
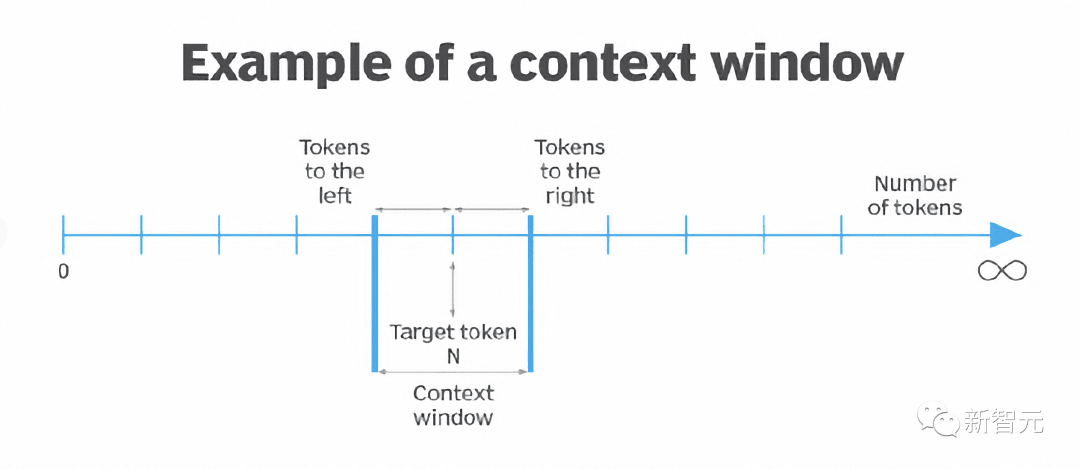
Zdroj dotisku článku: Model Evolution
Zdroj článku: Xinzhiyuan

Zdroj obrázku: Generated by Unbounded AI
Nejdelší kontextové okno na světě je tady! Společnost Baichuan Intelligent dnes vydala velký model Baichuan2-192K s délkou kontextového okna až 192 kB (350 000 čínských znaků), což je 4,4krát více než Claude 2 a 14krát více než GPT-4!
Nový benchmark v oblasti dlouhých kontextových oken je tady!
Dnes Baichuan Intelligent oficiálně vydal světově nejdelší velký model s délkou kontextového okna - Baichuan2-192K.
Co se od minulosti liší, je délka kontextového okna tohoto modelu až 192 kB, což odpovídá asi 350 000 čínským znakům.
Abychom byli konkrétnější, čínské znaky, které Baichuan2-192K dokáže zpracovat, jsou 14krát větší než u GPT-4 (32K kontext, měřeno asi 25 000 slov) a 4,4krát víc než Claude 2 (100K kontext, měřeno asi 80 000 slov, které umí). přečíst knihu na jeden zátah (třítělová).

Záznam kontextového okna vedený Claudem byl dnes obnoven.
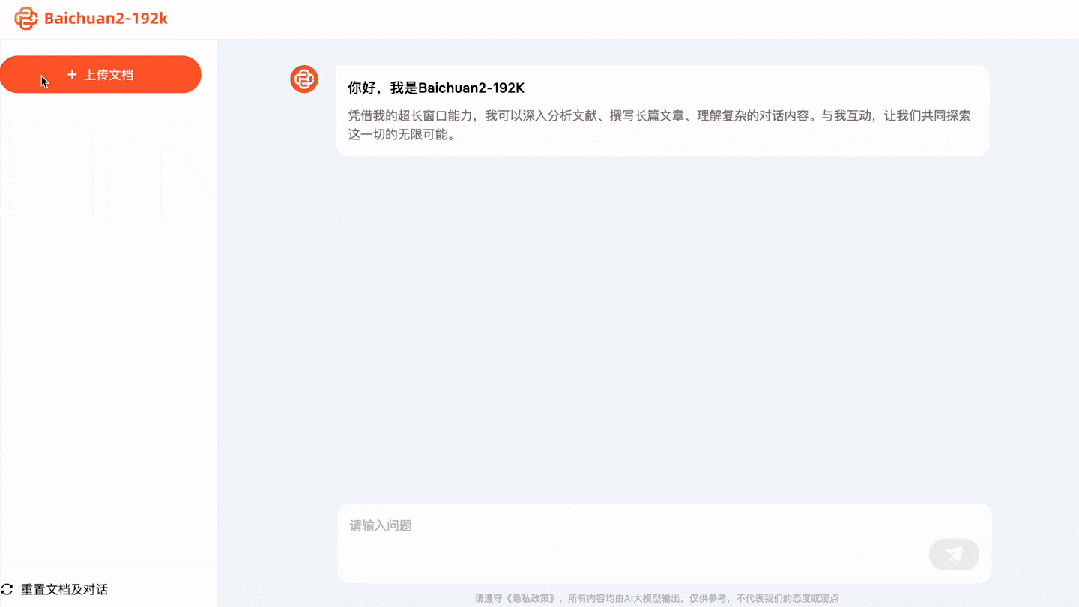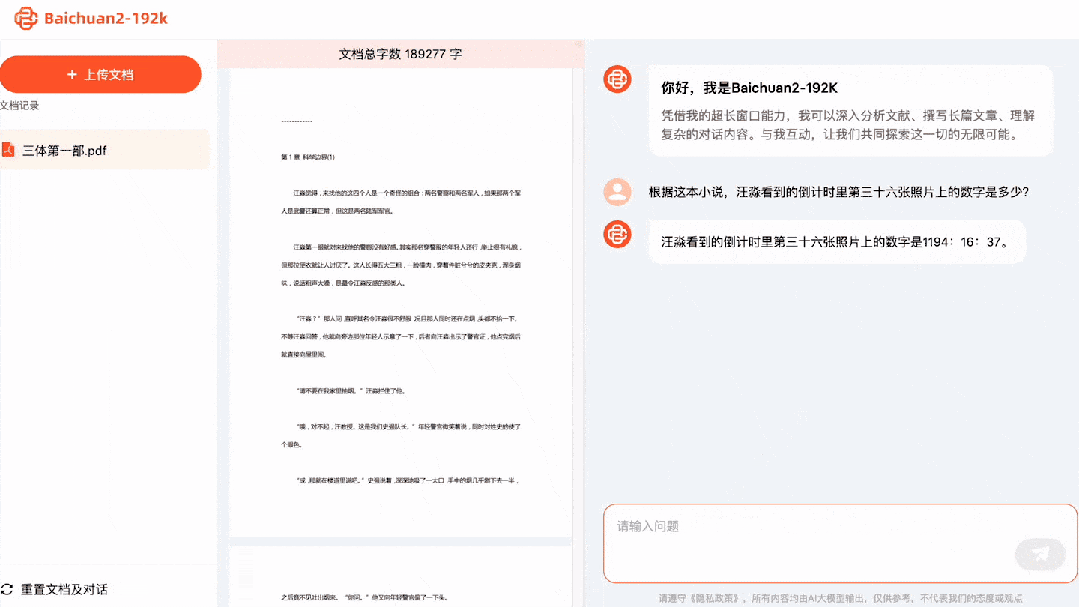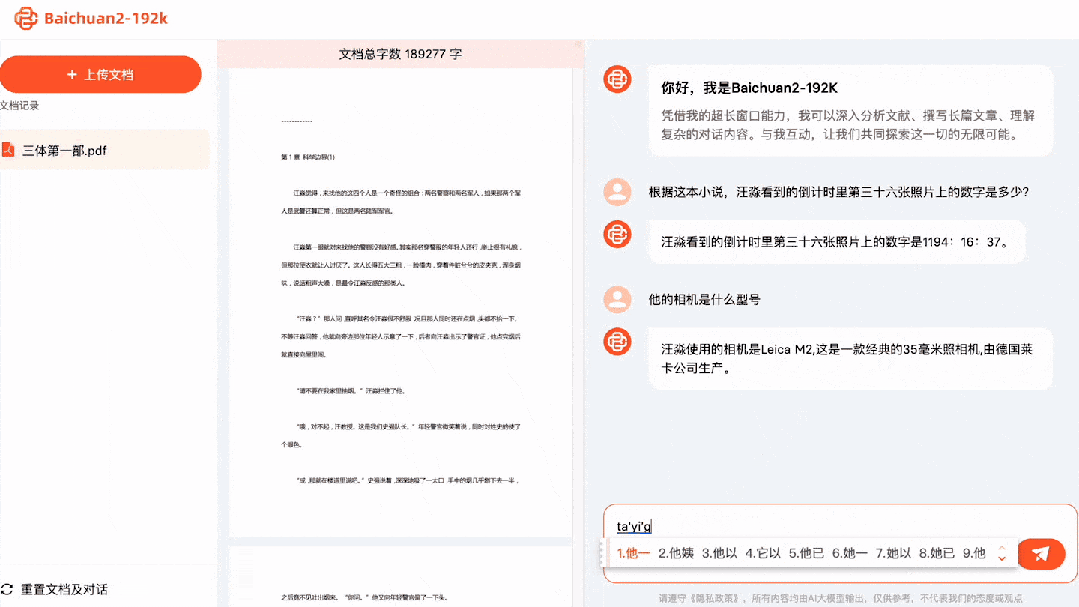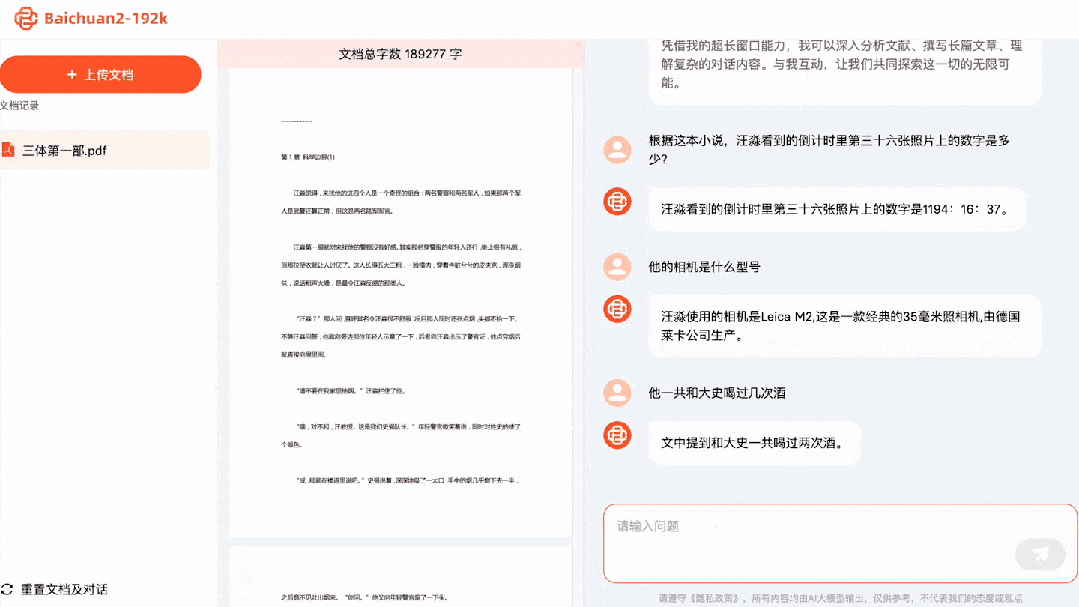
Hoďte na to první díl Three-Body Problem (Once Upon a Time on Earth), Baichuan2-192K to chvíli žvýkal a hned pochopil celý příběh.
Jaké je číslo na 36. fotce v odpočítávání, které viděl Wang Miao? Odpověď: 1194:16:37. Jaký model fotoaparátu používá? Odpověď: Leica M2. Kolikrát spolu on a Da Shi pili? Odpověď: Dvakrát.
