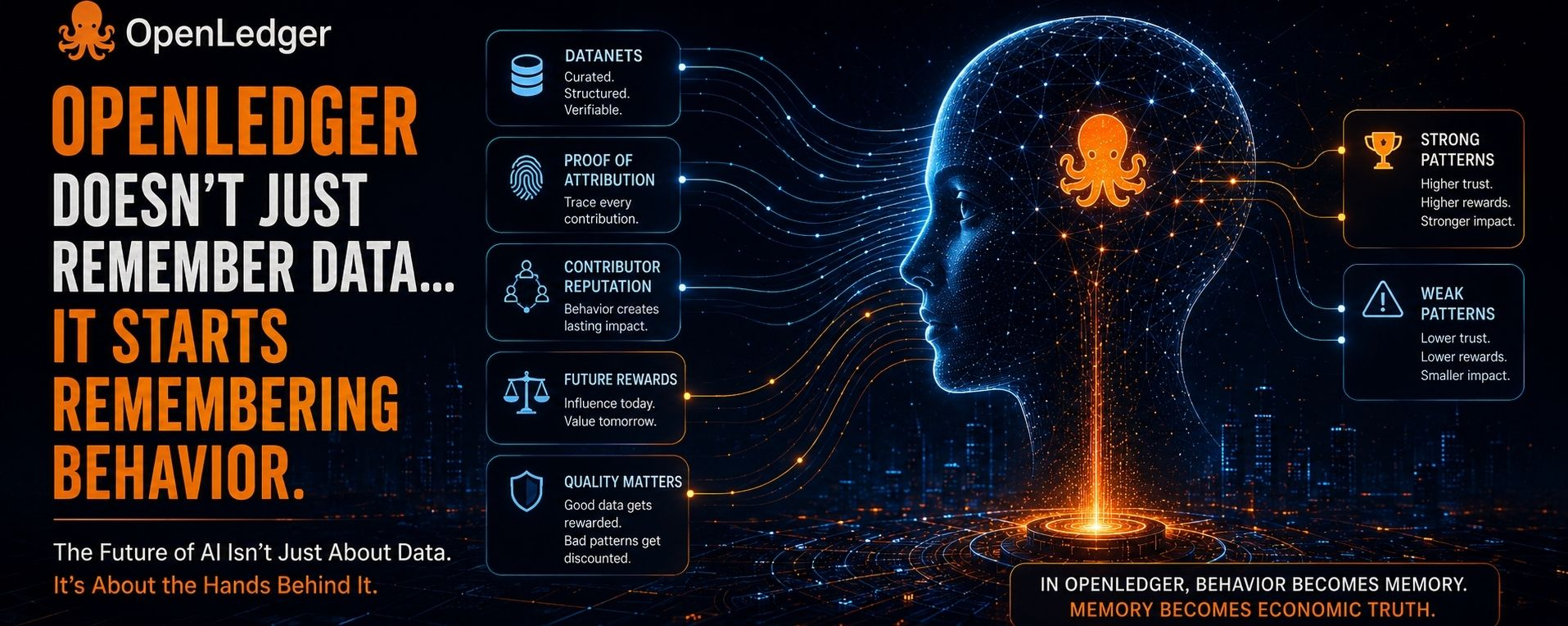

Most people still talk about AI data as if the only thing that matters is volume.
More datasets.
More scraping.
More inputs.
More tokens pushed into the machine.
Inside most AI systems, the assumption is simple: if enough data enters the pipeline, intelligence eventually emerges from scale alone.
But the deeper I look at @OpenLedger the less I think the real shift is about data quantity at all.
The real shift is memory.
Not model memory.
Not context windows.
Not embeddings.
Behavioral memory.
Because once Proof of Attribution starts tracing how outputs were actually formed which datasets influenced inference, which contributors shaped results, which inputs consistently produced signal instead of noise the system stops remembering only the data.
It starts remembering the contributors behind it.
And that changes everything.
Most AI systems today operate like giant extraction engines. They absorb information endlessly, flatten every source into the same blur, monetize outputs, and forget almost everything about where value actually came from.
good contributions disappear beside weak ones.
Noise gets mixed with signal.
Manipulation gets buried under scale.
Eventually a smarter model appears, but nobody can clearly explain which contributors genuinely improved it and which ones slowly degraded it over time.
That fog is normal in traditional AI.
#OpenLedger feels designed to remove it.
Once Datanets create structured, traceable data environments, once attribution links outputs back to their origin, and once contributor influence can be measured across live inference, contribution stops being a one-time action.
It becomes a behavioral pattern.
And behavioral patterns leave economic fingerprints.
That’s the part people underestimate.
