat chování modelu napříč verzemi dat
Je důležité, že to neodhaluje data veřejně. Odhaluje to existenci a identitu verzí, což je to, co ověřitelnost vyžaduje.
Ověřitelné reference napříč AI pipeline
Walrus zachází s odkazy na data jako s objekty první třídy.
Tréninkové úkoly, modely, agenti a downstream systémy mohou všechny odkazovat na stejný závazek datového souboru. Pokud model tvrdí, že byl vytrénován na konkrétním datovém souboru, toto tvrzení může být ověřeno nezávisle. Není žádná nejasnost ohledně toho, která data byla použita.
To odstraňuje celou kategorii chyb způsobených nesouladem souborů, rozbitými odkazy nebo chybami v koordinaci mimo řetězec.
Pro autonomní agenty je to zvlášť důležité. Agent, který může ověřit svůj vlastní zdroj dat, je mnohem spolehlivější než ten, který slepě důvěřuje systémům upstream.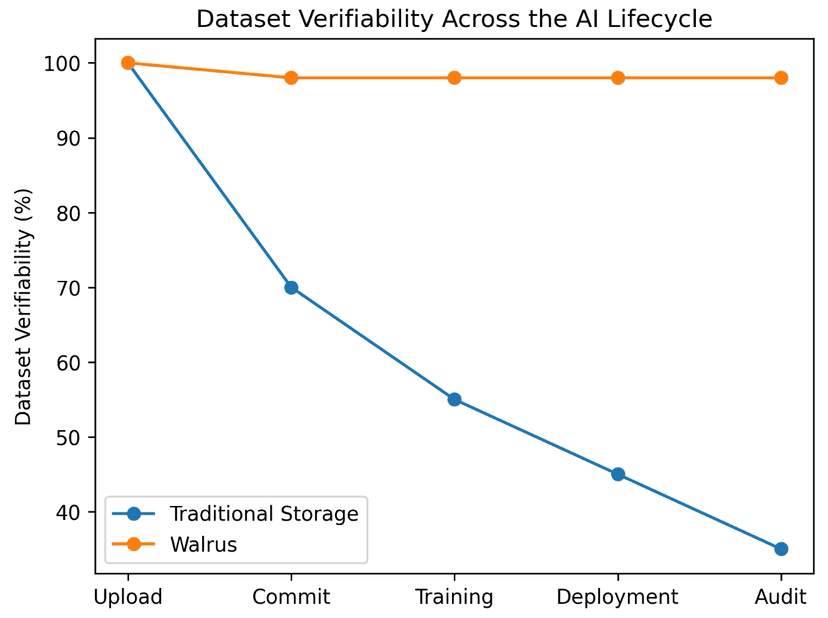
Proč je to důležitější, jak se AI stává autonomní
Jakmile se systémy AI přesouvají z pasivních nástrojů na aktivní rozhodovatele, náklady na nejistotu dat prudce rostou. Malé nekonzistence v tréninkových datech se mohou rozšířit do velkých rozdílů v chování. Když se přetrénování děje automaticky, manipulace se stává snazší a těžší k odhalení.
Walrus umožňuje datové soubory, které se mohou bránit samy.
Místo ptaní se „Důvěřujeme zdroji dat?“, mohou systémy ptát „Odpovídají tato data závaznému datovému souboru?“ Tento posun promění důvěru na ověřitelnost.
Od úložiště k důvěryhodnosti dat
Walrus se nepředstavuje jako jen další úložná vrstva. Představuje se jako infrastruktura důvěryhodnosti pro data.
Kombinováním neměnných závazků, zaručené dostupnosti, explicitního verzování a ověřitelných referencí činí Walrus datové soubory něčím, co lze prokázat jako správné dlouho poté, co byly vytvořeny.
Pro trénink AI, audity a nasazení to znamená rozdíl mezi daty, o kterých doufáte, že jsou správná, a daty, která můžete skutečně podpořit.
Můj názor
Diskuze o bezpečnosti AI se často zaměřují na modely, sladění nebo limity výpočtů. Ale modely jsou downstream od dat. Pokud nelze data ověřit, nic postavené na nich není plně důvěryhodné.
Walrus řeší tento problém u jeho kořenů. Tím, že dělá datové soubory ověřitelnými, trvalými a odolnými vůči tichým změnám, poskytuje systémům AI něco, co dosud většinou postrádaly: solidní, prokazatelný základ.
Jak systémy AI přebírají více odpovědnosti, tento základ bude mít větší význam než jakékoli jednotlivé vylepšení modelu.