

Srovnávání rámců obvodů pomocí SHA-256

Rádi bychom poděkovali týmům z Polygon Zero, projektu gnark v Consensys, Pado Labs a Delphinus Lab za jejich cennou recenzi a zpětnou vazbu na tento blog.
Pantheon nulových znalostí důkaz
Během posledních několika měsíců jsme věnovali značné množství času a úsilí vývoji špičkové infrastruktury, která využívá stručné důkazy zk-SNARK. V rámci našeho vývojového úsilí jsme testovali a používali širokou škálu vývojových rámců Zero-Knowledge-Proof (ZKP). I když byla tato cesta přínosná, uvědomujeme si, že množství dostupných rámců ZKP často vytváří výzvu pro nové vývojáře, kteří se snaží najít nejvhodnější řešení pro jejich konkrétní případy použití a požadavky na výkon. S ohledem na tuto bolest se domníváme, že je zapotřebí komunitní hodnotící platforma, která je schopna poskytovat komplexní výsledky srovnávacích testů, a která výrazně pomůže při vývoji těchto nových aplikací.
Abychom tuto potřebu naplnili, spouštíme Pantheon of Zero Knowledge Proof jako veřejně prospěšnou komunitní iniciativu. Prvním krokem bude povzbudit komunitu, aby sdílela reprodukovatelné výsledky benchmarkingu z různých rámců ZKP. Naším konečným cílem je kolektivně a ve spolupráci vytvořit a udržovat všeobecně uznávané testovací testovací prostředí, které pokrývá nízkoúrovňové vývojové rámce obvodů, zkVM a kompilátory na vysoké úrovni a dokonce i poskytovatele hardwarové akcelerace. Doufáme, že tato iniciativa urychlí přijetí ZKP tím, že usnadní informované rozhodování a zároveň podpoří evoluci a iteraci samotných rámců ZKP tím, že poskytne soubor běžně referovatelných výsledků benchmarkingu. Jsme odhodláni investovat do této iniciativy a zveme všechny podobně smýšlející členy komunity, aby se k nám připojili a společně přispěli k tomuto úsilí!
První krok: Srovnávání rámců obvodů pomocí SHA-256
V tomto blogovém příspěvku uděláme první krok k vybudování Pantheonu ZKP tím, že poskytneme reprodukovatelnou sadu výsledků benchmarků pomocí SHA-256 v celé řadě rámců pro vývoj obvodů na nízké úrovni. I když uznáváme, že jsou možné další granularity a primitiva benchmarkingu, vybrali jsme SHA-256 kvůli jeho použitelnosti v široké škále případů použití ZKP, včetně blockchainových systémů, digitálních podpisů, zkDID a dalších. Za zmínku také stojí, že SHA-256 využíváme také v našem vlastním systému, takže je to docela pohodlné i pro nás! 😂
Náš benchmark hodnotí výkon SHA-256 na různých vývojových rámcích obvodů zk-SNARK a zk-STARK. Prostřednictvím tohoto srovnání se snažíme poskytnout vývojářům pohled na efektivitu a praktičnost každého rámce. Naším cílem je, aby tato zjištění umožnila vývojářům činit informovaná rozhodnutí při výběru nejvhodnějšího frameworku pro jejich projekty.
Dokazovací systémy
V posledních letech jsme pozorovali šíření systémů prokazování nulových znalostí. I když je náročné držet krok se všemi vzrušujícími pokroky v tomto prostoru, pečlivě jsme vybrali následující ověřovací systémy na základě jejich vyspělosti a osvojení vývojáři. Naším cílem je představit reprezentativní vzorek různých kombinací frontend/backend.
Circom + snarkjs / rapidsnark: Circom je populární DSL pro psaní obvodů a generování omezení R1CS, zatímco snarkjs je schopen generovat Groth16 nebo Plonk důkaz pro Circom. Rapidsnark je také tester pro Circom, který generuje důkaz Groth16 a je obvykle mnohem rychlejší než snarkjs díky použití rozšíření ADX, které co nejvíce paralelizuje generování důkazů.
gnark: gnark je komplexní rámec Golang od Consensys, který podporuje Groth16, Plonk a mnoho dalších pokročilých funkcí.