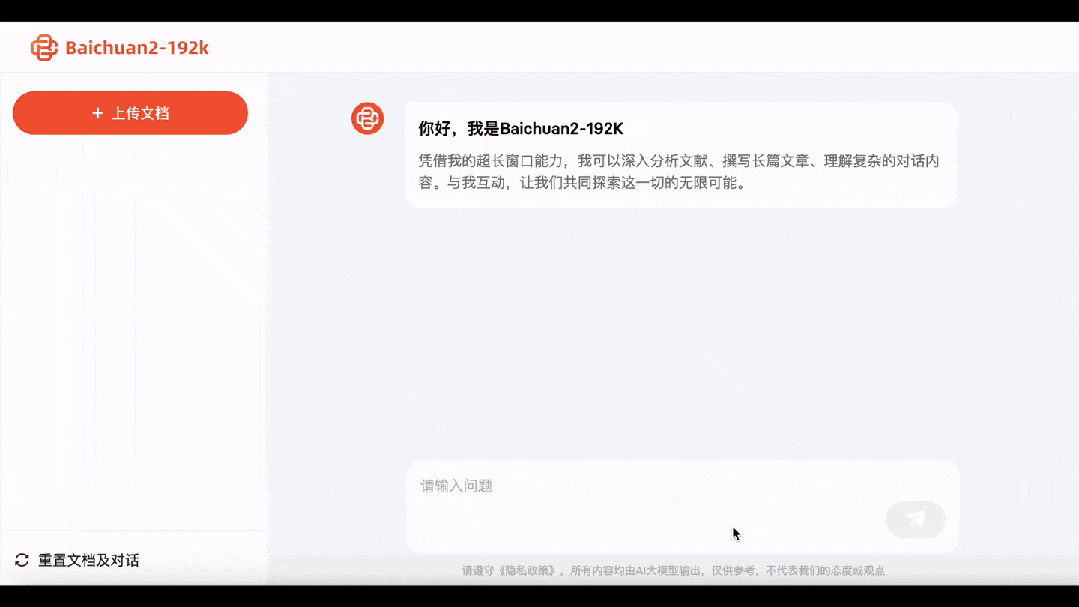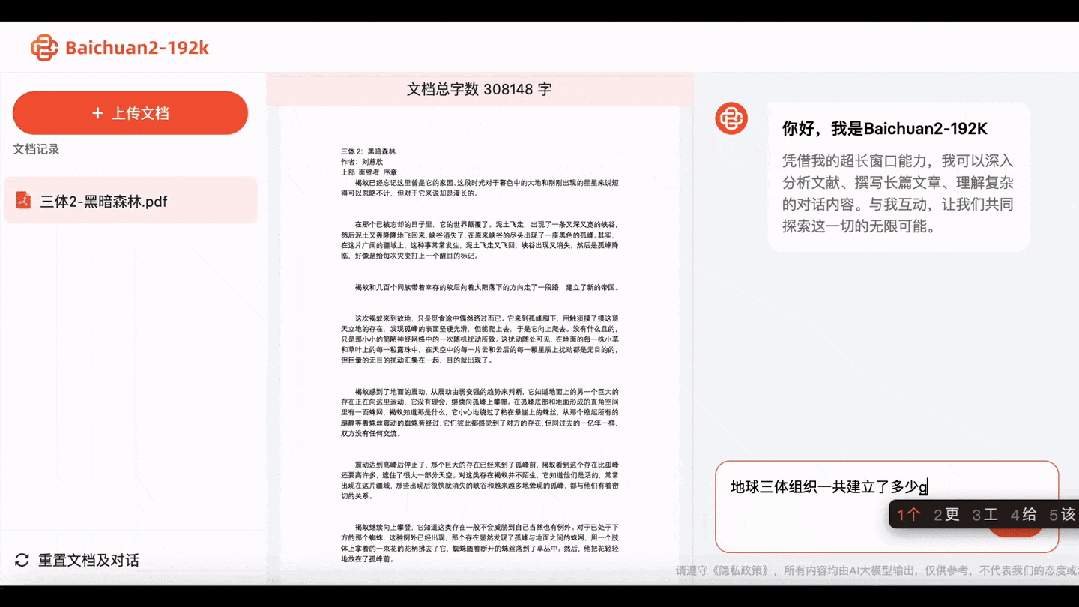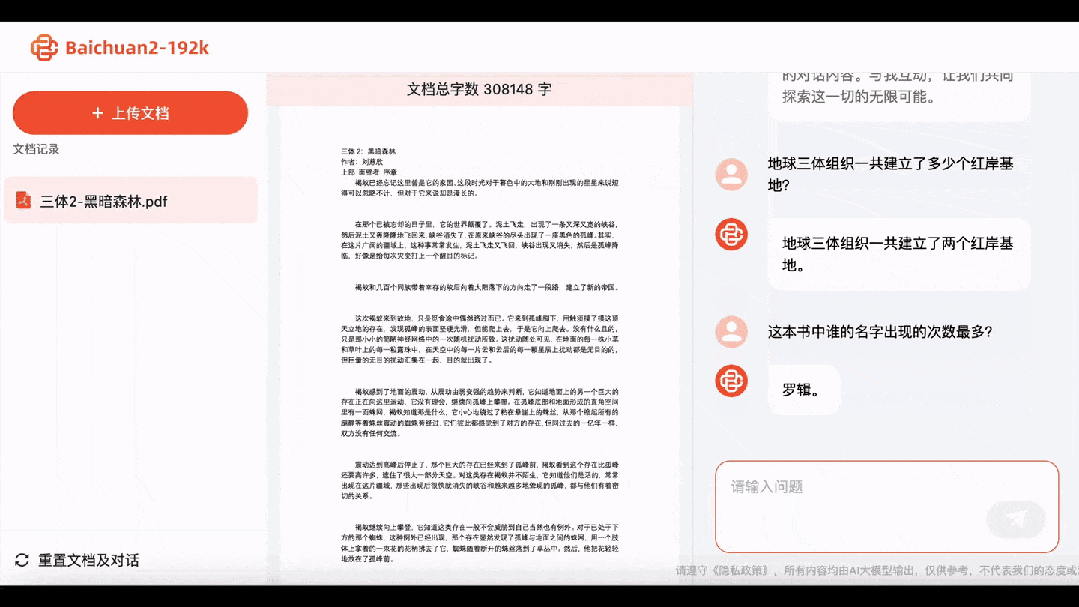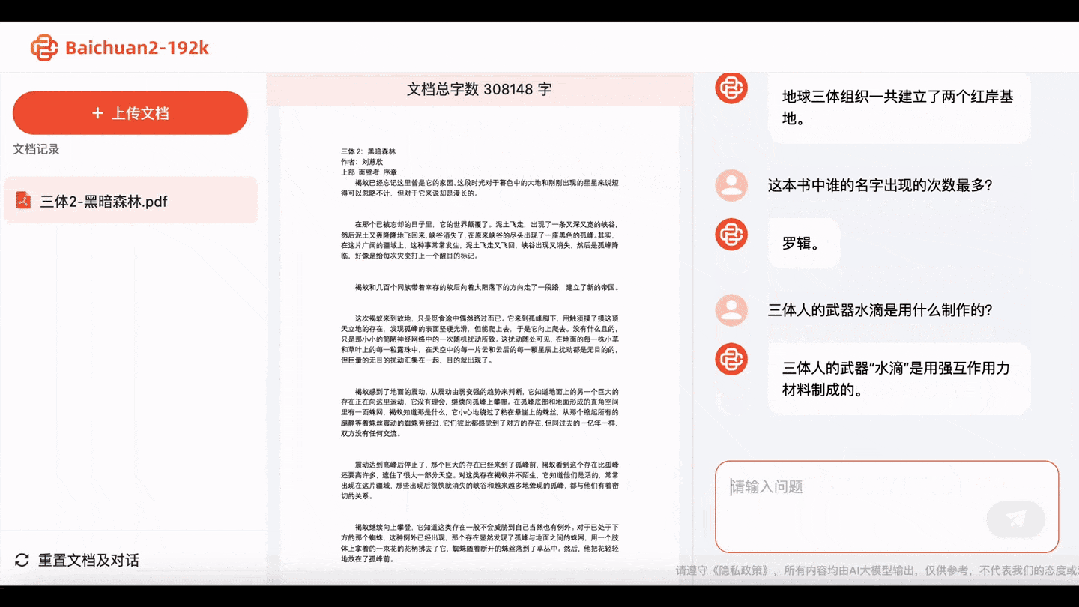
Při pohledu na druhou část (Temný les) Baichuan2-192K nejen okamžitě odpověděl, že Earth Trisolaran Organization zřídila dvě základny Red Bank, ale také, že „kapky vody“ jsou vyrobeny ze silných interakčních materiálů.
Baichuan2-192K byl navíc schopen odpovědět na nepopulární otázky, na které by možná nebyl schopen odpovědět ani „učenec třítělových problémů úrovně 10“.
Čí jméno se objevuje nejčastěji? Odpověď: Luo Ji.
Dá se říci, že když se kontextové okno rozšíří na 350 000 slov, zážitek z používání velkého modelu jako by náhle otevřel nový svět!
Nejdelší kontext na světě, před Claudem 2 ve všech aspektech
Co by se mohlo zaseknout na velkém modelu?
Vezměte si ChatGPT jako příklad Přestože jsou jeho schopnosti úžasné, tento „univerzální“ model má nevyhnutelné omezení – podporuje pouze maximálně 32K tokenů (25 000 čínských znaků) v kontextu. Profese, jako jsou právníci a analytici, potřebují většinu času zpracovávat texty mnohem déle.

Větší kontextové okno umožňuje modelu získat bohatší sémantické informace ze vstupu a dokonce přímo provádět odpovědi na otázky a zpracování informací na základě porozumění fulltextu.