Most conversations around decentralized AI still reduce everything to a simple formula:
> contribute data → receive rewards
But OpenLedger’s architecture pushes far beyond that.
Because if contributor reputation affects future weighting, if repeated low-signal inputs reduce influence, if attribution continuously measures whether your contributions strengthened or weakened inference quality, then the system is not merely rewarding data.
It is building long-term memory around contributor behavior itself.
That changes the psychological structure of participation.
The question stops being:
> “Did this dataset help?”
And slowly becomes:
> “What kind of contributor have you consistently been to the network?”
That is a much heavier question.
Because one weak contribution is noise.
Repeated weak contribution becomes evidence.
And once evidence accumulates inside an attribution economy, reputation stops being social.
It becomes operational.
Inside OpenLedger, contribution starts looking less like uploading assets into a pool and more like exposing your judgment to a system that continuously evaluates outcomes over time.
The implications are bigger than most people realize.
Imagine someone repeatedly contributing to a specialized Datanet.
At first, everything may appear acceptable on the surface:
properly formatted inputs
structured tagging
no obvious corruption
enough volume to look useful
But later, once models train through ModelFactory, once OpenLoRA routes specialized inference paths, and once real users begin interacting with outputs, the system can observe something deeper:
maybe the contributor’s data repeatedly appears in low-signal inference paths
maybe it introduces redundancy instead of precision
maybe it weakens specialization quality
maybe it consistently contributes statistical weight without improving outcomes
Traditional AI systems would likely absorb that silently and move on.
OpenLedger doesn’t seem designed for silent absorption.
Because Proof of Attribution creates persistent visibility across inference paths. And once attribution exists, repeated outcomes become measurable over time.
That means future rewards no longer depend only on participation.
They depend on historical contribution quality.
This is where the economic layer becomes genuinely interesting.
The network does not need dramatic punishment systems.
It does not need public shaming.
It does not even need governance theater.
It only needs memory.
If contributor reputation continuously influences future weighting, then the system naturally begins separating:
contributors who consistently strengthen inference quality
contributors who repeatedly weaken it
Quietly.
Mathematically.
Continuously.
And that quietness is what makes it powerful.
Because the network never needs to announce exclusion.
Lower trust scores, weaker attribution weight, reduced future reward share, narrower routing preference all of these can emerge naturally from repeated settlement behavior.
Not as emotion.
As economics.
That may be the most important philosophical shift inside OpenLedger.
For years, AI systems have focused almost entirely on teaching machines to remember users, prompts, tokens and context.
But OpenLedger introduces something different:
the possibility of AI infrastructure remembering contributor reliability itself.
Not emotionally.
Economically.
That distinction matters.
Because once economic memory exists, decentralization changes shape too.
People often describe decentralized AI as open participation where anyone can contribute and earn.
That is partially true.
But if attribution systems continuously evaluate contributor quality across time, decentralization also becomes accountability infrastructure.
The network is not only asking who participated.
It is asking:
> who repeatedly improved intelligence, and who repeatedly degraded it?
And once a system starts asking that question consistently, contributor behavior becomes part of the architecture itself.
Datanets are no longer just storage surfaces.
They become testing grounds for contributor quality.
Proof of Attribution is no longer just a payout mechanism.
It becomes a memory layer.
OpenLoRA is no longer just efficient specialization.
It becomes a faster exposure mechanism where weak contributions reveal themselves through narrower inference paths.
Even governance starts changing shape under this logic.
Because standards no longer need to be declared first through ideology or voting.
The network can slowly develop standards through repeated settlement itself.
Repeated attribution becomes evidence.
Repeated evidence becomes weighting.
Repeated weighting becomes economic gravity.
Over time, the system learns who consistently strengthens intelligence and who consistently introduces degradation into the network.
That may ultimately become one of OpenLedger’s most important breakthroughs.
Not simply paying for data.
But creating a framework where contributor behavior itself becomes economically visible across time.
And maybe that is exactly what AI has been missing.
Right now, most AI ecosystems operate like appetite machines:
consume everything, forget the source, monetize the output.
OpenLedger attempts something far more difficult:
trace provenance, measure influence, and connect intelligence back to the contributors who shaped it.
But once you build that kind of system honestly, an unavoidable truth appears:
if useful contribution deserves memory, harmful contribution probably does too.
You cannot meaningfully preserve one without preserving the other.
That is where OpenLedger stops feeling like a simple AI + blockchain narrative.
And starts feeling like something more serious:
a behavioral accounting system for intelligence production itself.
Because eventually the network is no longer only measuring whether you contributed.
It starts measuring what your pattern of contribution says about you over time.
And once that happens, contribution stops being temporary.
The data may enter once.
But the behavior behind it can remain embedded inside the economic memory of the network long after the upload is forgotten.