Arkworks: Arkworks je komplexní Rust framework pro zk-SNARKs.
Halo2 (KZG): Halo2 je implementace Zcash zk-SNARK s Plonk. Je vybaven vysoce flexibilní aritmetizací Plonkish, která podporuje mnoho užitečných primitiv, jako jsou vlastní brány a vyhledávací tabulky. Používáme Halo2 fork s podporou KZG od Ethereum Foundation a Scroll.
Plonky2: Plonky2 je implementace SNARK založená na technikách z PLONK a FRI z Polygon Zero. Plonky2 používá malé pole Zlatovláska a podporuje účinnou rekurzi. V našem benchmarkingu jsme se zaměřili na 100bitové předpokládané zabezpečení a použili jsme parametry, které poskytly nejlepší dobu prokazování úlohy benchmarku. Konkrétně jsme použili 28 dotazů Merkle, zvětšovací faktor 8 a 16bitovou výzvu broušení proof-of-work. Navíc jsme nastavili num_of_wires = 60 a num_routed_wires = 60.
Starky: Starky je vysoce výkonný framework STARK od Polygon Zero. V našem benchmarkingu jsme se zaměřili na 100bitové předpokládané zabezpečení a použili jsme parametry, které přinesly nejlepší čas prokazování. Konkrétně jsme použili 90 dotazů Merkle, zvětšovací faktor 2 a 10bitový proof-of-work grinding challenge.
Níže uvedená tabulka shrnuje výše uvedené rámce s příslušnými konfiguracemi použitými v našem benchmarkingu. Tento seznam není v žádném případě vyčerpávající a mnoho nejmodernějších frameworků/technik (např. Nova, GKR, Hyperplonk) je ponecháno pro budoucí práci.
Mějte prosím na paměti, že tyto výsledky benchmarků jsou pouze pro rámce pro vývoj obvodů. V budoucnu plánujeme publikovat samostatný blog porovnávající různé zkVM (např. Scroll, Polygon zkEVM, Consensys zkEVM, zkSync, Risc Zero, zkWasm) a rámce IR kompilátorů (např. Noir, zkLLVM).
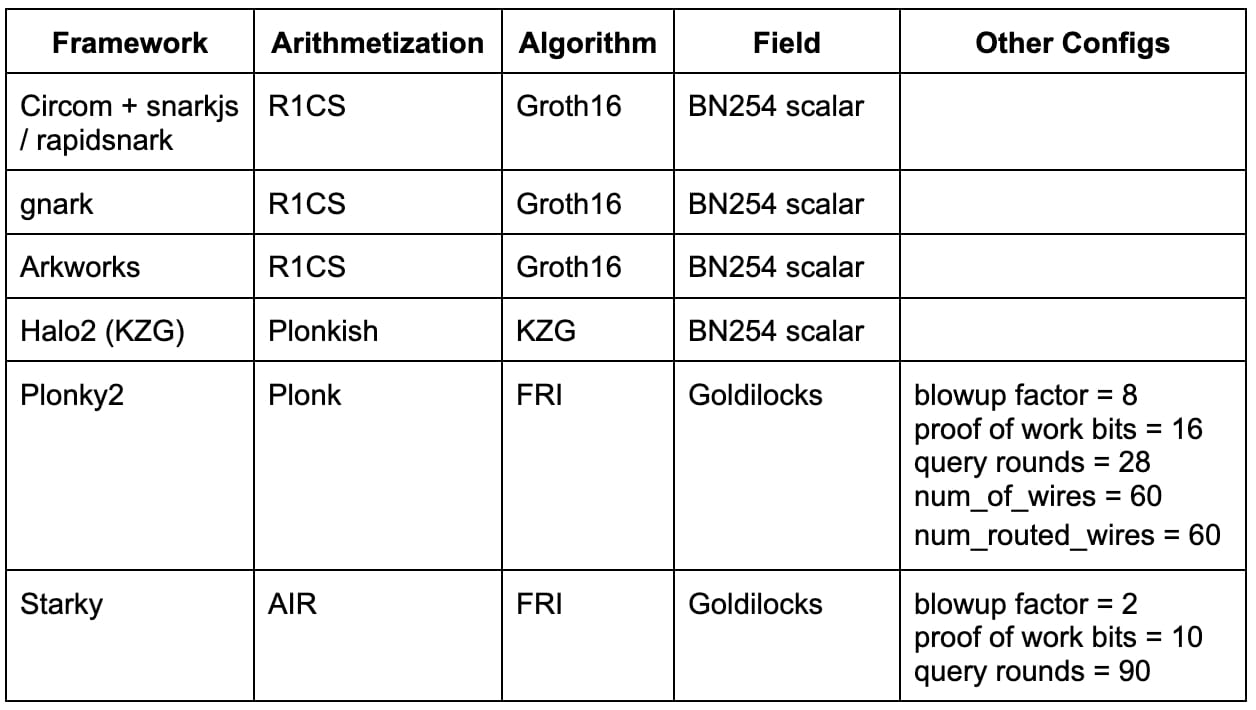
Metodika benchmarku
Abychom porovnali tyto různé dokazovací systémy, vypočítali jsme hash SHA-256 pro N bajtů dat, kde jsme experimentovali s N = 64, 128, ..., 64 kB (s jednou výjimkou byl Starky, kde obvod opakuje SHA-256 výpočet pro pevný 64bajtový vstup, ale zachovává stejný celkový počet bloků zpráv). Srovnávací kód a implementace obvodu SHA-256 lze nalézt v tomto úložišti.