Díky tomu může model nejen lépe zachytit relevanci kontextu a odstranit nejednoznačnost, ale také přesněji generovat obsah, zmírnit problém „iluze“ a zlepšit výkon. Navíc s podporou dlouhého kontextu může být hluboce integrován s více vertikálními scénami, aby skutečně hrál roli v lidské práci, životě a studiu.
Jednorožec Anthropic ze Silicon Valley nedávno získal investici 4 miliardy od Amazonu a 2 miliardy od Googlu. Schopnost získat přízeň těchto dvou obrů samozřejmě nesouvisí s Claudovým vedoucím postavením v technologii schopností s dlouhým kontextem.
Tentokrát model velkého okna Baichuan-192K vydaný společností Baichuan Intelligence daleko přesahuje Claude 2-100K, pokud jde o délku kontextového okna, a také funguje dobře ve více dimenzích, jako je kvalita generování textu, porozumění kontextu a otázka a odpověď. schopnostmi dosáhl celkového náskoku.
10 autoritativních recenzí, vítězných 7 SOTA
LongEval je seznam hodnocení modelů dlouhých oken vydaný Kalifornskou univerzitou v Berkeley a dalšími univerzitami. Měří především schopnost modelu zapamatovat si a porozumět obsahu dlouhého okna.
Pokud jde o porozumění kontextu, Baichuan2-192K je výrazně napřed před ostatními modely na LongEval, autoritativním seznamu hodnocení porozumění textu v dlouhém okně, a stále si může udržet velmi silný výkon i poté, co délka okna přesáhne 100 kB.
Naproti tomu celkový efekt Claude 2 velmi vážně klesá, když délka okna přesáhne 80K.
