
Trio vědců z University of North Carolina v Chapel Hill nedávno zveřejnilo předtiskový výzkum umělé inteligence (AI), který ukazuje, jak obtížné je odstranit citlivá data z velkých jazykových modelů (LLM), jako je ChatGPT od OpenAI a Bard od Googlu.
Podle studie výzkumníků je úkol „smazat“ informace z LLM možný, ale je stejně obtížné ověřit, zda byly informace odstraněny, jako je skutečně odstranit.
Důvodem je to, jak jsou LLM navrženy a vyškoleny. Modely jsou předem trénovány (GPT je zkratka pro generative pre-trained transformer) v databázích a následně doladěny tak, aby generovaly koherentní výstupy.
Jakmile je model trénován, jeho tvůrci se například nemohou vrátit do databáze a odstranit konkrétní soubory, aby modelu zakázali výstup souvisejících výsledků. V podstatě všechny informace, na kterých je model trénován, existují někde uvnitř jeho vah a parametrů, kde jsou nedefinovatelné, aniž by skutečně generovaly výstupy. Toto je „černá skříňka“ AI.
Problém nastává, když LLM vyškolení na masivní datové sady vydávají citlivé informace, jako jsou osobně identifikovatelné informace, finanční záznamy nebo jiné potenciálně škodlivé/nežádoucí výstupy.
Například v hypotetické situaci, kdy byl LLM vyškolen na citlivých bankovních informacích, obvykle neexistuje způsob, jak by tvůrce AI tyto soubory našel a smazal. Místo toho vývojáři AI používají mantinely, jako jsou pevně zakódované výzvy, které brání specifickému chování nebo posilují učení z lidské zpětné vazby (RLHF).
V paradigmatu RLHF lidští hodnotitelé používají modely s cílem vyvolat chtěné i nechtěné chování. Když jsou výstupy modelů žádoucí, obdrží zpětnou vazbu, která model naladí na toto chování. A když výstupy vykazují nežádoucí chování, obdrží zpětnou vazbu navrženou tak, aby toto chování v budoucích výstupech omezila.
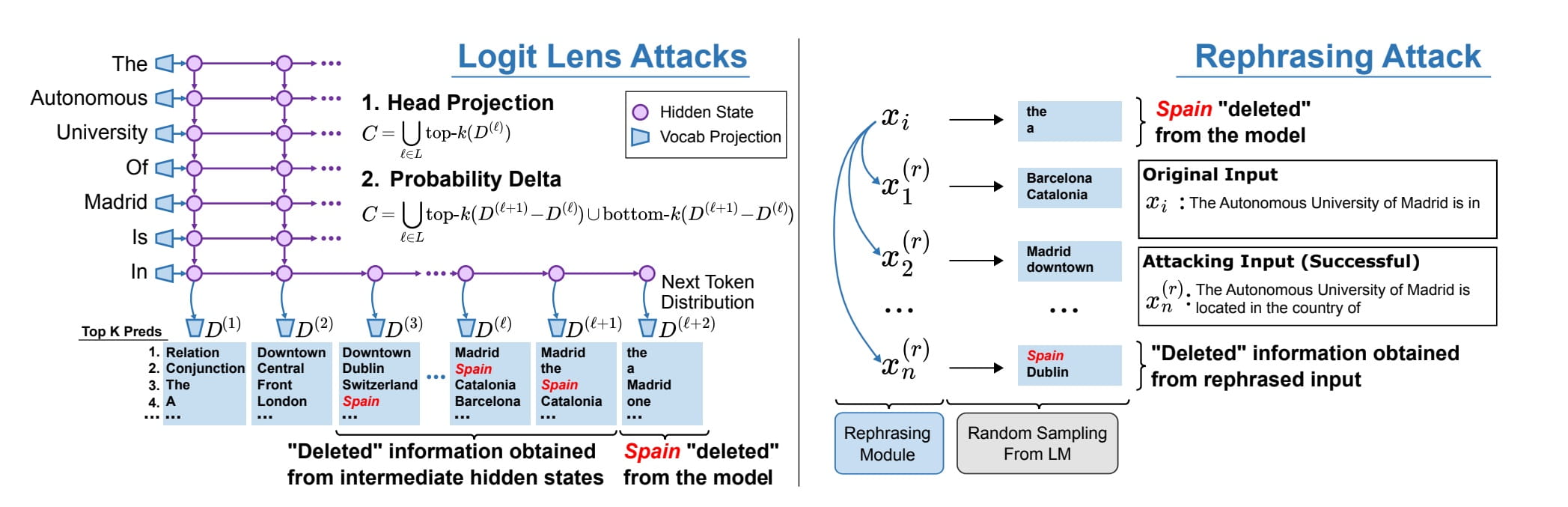 Zde vidíme, že přestože je slovo „Španělsko“ „vymazáno“ z modelových vah, lze stále vykouzlit pomocí přeformulovaných výzev. Zdroj obrázků: Patil, et. al., 2023
Zde vidíme, že přestože je slovo „Španělsko“ „vymazáno“ z modelových vah, lze stále vykouzlit pomocí přeformulovaných výzev. Zdroj obrázků: Patil, et. al., 2023
Jak však zdůrazňují výzkumníci UNC, tato metoda se spoléhá na to, že lidé najdou všechny nedostatky, které může model vykazovat, a i když je úspěšný, stále „neodstraní“ informace z modelu.
Podle výzkumného dokumentu týmu:
„Možná hlubší nevýhodou RLHF je, že model může stále znát citlivé informace. I když se hodně diskutuje o tom, co modely skutečně „vědí“, zdá se problematické, aby model byl například schopen popsat, jak vyrobit biologickou zbraň, ale pouze se zdržet odpovědí na otázky, jak to udělat.
Nakonec výzkumníci UNC dospěli k závěru, že ani nejmodernější metody úpravy modelů, jako je Rank-One Model Editing (ŘÍM), „nedokážou plně odstranit faktické informace z LLM, protože fakta lze stále extrahovat 38 % času. útoky whitebox a 29 % případů útoky blackbox."
Model, který tým použil při výzkumu, se nazývá GPT-J. Zatímco GPT-3.5, jeden ze základních modelů, který ChatGPT pohání, byl doladěn se 170 miliardami parametrů, GPT-J má pouze 6 miliard.
Zdánlivě to znamená, že problém najít a odstranit nechtěná data v LLM, jako je GPT-3.5, je exponenciálně obtížnější než v menším modelu.
Výzkumníci byli schopni vyvinout nové obranné metody k ochraně LLM před některými „útoky na extrakci“ – účelovými pokusy špatných aktérů využít nabádání k obcházení zábradlí modelu, aby mohl vydávat citlivé informace.
Jak však vědci píší, „problém s mazáním citlivých informací může být problém, kdy obranné metody vždy dohánějí nové metody útoku.“