Dále jsme provedli benchmarking každého systému pomocí následujících výkonnostních metrik:
Doba generování důkazů (včetně doby generování svědků)
Špičkové využití paměti během generování nátisku
Průměrné procento využití CPU během generování důkazů. (Tato metrika odráží stupeň paralelizace během generování důkazů)
Vezměte prosím na vědomí, že vytváříme určité „mávnutím ruky“ předpoklady týkající se velikosti nátisku a nákladů na ověření nátisku, protože tyto aspekty lze zmírnit složením s Groth16/KZG před přechodem na řetěz.
Stroje
Provedli jsme náš benchmarking na dvou různých strojích:
Linux Server: 20 jader @ 2,3 GHz, 384 GB paměti
Macbook M1 Pro: 10 jader @ 3,2 GHz, 16 GB paměti
Server Linux byl použit k simulaci scénáře s mnoha jádry CPU a bohatou pamětí. Zatímco Macbook M1 Pro, který se běžně používá pro výzkum a vývoj, má výkonnější CPU s méně jádry.
Povolili jsme multithreading tam, kde je to volitelné, ale v tomto benchmarku jsme nepoužili akceleraci GPU. Plánujeme zahrnout srovnávání GPU jako součást naší budoucí práce.
Srovnávací výsledky
Počet omezení
Než přejdeme k podrobným výsledkům benchmarkingu, je užitečné nejprve porozumět složitosti SHA-256 tím, že se podíváme na počet omezení v každém dokazovacím systému. Je důležité si uvědomit, že počty omezení v různých aritmetizačních schématech nejsou přímo srovnatelné.
Níže uvedené výsledky odpovídají velikosti předobrazu 64 kB. I když se výsledky mohou lišit s jinými velikostmi předobrazu, lze je zhruba lineárně škálovat.
Circom, gnark a Arkworks používají stejnou aritmetizaci R1CS a počet omezení R1CS pro výpočet 64KB SHA-256 je zhruba 30 až 45 milionů. Rozdíl mezi Circom, gnark a Arkworks je pravděpodobně způsoben rozdíly v implementaci.
Halo2 a Plonky2 používají Plonkishovu aritmetizaci, kde se počet řádků pohybuje od 2^22 do 2^23. Implementace SHA-256 v Halo2 je mnohem efektivnější než v Plonky2 díky použití vyhledávacích tabulek.
Starky používá aritmetizaci AIR, kde tabulky trasování provedení vyžadují 2^16 přechodových kroků.