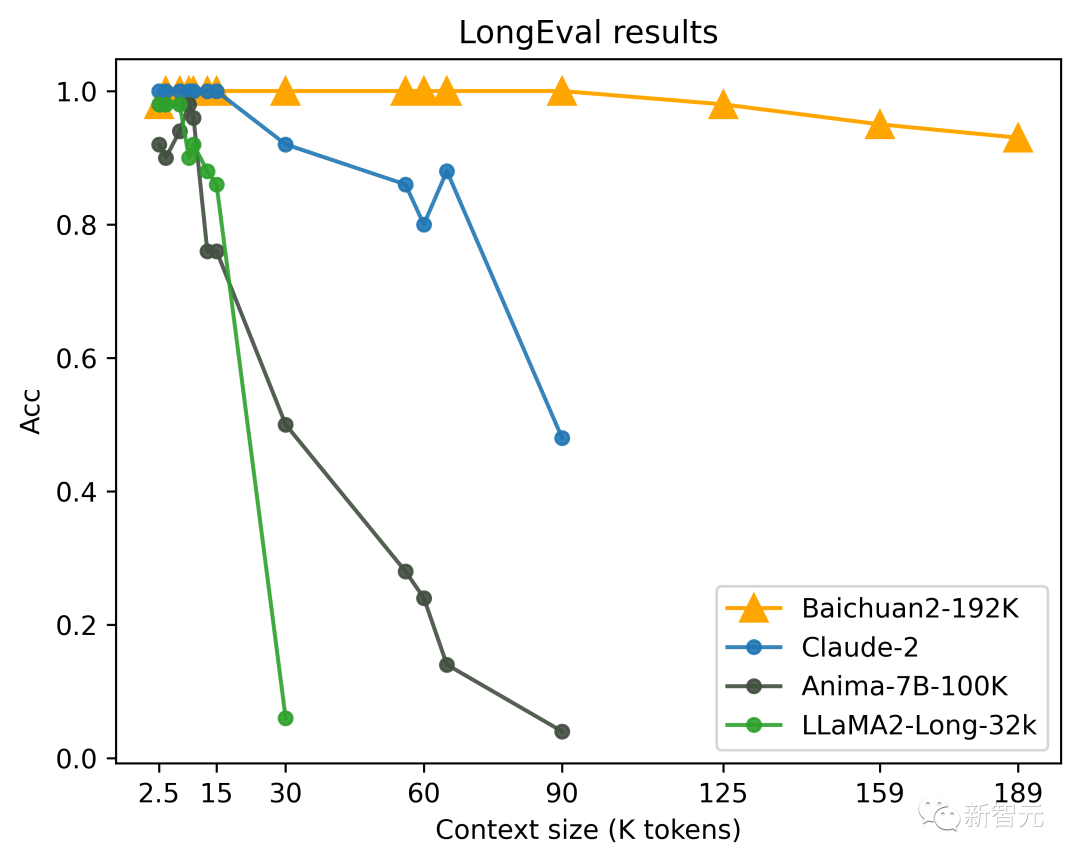
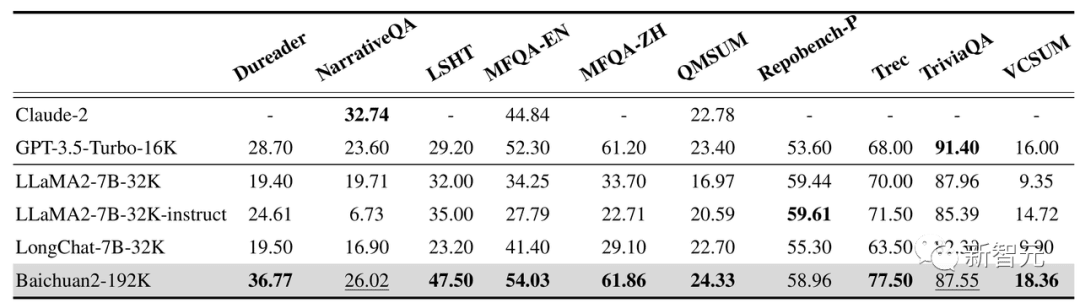
Kromě toho si Baichuan2-192K vedl stejně dobře na 10 čínských a anglických dlouhých textových otázkách a odpovědích a sadách hodnocení abstraktů, včetně Dureader, NarrativeQA, LSHT a TriviaQA.
Mezi nimi 7 dosáhlo SOTA a jejich výkon výrazně převyšuje ostatní modely s dlouhými okny.
Z hlediska kvality generování textu je nepřehlednost velmi důležitým kritériem.
Jednoduše lze pochopit, že když jsou jako testovací sada použity vysoce kvalitní dokumenty, které odpovídají lidským přirozeným jazykovým zvyklostem, čím vyšší je pravděpodobnost, že model vygeneruje text v testovací sadě, tím menší bude záměna modelu a tím lépe model bude.
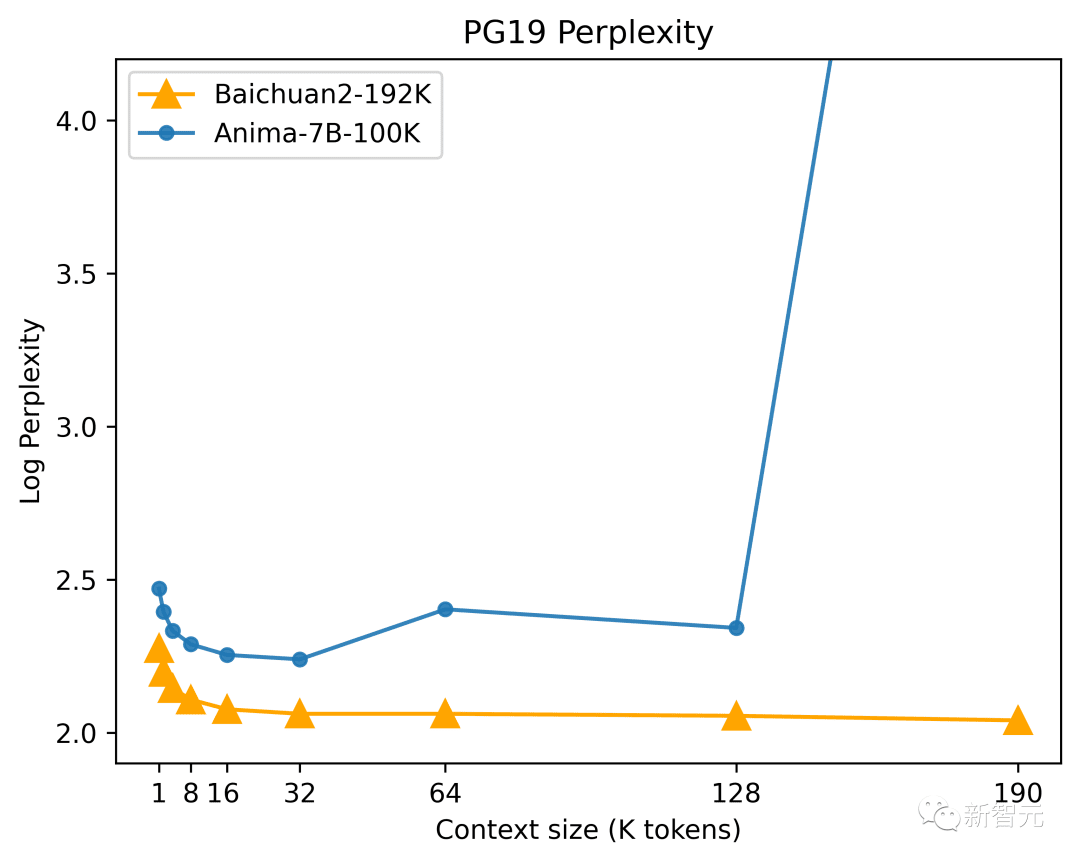
Podle výsledků testů "Language Modeling Benchmark Dataset PG-19" vydané DeepMind je zmatenost Baichuan2-192K v počáteční fázi vynikající a jak se délka okna rozšiřuje, možnosti modelování sekvencí Baichuan2-192K pokračují. zvýšit .
