
3D Avatar Diffusion je algoritmus strojového učení, který dokáže pořídit jeden 2D snímek lidské tváře a vytvořit trojrozměrného (3D) avatara. Avatara pak lze použít k vytvoření virtuální reality (VR) nebo rozšířené reality (AR) nebo jednoduše poskytnout realistický 3D pohled na osobu pro hraní her nebo jiné účely.
Difúzní model byl vyvinut týmem výzkumníků z Microsoft Research a je popsán v článku publikovaném v časopise arXiv.

3D Avatar Diffusion je založen na typu algoritmu strojového učení zvaného difúzní model. Difúzní modely jsou generativní modely, což znamená, že mohou generovat nová data, která jsou podobná trénovacím datům. Difúzní modely byly dříve používány ke generování 3D obrázků z 2D obrázků, ale ADM je první difúzní model, který dokáže generovat realistický 3D avatar z jediného 2D obrázku.
K trénování modelu výzkumníci použili datový soubor více než 200 000 3D modelů obličeje. Soubor dat zahrnoval širokou škálu tváří s různými odstíny pleti, účesy a rysy obličeje. ADM se pak mohl naučit vztah mezi 2D obrázkem a 3D modelem tváře a vytvořit realistický 3D avatar z jediného 2D obrázku.
Model lze také použít ke generování avatara z fotografie, která byla pořízena z jiného úhlu
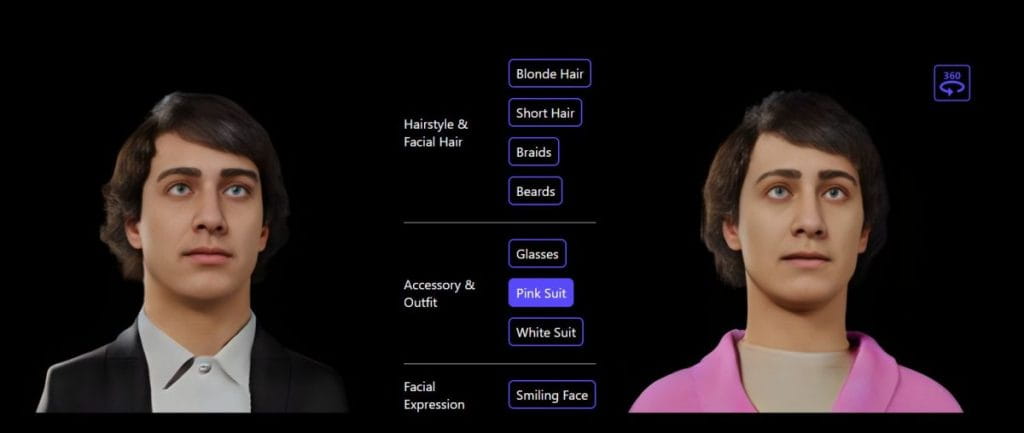 Pro personalizovaného 3D avatara nabízí model Rodin textem řízenou manipulaci. Úprava přirozeného jazyka je intuitivní způsob, jak změnit mnoho různých funkcí 3D avatarů.
Pro personalizovaného 3D avatara nabízí model Rodin textem řízenou manipulaci. Úprava přirozeného jazyka je intuitivní způsob, jak změnit mnoho různých funkcí 3D avatarů.
Tato studie navrhuje 3D generativní model, který automaticky vytváří 3D digitální avatary, které jsou reprezentovány jako pole neuronového záření pomocí difúzních modelů. Vzhledem k neúměrným požadavkům na paměť a zpracování spojené s 3D je vytváření bohatých funkcí nezbytných pro vysoce kvalitní avatary obrovským problémem. Vývojáři navrhují, aby tento problém řešila zavedení difúzní sítě (Rodin).
 Pokud jde o pohlaví, věk, rasu, výraz, obličejové doplňky atd., model vykazuje mimořádnou generační rozmanitost.
Pokud jde o pohlaví, věk, rasu, výraz, obličejové doplňky atd., model vykazuje mimořádnou generační rozmanitost.
Tato síť rozvine četné 2D mapy prvků pole neuronového záření do jediné roviny 2D prvků, kde pak model provádí 3D-aware difúzi. Model Rodin využívá 3D-aware konvoluci, která se stará o promítané prvky v rovině 2D prvků podle jejich původního vztahu ve 3D, aby poskytla tolik potřebnou výpočetní efektivitu při zachování integrity difúze ve 3D.
Přečtěte si více o AI:
VALL-E: Nový model převodu textu na řeč s nulovým snímkem od společnosti Microsoft dokáže duplikovat hlas každého během tří sekund
Microsoft VALL-E se zdá být nejnebezpečnějším podvodným softwarem vůbec
Artist vytváří skript proti krádeži na ochranu umění, používá stejný vodoznak jako generátory AI
Microsoft a Google v roce 2023: letošní primární zúčtování mezi AI titány
The post Microsoft vydal difúzní model, který dokáže sestavit 3D avatara z jediné fotografie člověka appeared first on Metaverse Post.