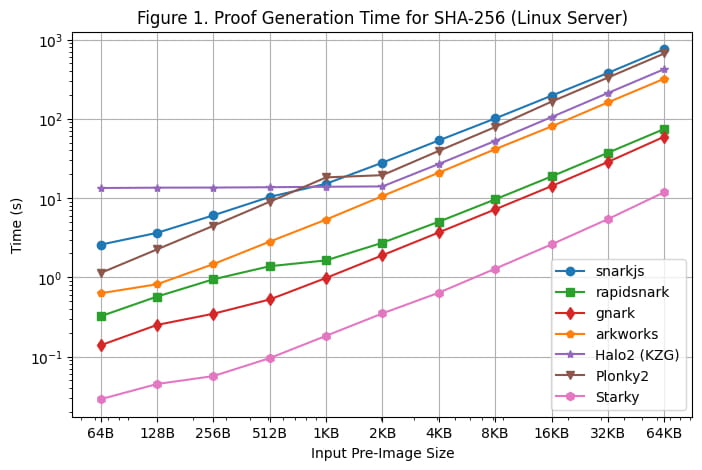
Doba generování důkazu
[Obrázek 1] ilustruje dobu generování nátisku každého rámce pro SHA-256 v různých velikostech pre-image pomocí linuxového serveru. Jsme schopni učinit následující pozorování:
Pro SHA-256 generují rámce Groth16 (rapidsnark, gnark a Arkworks) nátisky rychleji než rámce Plonk (Halo2 a Plonky2). Je to proto, že SHA-256 sestává hlavně z bitových operací, kde jsou hodnoty drátu buď 0 nebo 1. Pro Groth16 to snižuje většinu výpočtů od skalárního násobení eliptické křivky na sčítání bodů eliptické křivky. Hodnoty drátu se však přímo nepoužívají ve výpočtech Plonku, takže speciální struktura drátu v SHA-256 nesnižuje množství výpočtů potřebných v rámcích Plonk.
Mezi všemi frameworky Groth16 jsou gnark a rapidsnark 5x-10x rychlejší než Arkworks a snarkjs. Je to díky jejich vynikající schopnosti využívat více jader k paralelizaci generování důkazů. Gnark je o 25 % rychlejší než rapidsnark.
U rámců Plonk je Plonky2 o 50 % pomalejší než Halo2 pro SHA-256 při použití větší velikosti předobrazu >= 4 kB. Je to proto, že implementace Halo2 silně využívá vyhledávací tabulku k urychlení bitových operací, což má za následek 2x méně řádků než Plonky2. Pokud však porovnáme Plonky2 a Halo2 se stejným počtem řádků (např. SHA-256 přes 2 kB v Halo2 vs. SHA-256 přes 4 kB v Plonky2), je Plonky2 o 50 % rychlejší než Halo2. Pokud implementujeme SHA-256 s vyhledávací tabulkou v Plonky2, měli bychom očekávat, že Plonky2 bude rychlejší než Halo2, i když velikost důkazu Plonky2 je větší.
Na druhou stranu, když je velikost vstupního pre-image malá (<=512 bajtů), Halo2 je pomalejší než Plonky2 (a další frameworky) kvůli fixním nákladům na nastavení vyhledávací tabulky, které zohledňují většinu omezení. S narůstajícím předobrazem se však výkon Halo2 stává konkurenceschopnějším, s dobou generování důkazu, která zůstává konstantní pro velikosti předběžného obrazu do 2 kB a poté se měří téměř lineárně, jak lze pozorovat v grafu.
Jak se očekávalo, Starkyho doba generování nátisku je výrazně kratší (5x-50x) než u jakéhokoli rámce SNARK, ale je to za cenu mnohem větší velikosti nátisku.
Další poznámka je, že i když je velikost obvodu lineární ve velikosti předobrazu, generování důkazu roste superlineárně pro SNARK kvůli O(nlogn) FFT (ačkoli to není na grafu zřejmé kvůli log měřítko).