 Inženýrské algoritmy jsou společně optimalizovány tak, aby současně zlepšily délkový výkon.
Inženýrské algoritmy jsou společně optimalizovány tak, aby současně zlepšily délkový výkon.
Ačkoli dlouhý kontext může efektivně zlepšit výkon modelu, ultra dlouhá okna také znamenají potřebu silnějšího výpočetního výkonu a větší video paměti.
V současnosti jsou běžnou praxí v oboru posuvná okna, downsampling, redukce modelu atd.
Tyto metody však v různé míře obětují výkon ostatních aspektů modelu.
Aby se tento problém vyřešil, Baichuan2-192K dosahuje rovnováhy mezi délkou okna a výkonem modelu prostřednictvím extrémní optimalizace algoritmu a inženýrství a dosahuje současného zlepšení délky okna a výkonu modelu.
Za prvé, pokud jde o algoritmy, Baichuan Intelligent navrhl extrapolační schéma pro kódování dynamické polohy RoPE a ALiBi - může provádět různé stupně dynamické interpolace masky pozornosti na kódování polohy ALiBi různých délek, přičemž je zajištěna schopnost modelu je vylepšeno modelování závislostí dlouhé sekvence.
Za druhé, pokud jde o inženýrství, Baichuan Intelligence integrovala téměř všechny pokročilé optimalizační technologie na trhu, včetně paralelismu tenzoru, paralelismu potrubí, sekvenčního paralelismu, přepočítávání a odlehčení, na základě nezávisle vyvinutého distribuovaného tréninkového rámce, a vytvořila jedinečnou komplexní sadu 4D paralelně distribuovaných řešení - dokáže automaticky najít nejvhodnější distribuovanou strategii založenou na konkrétních podmínkách zatížení modelu, což výrazně snižuje využití paměti během tréninku dlouhých oken a procesů inference.
Oficiálně zahájena uzavřená beta, uvolněna zkušenost z první ruky
Nyní Baichuan2-192K oficiálně zahájil interní testování!
Hlavní partneři Baichuan Intelligence integrovali Baichuan2-192K do svých vlastních aplikací a podniků prostřednictvím volání API Finanční média, právní firmy a další instituce nyní dosáhly spolupráce s Baichuan Intelligence.
Lze si představit, že vzhledem k tomu, že přední světové schopnosti dlouhého kontextu Baichuan2-192K jsou aplikovány na konkrétní scénáře, jako jsou média, finance a právo, nepochybně to otevře širší prostor pro implementaci velkých modelů.
Prostřednictvím API se Baichuan2-192K může efektivně integrovat do více vertikálních scén a hluboce se s nimi integrovat.
Dokumenty s obrovským obsahem se v minulosti často stávaly horou, kterou jsme při práci a studiu těžko překonávali.

S Baichuan2-192K lze zpracovat a analyzovat stovky stran materiálu najednou a extrahovat a analyzovat klíčové informace.
Ať už se jedná o dlouhé shrnutí/recenze dokumentů, psaní dlouhých článků nebo zpráv nebo komplexní pomoc s programováním, Baichuan2-192K vám poskytne obrovskou pomoc.
Správcem fondů může pomoci shrnout a interpretovat finanční výkazy a analyzovat rizika a příležitosti společnosti.
Právníkům může pomoci identifikovat rizika v různých právních dokumentech, kontrolovat smlouvy a právní dokumenty.
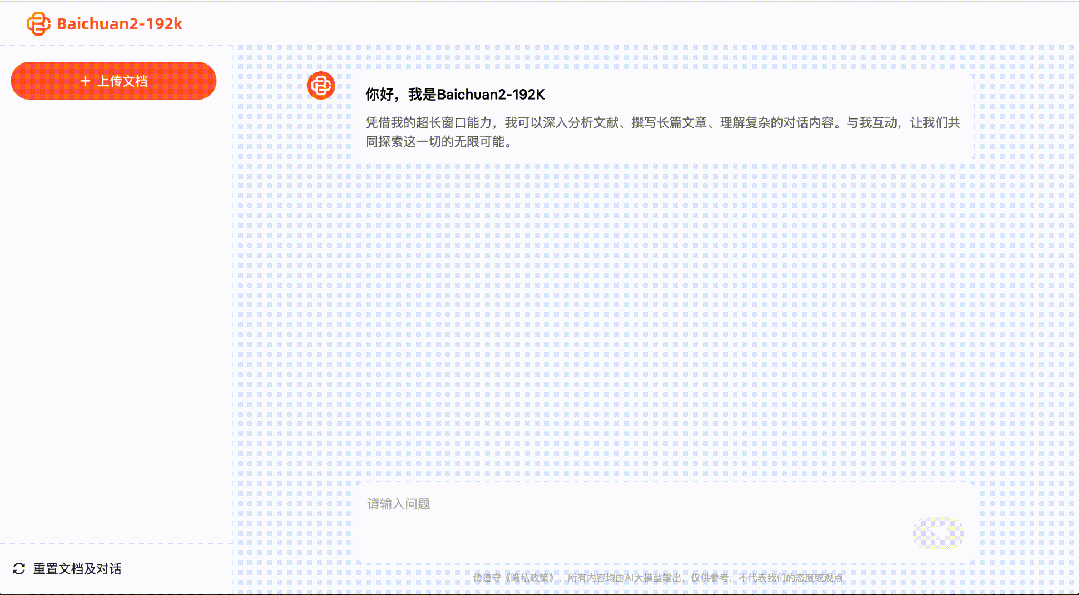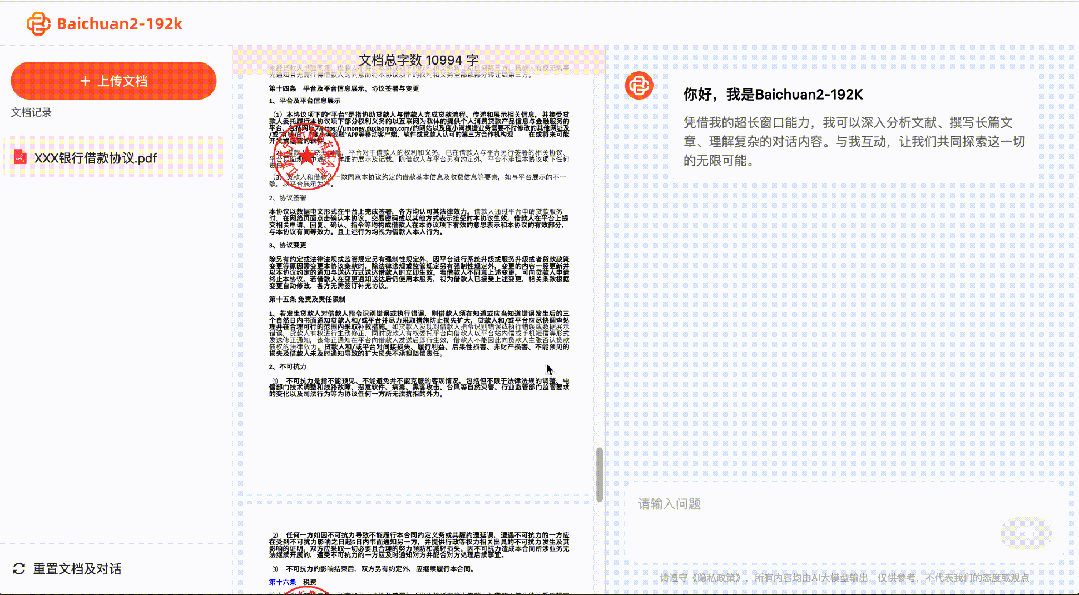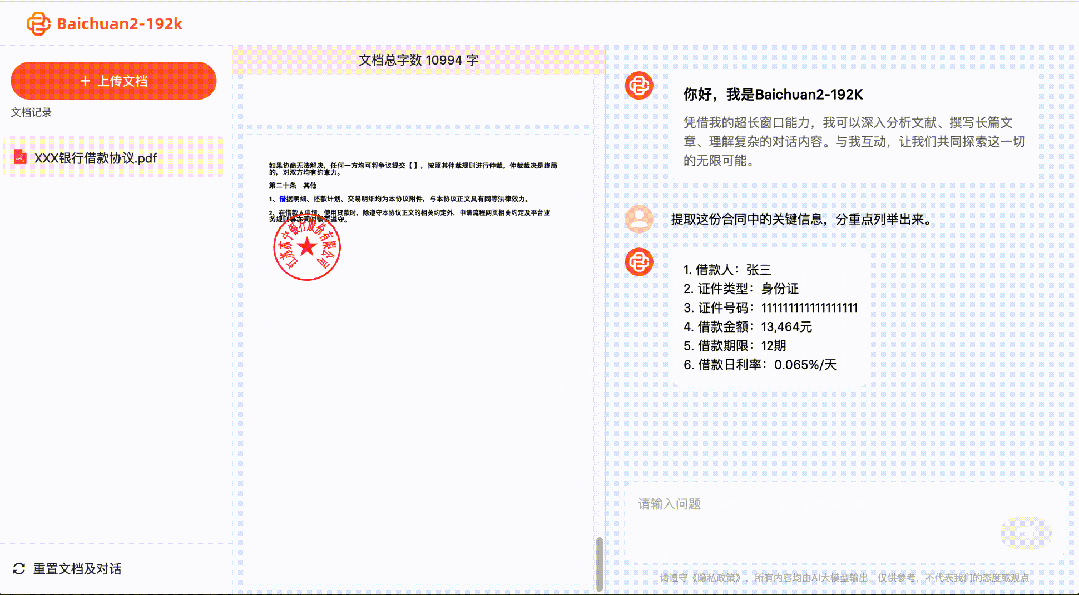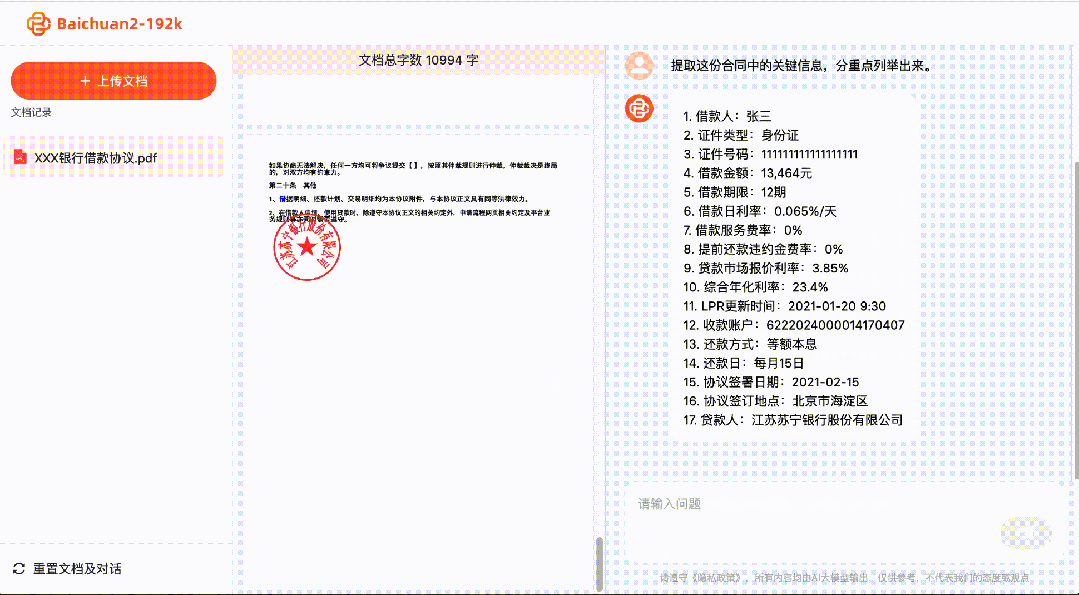
Vývojářům může pomoci přečíst stovky stránek vývojové dokumentace a odpovědět na technické otázky.
A většina vědeckých výzkumníků má nyní nástroj pro vědecký výzkum, který jim umožňuje rychle procházet velké množství článků a shrnout nejnovější špičkový vývoj.
Kromě toho mají delší kontexty ještě větší potenciál.
Agenti a multimodální aplikace jsou v současnosti žhavá témata v tomto odvětví. S většími modely s delšími kontextovými schopnostmi mohou lépe zpracovávat a chápat složité multimodální vstupy a dosáhnout lepšího učení přenosu.
Délka kontextu, bojiště pro vojenské stratégy
Dá se říci, že délka kontextového okna je jednou ze stěžejních technologií velkých modelů.
Nyní mnoho týmů začíná používat „dlouhý textový vstup“ jako výchozí bod pro vytvoření diferencované konkurenceschopnosti velkých základních modelů. Pokud počet parametrů určuje, jak složité výpočty může velký model provádět, délka kontextového okna určuje, kolik "paměti" velký model má.
Sam Altman jednou řekl, že jsme si mysleli, že chceme létající auta, ne 140/280 znaků, ale ve skutečnosti jsme chtěli 32 000 tokenů.

U nás i v zahraničí existují nekonečné výzkumy a produkty na rozšíření kontextového okna.