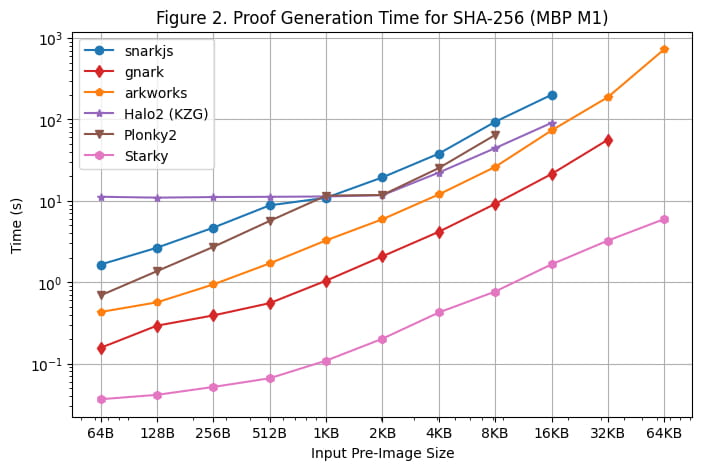
Provedli jsme také benchmark doby generování důkazů na Macbooku M1 Pro, jak je znázorněno na [obrázku 2]. Je však důležité poznamenat, že rapidsnark nebyl do tohoto benchmarku zahrnut kvůli nedostatku podpory pro architekturu arm64. Abychom mohli použít snarkjs na arm64, museli jsme vygenerovat svědka pomocí webassembly, což je pomalejší než generování svědků v C++ používané na linuxovém serveru.
Při spouštění benchmarku na Macbooku M1 Pro bylo zaznamenáno několik dalších pozorování:
S výjimkou Starky se všechny frameworky SNARK setkaly s chybami z nedostatku paměti (OOM) nebo s použitím odkládací paměti (což mělo za následek pomalejší prokazování), když se velikost předobrazu zvětšila. Konkrétně frameworky Groth16 (snarkjs, gnark, Arkworks) začaly používat odkládací paměť, když velikost předobrazu byla větší nebo rovna 8 kB, a gnark narazil na OOM pro 64 kB. Halo2 narazil na limit paměti, když velikost předobrazu byla větší nebo rovna 32 kB. Plonky2 začne používat odkládací paměť, když velikost předobrazu byla větší nebo rovna 8 kB.
Frameworky založené na FRI (Starky a Plonky2) byly na Macbooku M1 Pro asi o 60 % rychlejší než na Linux Serveru, zatímco jiné frameworky zaznamenaly podobné doby testování jako na Linux Serveru. Výsledkem bylo, že Plonky2 dosáhl téměř stejného zkušebního času jako Halo2 na Macbooku M1 Pro, i když vyhledávací tabulka nebyla v Plonky2 použita. Hlavním důvodem je to, že Macbook M1 Pro má výkonnější CPU, ale s méně jádry. FRI provádí hlavně hašovací operace, které jsou citlivější na taktovací cykly CPU, ale nejsou tak paralelizovatelné jako KZG/Groth16.
Špičkové využití paměti
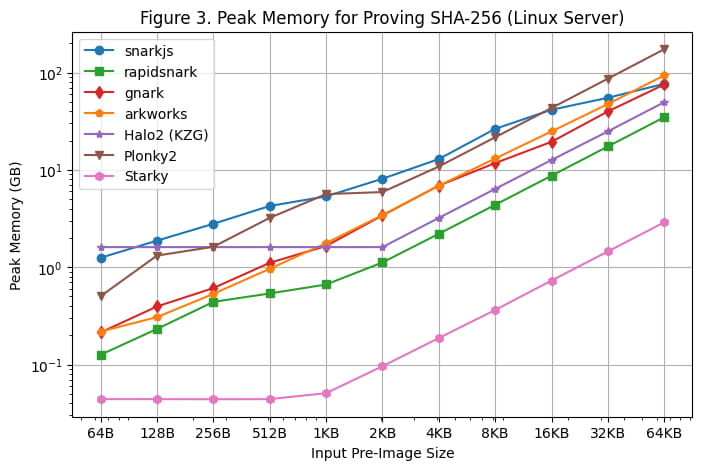
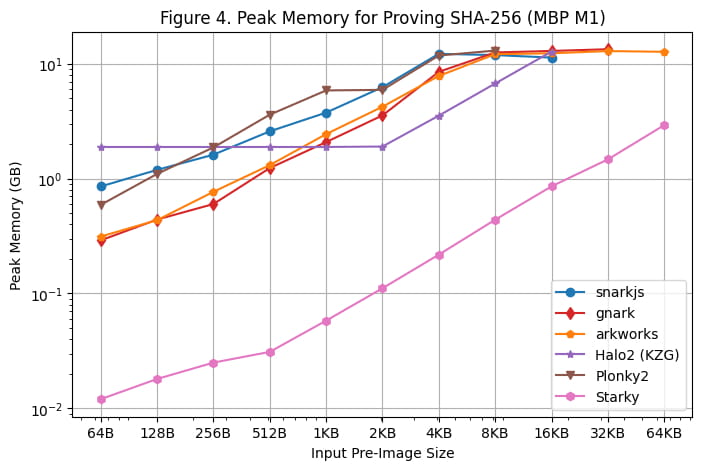
Špičkové využití paměti během generování nátisku na serveru Linux a Macbook M1 Pro je znázorněno na [Obrázek 3] a [Obrázek 4]. Na základě těchto výsledků benchmarkingu lze učinit následující pozorování:
Ze všech rámců SNARK je rapidsnark nejúčinnější z hlediska paměti. Také vidíme, že Halo2 využívá více paměti, když je velikost předobrazu menší kvůli fixním nákladům na nastavení vyhledávací tabulky, ale celkově spotřebovává méně paměti, když je velikost předobrazu větší.