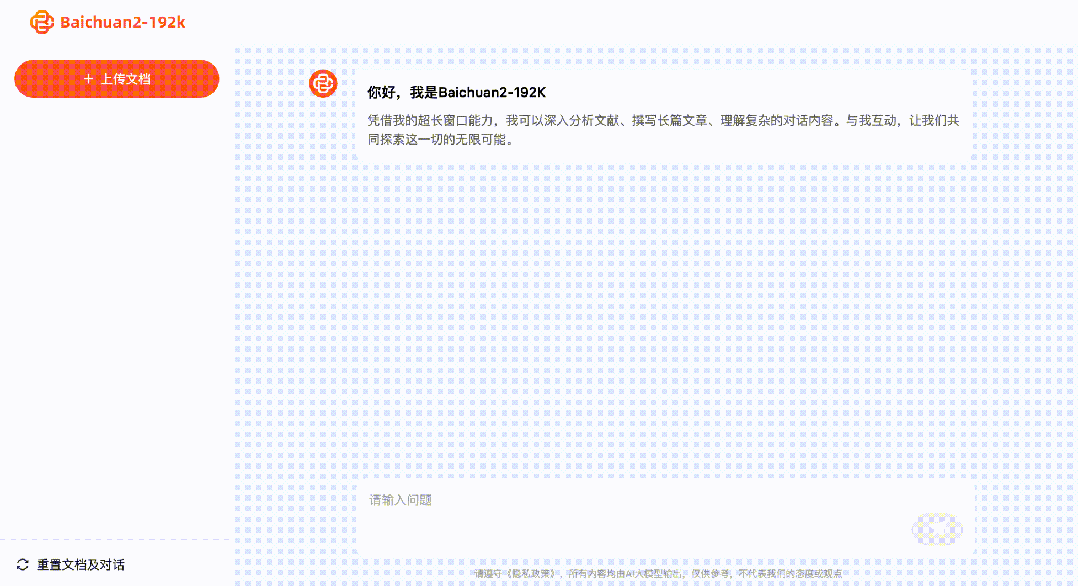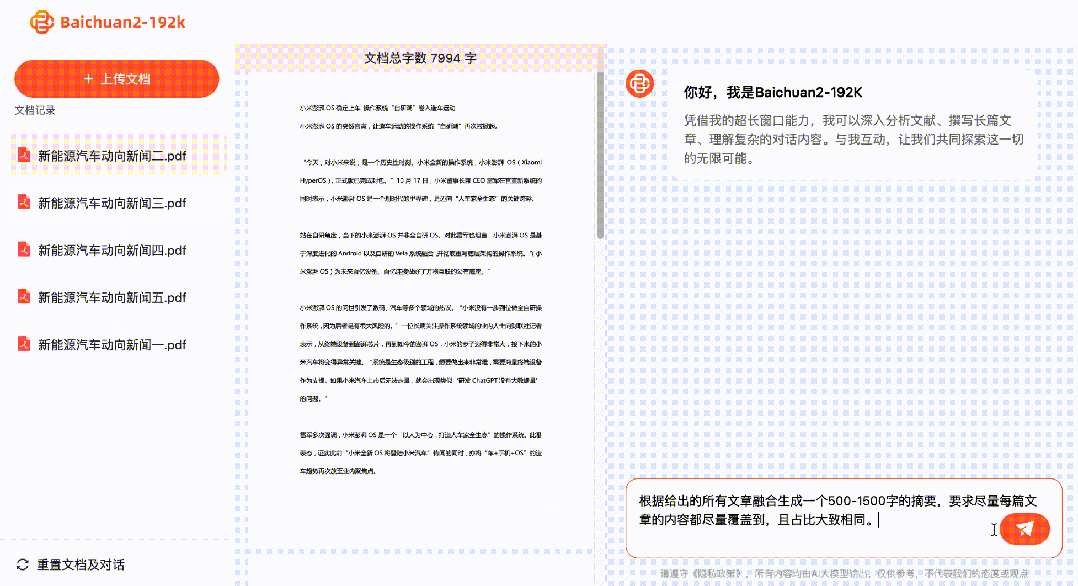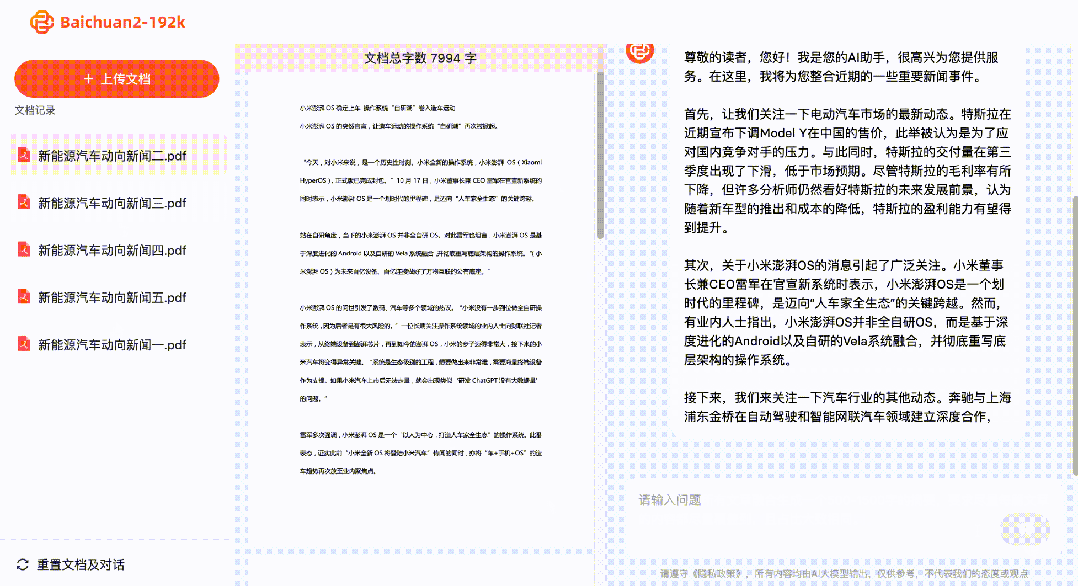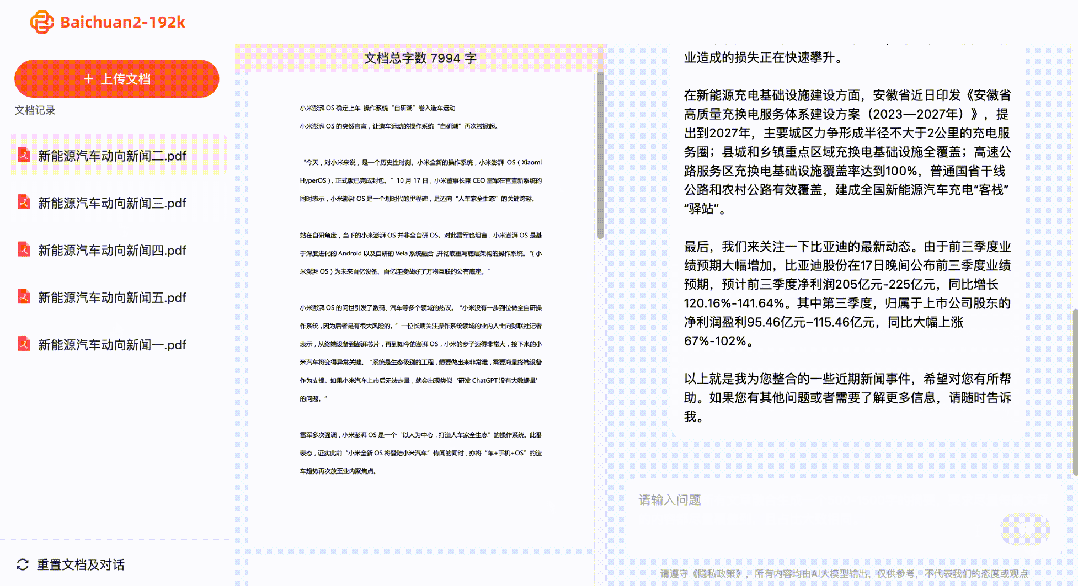
V květnu tohoto roku GPT-4, který má 32K kontext, vyvolal vzrušené diskuse.
Síťáci, kteří tuto verzi odemkli, v té době chválili GPT-4 32K jako nejlepšího produktového manažera na světě.