Starky je více než 10x paměťově efektivnější než frameworky SNARK. To je částečně způsobeno tím, že používá méně řádků.
Je třeba poznamenat, že maximální využití paměti zůstává na Macbooku M1 Pro relativně ploché, protože velikost předobrazu se zvětšuje kvůli využití odkládací paměti.
Využití CPU
Stupeň paralelizace pro každý testovací systém jsme vyhodnotili měřením průměrného využití CPU během generování proof pro SHA-256 přes 4KB pre-image vstup. Tabulka níže ukazuje průměrné využití CPU (a průměrné využití na jádro v závorkách ) na serveru Linux (s 20 jádry) i na Macbooku M1 Pro (s 10 jádry).
Klíčové postřehy jsou následující:
Gnark a rapidsnark vykazují nejvyšší využití CPU na linuxovém serveru, což ukazuje na jejich schopnost efektivně využívat více jader a paralelizovat generování důkazů. Halo2 také demonstruje dobrý výkon paralelizace.
Většina frameworků vykazuje 2x využití CPU na linuxovém serveru ve srovnání s Macbookem Pro M1, výjimkou je snarkjs.
Navzdory počátečním očekáváním, že rámce založené na FRI (Plonky2 a Starky) mohou mít problémy s efektivním využíváním více jader, nefungují v našich benchmarcích hůře než některé rámce Groth16/KZG. Zbývá zjistit, zda budou nějaké rozdíly ve využití CPU na stroji s ještě více jádry (např. 100 jader).

Závěr a budoucí práce
Tento blogový příspěvek představuje komplexní srovnání výkonu SHA-256 na různých vývojových rámcích zk-SNARK a zk-STARK. Prostřednictvím výsledků benchmarku jsme získali přehled o efektivitě a praktičnosti každého rámce pro vývojáře, kteří požadují stručné důkazy pro operace SHA-256. Bylo zjištěno, že rámce Groth16 (např. rapidsnark, gnark) jsou rychlejší při generování důkazů než rámce Plonk (např. Halo2, Plonky2). Vyhledávací tabulka v Plonkishově aritmetizaci výrazně snižuje omezení a čas ověřování pro SHA-256 při použití větší velikosti předobrazu. Navíc gnark a rapidsnark demonstrují vynikající schopnost využívat více jader pro paralelizaci. Starky na druhé straně vykazuje mnohem kratší dobu generování nátisku, ale za cenu mnohem větší velikosti nátisku. Pokud jde o efektivitu paměti, rapidsnark a Starky překonávají ostatní frameworky.
Jako první kroky k vybudování Pantheonu ZKP uznáváme, že tento výsledek benchmarku zdaleka není konečným komplexním testovacím prostředím, o které usilujeme, aby jednou byl. Vítáme a jsme otevřeni zpětné vazbě a kritice a zveme všechny, aby přispěli k této iniciativě, jejímž cílem je zjednodušit a zpřístupnit ZKP pro vývojáře. Jsme také ochotni poskytnout granty pro jednotlivé přispěvatele na pokrytí nákladů na výpočetní zdroje pro rozsáhlý benchmarking. Společně můžeme zlepšit efektivitu a praktičnost ZKP ve prospěch širší komunity.