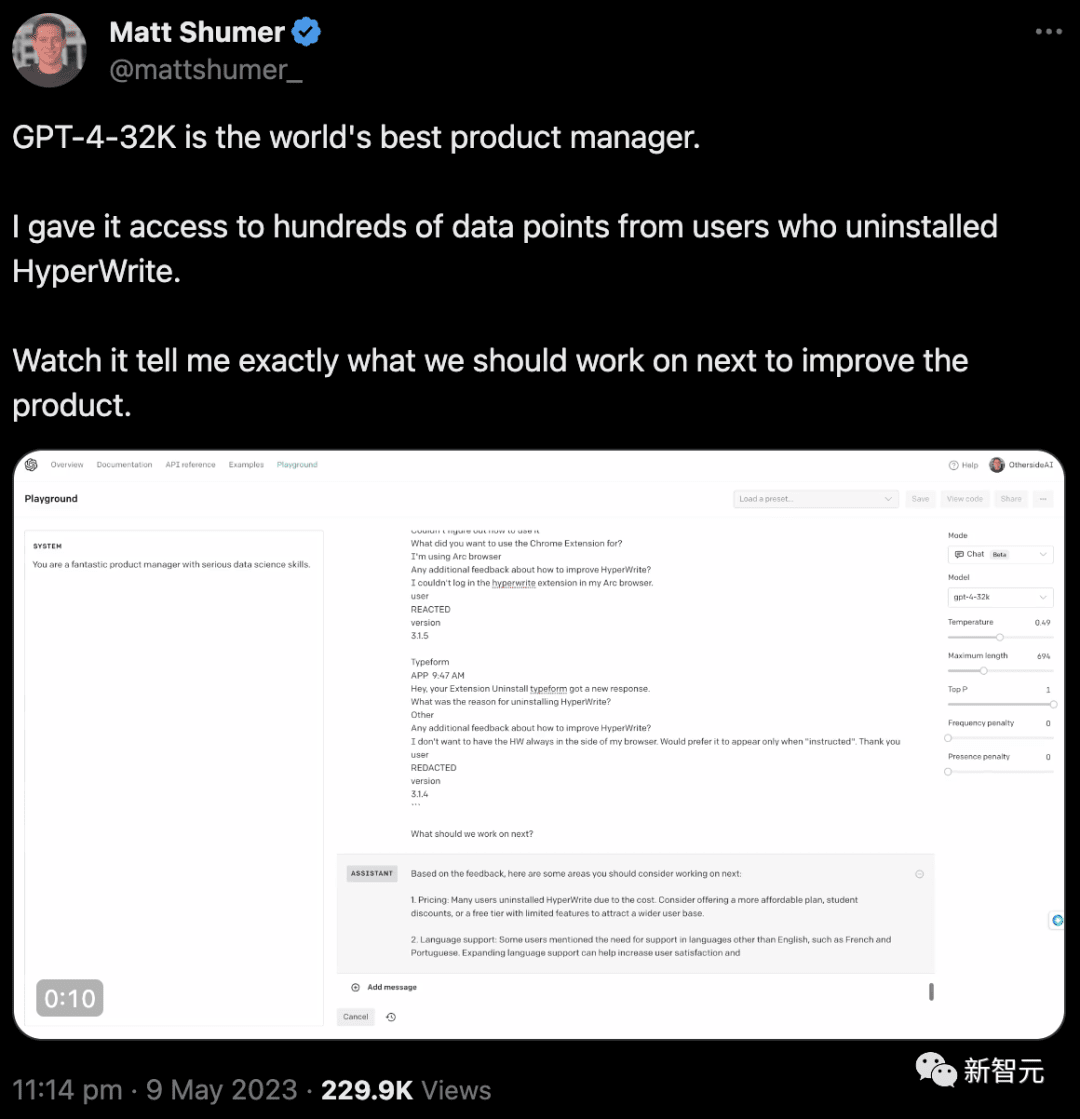
Startup Anthropic brzy oznámil, že Claude je již schopen podporovat délky kontextového tokenu 100 kB, což je asi 75 000 slov.
Jinými slovy, poté, co průměrnému člověku zabere asi 5 hodin, než přečte stejné množství obsahu, musí stále trávit více času trávením, zapamatováním a analýzou. Claudeovi to trvá méně než 1 minutu.
V komunitě s otevřeným zdrojovým kódem Meta také navrhla metodu, která může efektivně rozšířit kontextové možnosti, což umožňuje kontextovému oknu základního modelu dosáhnout 32 768 tokenů, a dosáhla pozoruhodného výkonu v různých úlohách zjišťování syntetického kontextu a jazykového modelování.
Výsledky ukazují, že model s parametry 70B dosáhl výkonu nad gpt-3.5-turbo-16k v různých úlohách s dlouhým kontextem.

Adresa papíru: https://arxiv.org/abs/2309.16039
Metoda LongLoRA navržená výzkumníky z Hongkongských čínských týmů a týmů MIT vyžaduje pouze dva řádky kódu a 8kartový stroj A100 k prodloužení délky textu modelu 7B na 100 000 tokenů a délky textu modelu 70B na 32 000 tokenů. .

Adresa papíru: https://arxiv.org/abs/2309.12307
Výzkumníci z DeepPavlov, AIRI a London Institute of Mathematical Sciences použili metodu Recurrent Memory Transformer (RMT) ke zvýšení efektivní délky kontextu BERT na „bezprecedentní 2 miliony tokenů“ a udržení vysoké přesnosti načítání paměti.
Ačkoli se však RMT může rozšířit do téměř nekonečných délek sekvence bez zvýšení spotřeby paměti, stále trpí problémem úbytku paměti v RNN a vyžaduje delší dobu odvození.

Adresa papíru: https://arxiv.org/abs/2304.11062
V současné době je délka kontextového okna LLM soustředěna především v rozmezí 4 000–100 000 tokenů a stále roste.
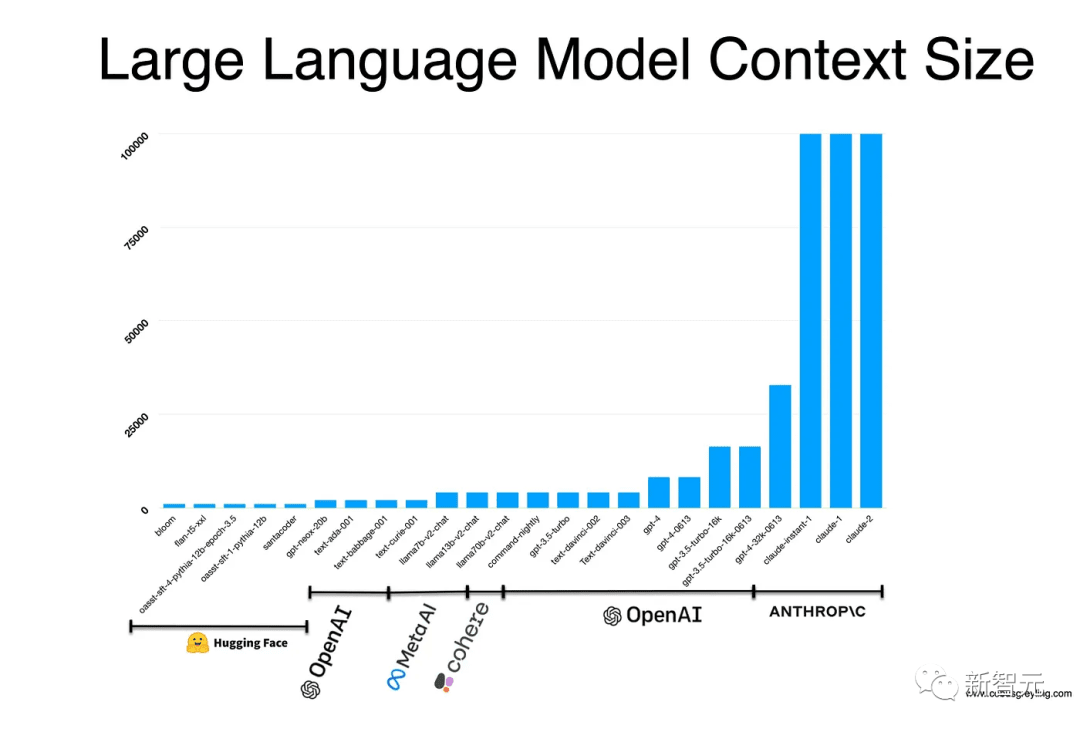
Prostřednictvím různých studií o kontextových oknech v průmyslu AI a akademické sféře je jeho význam pro LLM zřejmý.
Tuzemské velké modely tentokrát zahájily historický vrcholný okamžik nejdelšího kontextového okna.
Kontextové okno 192K, které překonalo průmyslový rekord, představuje nejen další průlom v technologii velkých modelů pro Baichuan Intelligent, hvězdnou společnost, ale také další milník ve vývoji velkých modelů. A to nevyhnutelně přinese nové kolo šoku do reformy formulářů na straně produktu.

Společnosti Baichuan Intelligent, která byla založena v dubnu 2023, trvalo pouhých 6 měsíců, než postupně vydala Baichuan-7B/13B, Baichuan2-7B/13B, čtyři open source velké modely, které jsou zdarma pro komerční použití, a také Baichuan-53B, Baichuan2- 53B dva. velké modely s uzavřeným zdrojem.
Vypočteno tímto způsobem je to v podstatě jedna aktualizace LLM za měsíc.
Nyní, s vydáním Baichuan2-192K, technologie velkých modelů s dlouhým kontextovým oknem také plně vstoupí do čínské éry!